







一、原始模型预测
1、模型下载
进github官网下载yolov11版本源码ultralytics/ultralytics: Ultralytics YOLO 🚀,也可直接点击我的资源连接进行源码下载【免费】YOLOv11源码及yolov11n.pt权重文件资源-优快云下载
2、环境配置
需要配置conda虚拟环境,以及torch等深度学习必备环境,网上也有很多教程,这里就不过多叙述(如果有朋友确实需要环境配置教程,可以在评论区留言,可以再补发一个完整的环境配置教程),当环境配置好后,进入终端环境输入pip install -r requirements.txt,安装必要的库。
3、模型预测
完成上述工作,我们就可以进行模型预测了,在主目录下构建文件夹weights,将权重文件放在里面,为了后续更方便的进行推理及参数调整,在主目录下构建predict.py,代码如下,可直接运行,会生成runs/detect/predict/bus.jpg文件。如果能进行预测,那么就说明环境配置基本没问题了,后面我们就可以训练自己的数据集了。
from ultralytics import YOLO
# 加载训练好的模型,改为自己的路径
model = YOLO('weights/yolo11n.pt') #修改为训练好的路径
source = 'ultralytics/assets/bus.jpg' #修改为自己的图片路径及文件名
# 运行推理,并附加参数
model.predict(source, save=True)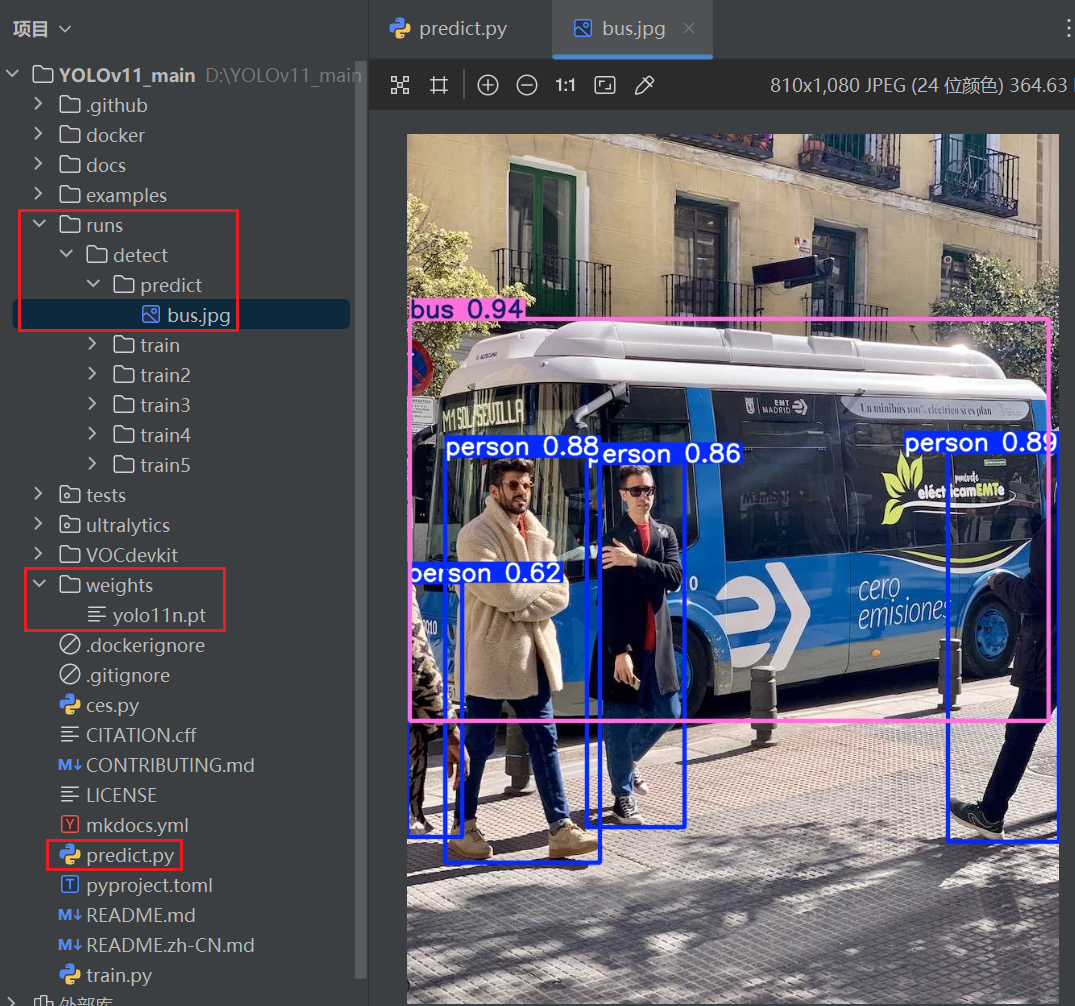
二、训练自己的数据集
1、数据集标注
这部分内容我在之前的博客就详细撰述了,主要采用labelimg进行标注,具体内容参考这篇使用LabelImg标注YOLO目标检测数据格式——LabelImg详细使用教程-优快云博客

2、数据集制作
