



 本文探讨Redis缓存中的常见问题,包括缓存击穿(热点数据过期)、缓存穿透(无效查询)和缓存雪崩(大量缓存同时失效),并提供针对性的解决方案,如使用互斥锁、布隆过滤器和多级缓存等策略来优化性能和减轻数据库压力。
本文探讨Redis缓存中的常见问题,包括缓存击穿(热点数据过期)、缓存穿透(无效查询)和缓存雪崩(大量缓存同时失效),并提供针对性的解决方案,如使用互斥锁、布隆过滤器和多级缓存等策略来优化性能和减轻数据库压力。
当谈到 Redis 缓存时,有几种常见的问题会出现,它们是缓存击穿、缓存穿透和缓存雪崩。
1. 缓存击穿 🔨:
缓存击穿是指在某个特定时间点,一个非常热门的、被大量请求访问的缓存键过期失效,导致所有的请求都需要直接访问后端数据库。这会给数据库造成巨大压力,并且可能导致系统崩溃。😱
解决方案:
- 在缓存键过期时使用互斥锁(Lock)机制,请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
- 针对热门数据设置较长的过期时间,避免频繁失效。
- 使用一致性哈希算法(Consistent Hashing),将请求分散到多个缓存节点。
2. 缓存穿透 🔍:
缓存穿透发生在请求查询一个不存在于缓存和数据库中的数据时。由于不存在的数据不会被缓存,每次请求都会直接访问数据库(恶意伪造假数据、大量请求)可能导致数据库负载过高。😫
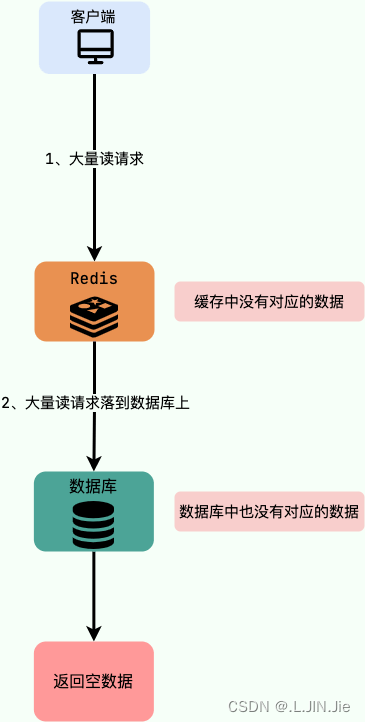
解决方案:
- 对于无效的查询结果,也将其缓存起来,但过期时间很短,以避免频繁查询。
- 添加布隆过滤器(Bloom Filter)等机制,快速判断查询的数据是否存在,并拦截无效请求。(将存在的数据缓存到过滤器中的,然后判断请求的数据是否存在过滤器中)
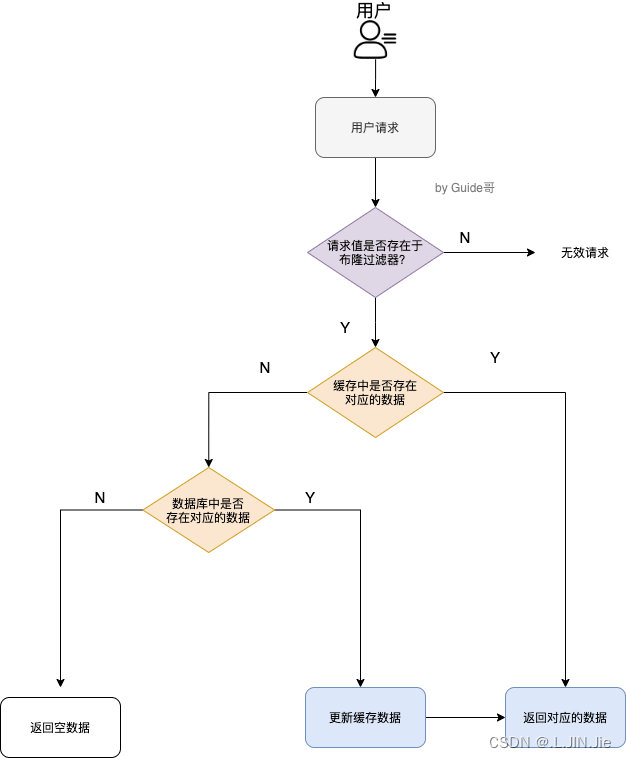
(🔍 布隆过滤器是一种快速且高效的数据结构,常用于判断一个元素是否可能存在于一个大型集合中。它通过使用位数组和多个哈希函数来进行快速查找和判断。布隆过滤器可以用于减少磁盘或内存访问,以及加速缓存查询等场景。它的主要特点是占用空间小且查询速度快,但可能存在一定的误判率。🔍)
3. 缓存雪崩 ❄️:
缓存雪崩指的是在某一个时间段内,大量的缓存键集中过期,导致所有的请求都直接访问后端数据库,造成数据库瞬间压力过大,甚至崩溃。🥶
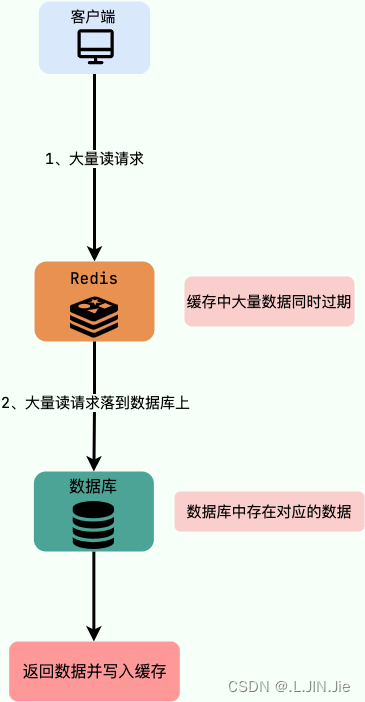
解决方案:
- 针对缓存过期时间设置随机的过期时间,避免大量缓存同时过期。
- 使用多级缓存架构,将请求分散到不同的缓存层,降低缓存失效的风险。
- 配置合理的主从复制和集群架构,提高缓存的可用性和容错性。
以上解决方案可以应对不同的情况,但具体的应用场景和需求可能需要采取定制化的解决方案。👍
缓存雪崩和缓存击穿有什么区别?
缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在与缓存中(通常是因为缓存中的那份数据已经过期)

















 4302
4302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









