




一、背景
YOLO 系列自 2016 年提出以来,一直是实时目标检测的代表模型。随着 YOLOv5/8 在工业界的广泛应用,学术界也在不断推动 YOLO 的发展。
-
YOLOv11:引入了 C3k2 模块和部分空间注意力(C2PSA),提升了小目标检测性能。
-
YOLOv12:将注意力机制全面整合进网络,利用区域注意力(Area Attention)和 Flash Attention,增强了全局与局部特征建模能力。
但问题仍然存在:
-
卷积运算只能在固定感受野内聚合局部信息。
-
注意力机制虽然扩大了感受野,但多是 两两相关性 建模,缺乏对 多对多高阶相关性 的表达能力。
因此,YOLOv13 引入 超图建模(Hypergraph Learning),让模型能捕获复杂场景下的潜在关系,提升鲁棒性和精度。
二、YOLOv13 的核心创新
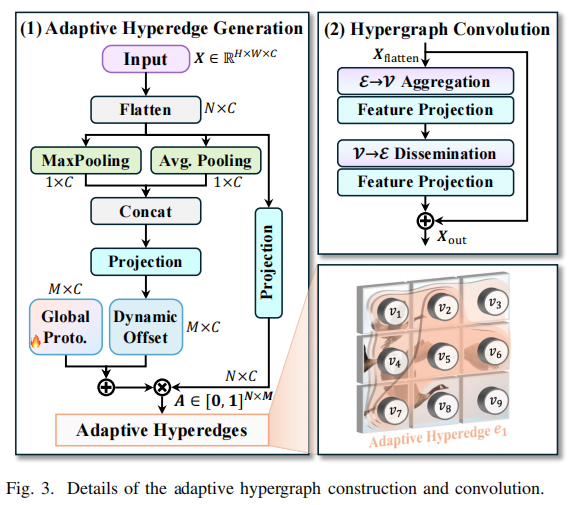
1. HyperACE(超图自适应相关增强)
-
将 特征点视为超图顶点,通过自适应超边生成模块,动态学习不同位置和尺度之间的相关性。
-
高阶相关性通过 超图卷积 聚合,而不是仅仅 pairwise 注意力。
-
包含三条分支:
-
高阶相关建模(C3AH 模块)
-
低阶局部特征建模(DS-C3k 模块)
-
Shortcut 保持原始特征
-
公式核心思想:
![]()
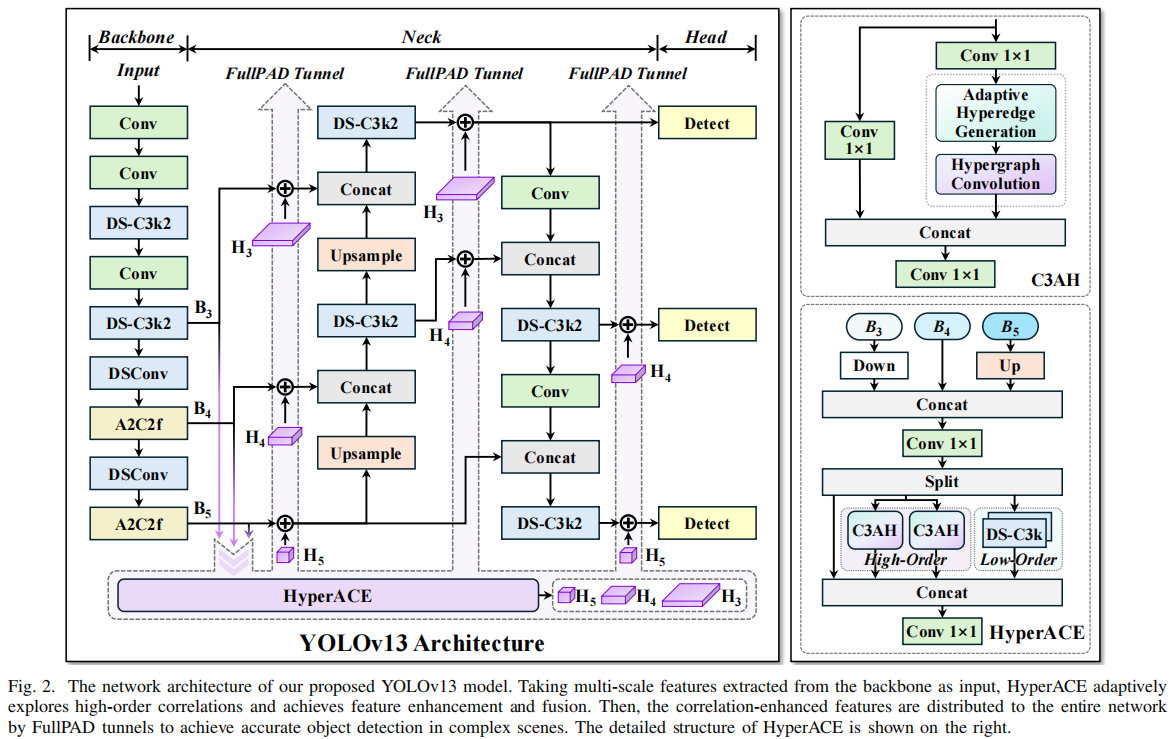