然后使用如下脚本将数据集按8:1:1划分为训练集、验证集和测试集。
import os
import shutil
import random
def split_dataset(image_dir, label_dir, output_dir, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1, seed=42):
random.seed(seed)
# 获取所有图片文件
images = [f for f in os.listdir(image_dir) if f.endswith(".jpg")]
images.sort() # 保证顺序一致
# 打乱顺序
random.shuffle(images)
total = len(images)
train_end = int(total * train_ratio)
val_end = train_end + int(total * val_ratio)
splits = {
"train": images[:train_end],
"val": images[train_end:val_end],
"test": images[val_end:]
}
# 创建输出目录结构
for split in splits.keys():
os.makedirs(os.path.join(output_dir, split, "images"), exist_ok=True)
os.makedirs(os.path.join(output_dir, split, "labels"), exist_ok=True)
# 拷贝文件
for split, file_list in splits.items():
for img_file in file_list:
base_name = os.path.splitext(img_file)[0]
label_file = base_name + ".txt"
# 拷贝图片
src_img = os.path.join(image_dir, img_file)
dst_img = os.path.join(output_dir, split, "images", img_file)
shutil.copy(src_img, dst_img)
# 拷贝标签
src_label = os.path.join(label_dir, label_file)
if os.path.exists(src_label):
dst_label = os.path.join(output_dir, split, "labels", label_file)
shutil.copy(src_label, dst_label)
print(f"数据集划分完成!共 {total} 张图片")
for split, file_list in splits.items():
print(f"{split}: {len(file_list)} 张")
if __name__ == "__main__":
image_dir = "images" # 原始图片路径
label_dir = "annotation" # 原始标签路径
output_dir = "dataset" # 输出路径
split_dataset(image_dir, label_dir, output_dir)
参照如下格式创建文件夹在主目录中即可。
3、配置相关参数
3.1 数据集路径配置
在ultralytics/cfg/datasets文件夹中复制一个voc的yaml文件,也可以完全按照我的格式来进行。其中nc是对应的类别数。
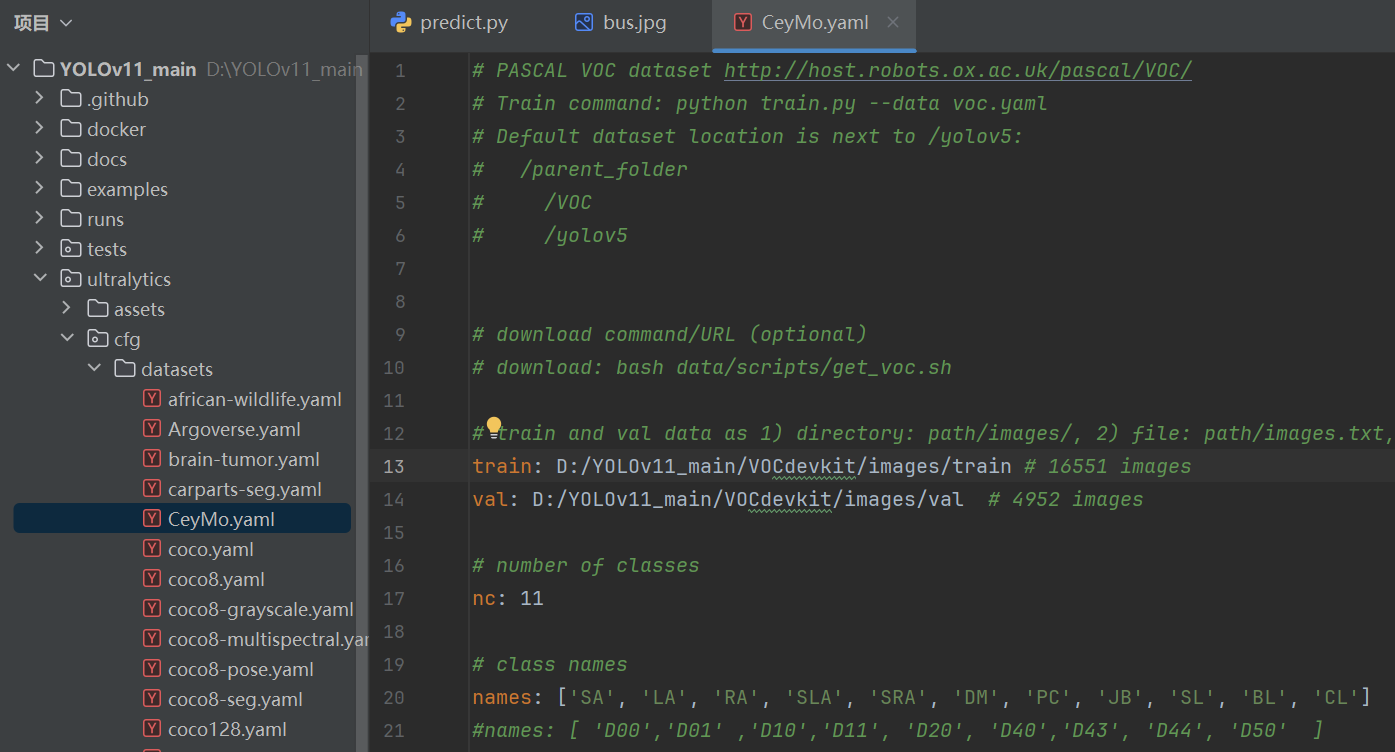
将ultralytics/cfg/models/11/yolo11n.yaml中的nc也对应修改。
3.2 训练参数配置
