




 SSD(Single Shot MultiBox Detector)是一种实时目标检测方法,采用多尺度特征图进行预测,避免了RPN,直接通过卷积预测边界框和类别。文章详细介绍了SSD的网络结构、Default Box、预测机制、匹配策略、损失函数和数据增强方法,揭示了其在实时性和精度上的优势,以及在小目标检测方面的局限性。
SSD(Single Shot MultiBox Detector)是一种实时目标检测方法,采用多尺度特征图进行预测,避免了RPN,直接通过卷积预测边界框和类别。文章详细介绍了SSD的网络结构、Default Box、预测机制、匹配策略、损失函数和数据增强方法,揭示了其在实时性和精度上的优势,以及在小目标检测方面的局限性。
SSD (Single Shot MultiBox Detector)
这是一个one-stage的多框预测的方法。
1 网络结构
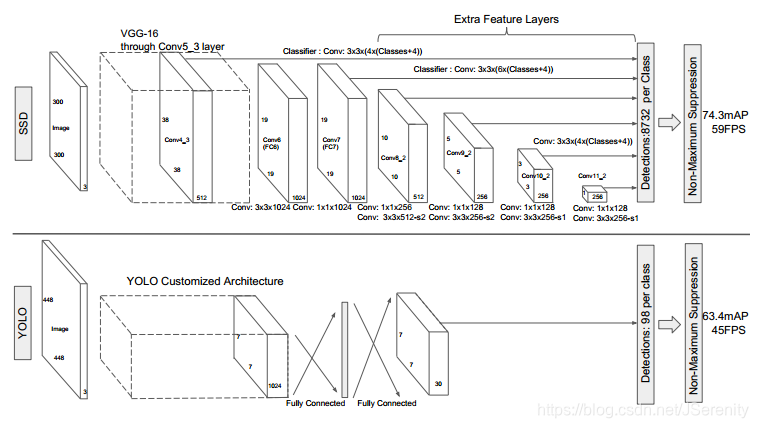
YOLO和Faster RCNN都是在检测的时候只用到了最高层的feature maps。
ssd提取了不同尺度的特征图来做预测。在多个feature maps上同时进行softmax分类和位置回归。
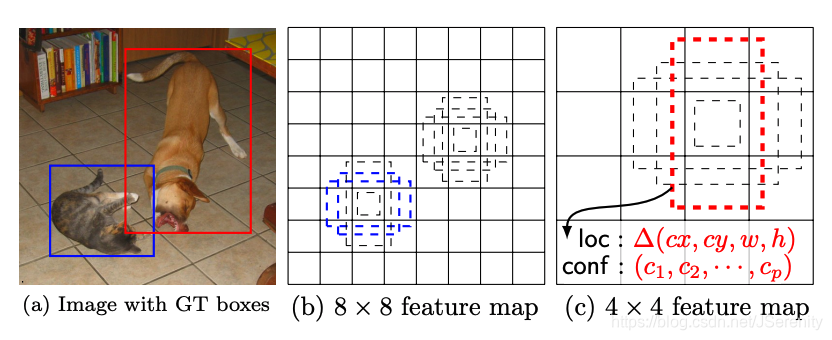
SSD采用了不同尺度和长宽比的先验框。大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。如图所示,在8x8的feature map中,蓝框可以匹配到较小的猫,而无法匹配到较大的狗。在4x4的feature map中,红框可以匹配到较大的狗,无法匹配到较小的猫。
相比yolo在最后使用全连接层做预测。ssd直接用CNN预测。
2 Default Box
先验框=预选框=Default Box=Prior Box=Anchor box
Default Box类似于Faster R-CNN的anchor box,为目标的预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。Default Box与anchor box不同的是,SSD为每一个不同尺度的feature map分别设置了预选框以更有效的检测到目标。
为了降低复杂度,SSD采用手动选择预选框的形状。SSD为每一个feature map分别设置了预选框。假设我们想要使用m个feature maps去预测。
Default Box的宽和高通过以下公式计算出:
w = s k ⋅ a r w = s_k \cdot \sqrt{a_r} w=sk⋅ar
h = s k a r h = \frac {s_k} {\sqrt{a_r}} h=arsk
a r a_r a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