2. FullPAD(全流程特征聚合与分发)
-
不再是单一 Backbone → Neck → Head 的流动,而是通过隧道 把增强特征分发到多个阶段。
-
三条隧道:
-
Backbone → Neck
-
Neck 内部
-
Neck → Head
-
-
有效改善梯度传播,提升全局信息流动。
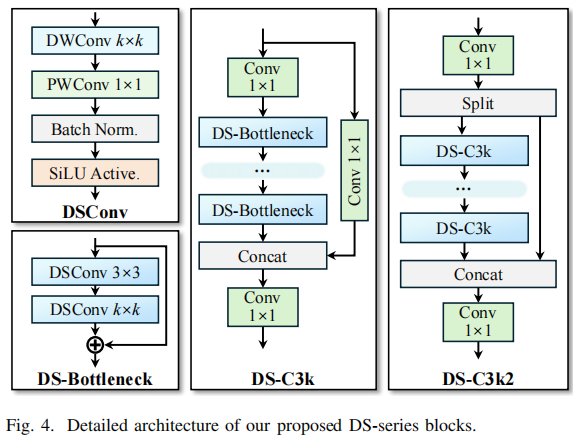
3. 轻量化设计:DS 系列模块
-
使用 深度可分离卷积 替换大卷积核。
-
设计了 DS-Bottleneck、DS-C3k、DS-C3k2 等结构。
-
在保证精度几乎不变的情况下:
-
参数量减少 ~30%
-
计算量减少 ~28%
-
三、实验结果
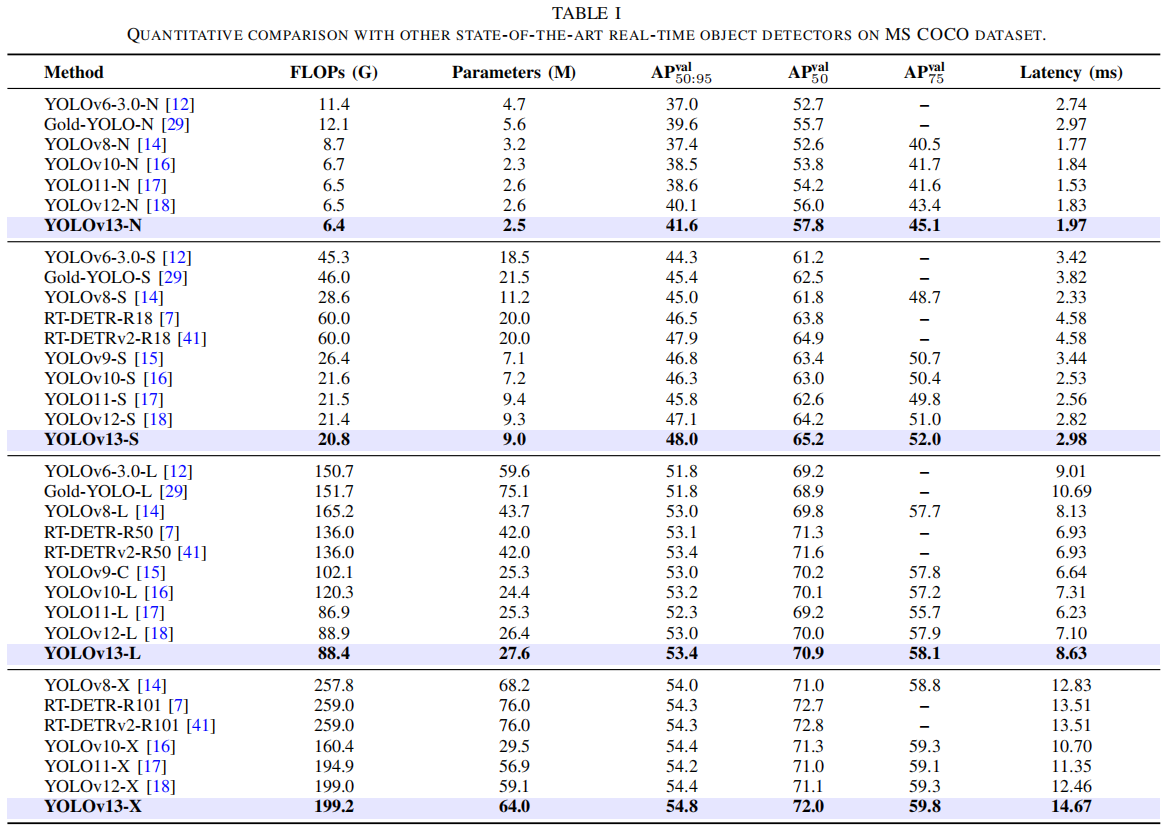
1. MS COCO 对比结果
以 Nano 版本为例:
-
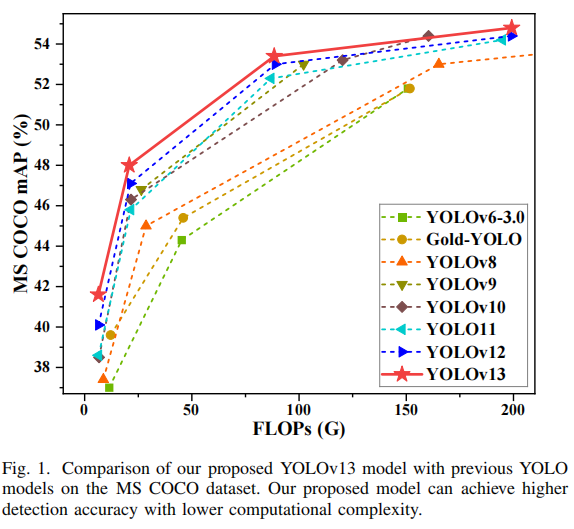
YOLOv11-N:38.6 mAP
-
YOLOv12-N:40.1 mAP
-
YOLOv13-N:41.6 mAP(+1.5% 提升,参数更少)
2. 可视化效果
YOLOv13 在复杂场景下表现更好:
-
检测被遮挡的小物体(如花瓶后的植物)。
-
识别细长物体(如运动员手中的球拍)。
-
避免误检背景(如阴影 vs 球拍)。