在主目录中创建train.py文件,对应代码如下:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11n.yaml')
model.load('weights/yolo11n.pt') #注释则不加载
results = model.train(
data='ultralytics/cfg/datasets/CeyMo.yaml', #数据集配置文件的路径
epochs=10, #训练轮次总数
batch=32, #批量大小,即单次输入多少图片训练
imgsz=640, #训练图像尺寸
workers=8, #加载数据的工作线程数
device= 0, #指定训练的计算设备,无nvidia显卡则改为 'cpu'
optimizer='SGD', #训练使用优化器,可选 auto,SGD,Adam,AdamW 等
amp= True, #True 或者 False, 解释为:自动混合精度(AMP) 训练
cache=False # True 在内存中缓存数据集图像,服务器推荐开启
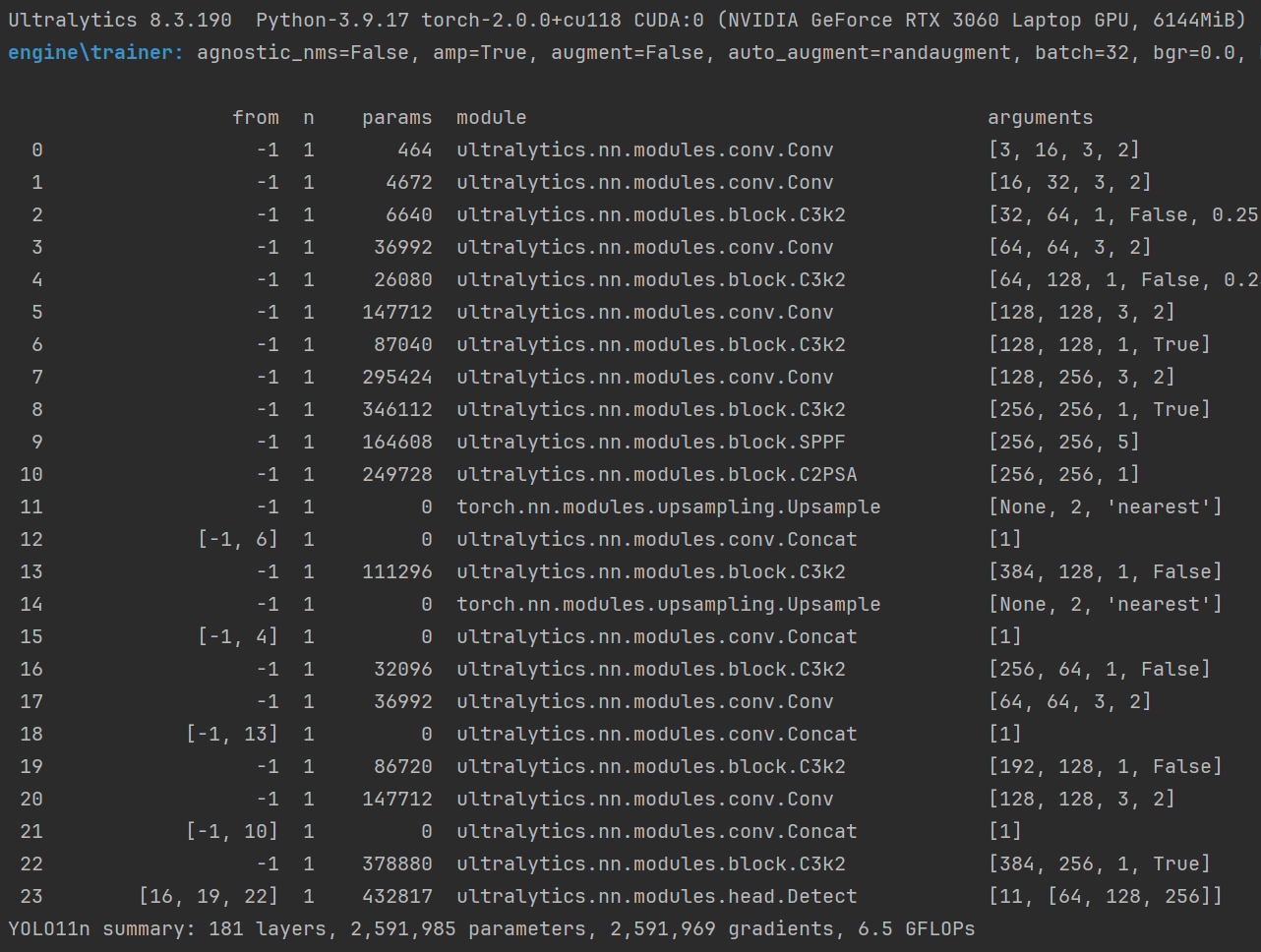
)成功运行:
3.3 结果分析
训练完成之后会在runs里面生成对应的文件,包括权重文件,mAP、召回率及精度等图像数据。
三、总结
通过本文,我们完成了从 环境配置 → 模型预测 → 数据集制作 → 参数配置 → 模型训练与结果分析 的完整流程,已经能够让你顺利跑通 YOLOv11 的训练。后续我会逐步更新 YOLOv11 改进思路、注意力机制、损失函数优化以及真实场景案例,带大家从入门走向进阶。
目前专栏正处于 早鸟阶段,欢迎大家提前订阅支持,享受更优惠的学习体验,也可以在评论区交流你遇到的问题。


















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