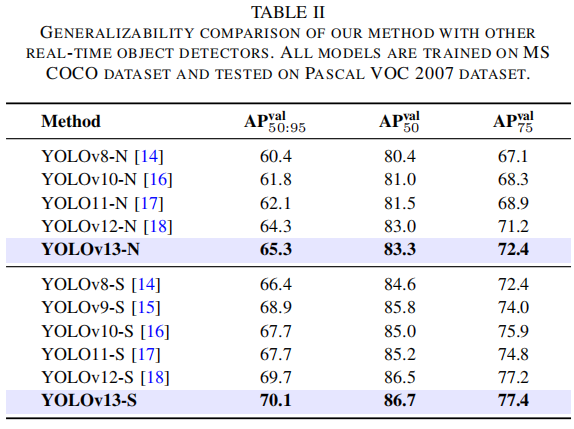
3. 跨域泛化能力
在 Pascal VOC 2007 数据集上:
-
YOLOv12-N:64.3% mAP
-
YOLOv13-N:65.3% mAP(+1% 提升)
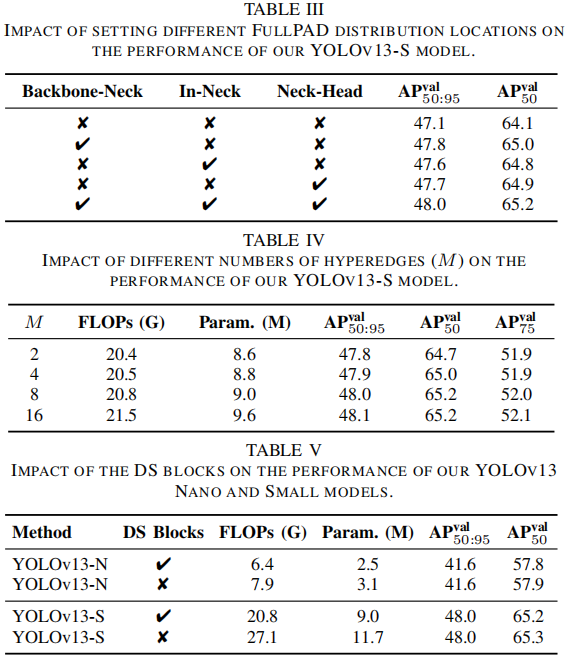
四、消融实验亮点
-
FullPAD 去掉后:AP↓0.9%,证明其必要性。
-
不同超边数量 M:过少会降低性能,过多则增加计算量。最佳选择 N=4, S=8, L=8, X=12。
-
DS 模块替换:减少参数与 FLOPs,同时性能几乎不降。
五、总结与展望
YOLOv13 的主要贡献:
-
HyperACE:首次将自适应超图引入 YOLO,高效建模全局高阶相关性。
-
FullPAD:全流程特征分发机制,改善梯度传播。
-
轻量化 DS 模块:兼顾速度与精度。
未来潜在方向:
-
视频检测:用超图建模时序相关性。
-
多模态任务:超图天然适合图像+文本的联合建模。
-
边缘部署:结合剪枝/蒸馏,进一步压缩。
近期在更新YOLOv11网络改进专栏YOLOv11模型优化改进_JH_vision的博客-优快云博客,后期也会同步更新YOLOv13的网络改进策略,感兴趣的朋友们可以关注留意!




















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











