



JAVA
String,StringBuffer,StringBuilder的区别
1、不可变性:String不可变,因为String内部维护的char数组用final修饰。其余两个可变。
2、线程安全:String由于有final,线程安全。StringBuffer方法由synchronized修饰,线程安全。StringBuilder不安全。
3、性能:对于多次字符串增删,String效率低,因为需要创建新对象。
接口和抽象类的区别
1、方法和变量:接口的方法默认为抽象方法,由public abstract修饰,变量为静态常量public static final。抽象类中的方法可以是抽象方法protected也可以是具体方法,变量可以是成员变量也可以是静态常量。
2、继承:类可以实现多个接口,但只能继承一个抽象类。
3、构造器:接口没有构造器,不能实例化。抽象类可以由构造器,子类实例化时调用父类构造器。
异常
1、父类为Throwable,分为Error和Exception。Error是严重问题,一般是JVM问题,比如内存耗尽OOM,栈资源耗尽,程序员处理不了。Exception是可被程序员处理的。
2、Exception:无论哪个异常,都是靠程序员的经验来判断代码是否会出现异常。分为运行时(Unchecked)异常和编译时(Checked)异常。编译时异常是编译器要求程序员在编译阶段必须处理的异常(IO,FileNotFind),因为编译器要求程序员考虑周到点,所以是checked;运行时异常是程序逻辑有问题才会出现的异常(数组越界),因为程序员肯定认为自己程序逻辑没问题,所以是unchecked。
java三大特征
1、封装:把数据和操作数据的方法封装到一个类中,同时提供一些可以被外界访问数据的方法。
2、继承:允许一个类继承现有类的属性和方法,以提高代码复用性。同时,子类还可以重写从父类继承来的属性和方法,还可添加新的方法。继承是多态的前提。
3、多态:同一声明类型的变量在执行同一方法时,可能会表现出多种行为。多态三大前提:子类继承父类;子类重写父类方法;声明类型为父类,实际类型为子类。
多态的理解
1、多态定义:略。
2、编译时多态(静态多态,早期绑定):方法重载,在编译时,编译器就能确定调用哪个方法。
3、运行时多态(动态多态,后期绑定):方法重写,在运行时,根据实际类型对象的方法来确定调用哪个方法。
重载和重写(方法名,参数类型个数顺序,返回类型,访问修饰符)
1、重载:同一类中,方法名相同,参数类型,个数,顺序不同。返回类型和访问修饰符无所谓。
2、重写:子类重写父类方法,方法名,参数类型个数顺序,返回类型相同。访问修饰符>=父类。
final关键字
1、final修饰变量:变量值不可变。引用数据类型的话,值是地址,地址不能变,但是地址里面的值可以变。
2、final修饰方法:方法不可被重写。
3、final修饰类:不可被继承。
==和equal区别
equal是个方法,object类的equal是比较地址值,想指定比较什么属性,需要重写类的equal方法。==比较的是字面量或者地址值。
java序列化
需要持久化java对象时使用的技术。将java对象以二进制或者其他格式保存到物理空间或者在网络中传输。双方根据相同的协议序列化和反序列化。
集合类有哪些?线程安全?
1、集合类:由Collection和Map接口衍生。Collection又分为List,Set,Queue三个子接口。所有集合类都是List,Set,Queue,Map的实现类。
2、Vector、HashTable,ConcurrentHashMap。Collection.synchronizedList等包装下集合。
Array和ArrayList有啥区别?
1、扩容:数组在创建时必须指定大小,不能改变,不能自动扩容。ArrayList是动态数组,可以改变,可以自动扩容。
2、泛型:数组可以存储任何类型的数据,不支持泛型。ArrayList只能储存对象,基本数据类型只能转包装类来存储,支持泛型。
3、集合的功能:ArrayList是List的实现类,由很多集合的功能方法使用。
ArrayList和LinkedList有什么区别?
1、ArrayList是动态数组,LinkedList是双向链表。
2、增删:ArrayList需要移动后面的数据,时间复杂度n,LinkedList不需要,时间复杂度1(但是找到增删的元素也需要遍历,时间n)。
3、查:ArrayList支持随机访问,LinkedList需要遍历。
4、ArrayList自动扩容:初始化容量为0,当添加第一个元素时,扩容为默认容量10。当再有新元素到达时,如果当前容量+1>数组最大容量,则扩容到当前容量的1.5倍,再调用Arrays.copyOf()返回个新数组地址给ArrayList。
HashMap
equals相同,hashcode相同,h相同,索引相同。
equals不同,hashcode相同,h相同,索引相同。
hashcode不同,h相同,索引相同。
h不同,索引不同。
也就是说,hashcode相同,h肯定相同;hashcode不同,h也可能相同。索引跟h绑定。
1、首先hashmap内部用个Entry<k,v>[]数组来储存键值对,Entry里包含key值,value值,key的hashcode()值(hashcode方法可以理解为必须把对象转化成数字,否则找不到放到数组哪个位置),next指针指向下一个节点的引用。当新元素来到时,先取key的hashcode(),把这个值传入hash()计算h,用h再和entry数组的size-1计算数组索引。
2、发生hash冲突,调用key的equals方法,如果相同,则覆盖当前value值;如果不相同则拉链,循环next指针到末尾添加新元素。当拉链元素个数超过8时,链表就会变为红黑树。
3、随着entry的不断加入,当entry数组的size >= 当前容量*0.75(负载因子)时,hashmap就会扩容entry数组,扩容后的entry数组大小是之前的2倍,然后把原来数组里的全部元素重新计算h值和索引放到新数组里。(同一个桶中的h值不一定相同,h值的低位肯定相同!,扩容时多了一个高位需要考虑,所以才需要重新计算索引值)
4、hash()函数对hashcode的改造是为了尽量减少hash冲突的,因为如果直接用hashcode值对size取余,也行,但是只是利用了地位信息,比如305485432(0001 0010 0011 0101 0101 0110 0111 1000)和305419896(0001 0010 0011 0100 0101 0110 0111 1000)对16取余相同;但是如果经过hash将高16和低16异或,得到h值再和16-1做&运算,就得到不同的值12和13.
5、扩容机制:桶为拉链:如果h&oldcap==0,则索引不变,否则索引=旧索引+oldcap。
桶为红黑树:利用split()自动把红黑树内的元素重新计算索引,自动分配到新数组并构建拉链或树。
桶为单个元素:直接计算索引。
6、线程不安全:当多线程put时,都读取到了某个索引位置为空,那么就会出现覆盖值,而不是形成拉链。put时扩容后还没分配元素,get可能得到null。用Collections.synchronizedMap(),ConcurrentHashMap。
7、concurrenthashmap为啥线程安全:并发写:1.7之前分段reentrantlock分段锁,1.8空槽CAS+非空槽synchronized。并发读:1.7段上加volatiled,1.8槽位volatiled。
8、concurrenthashmap和hashmap区别:线程安全,性能方面。
9、hashset和hashmap区别:hashset可以看成固定value的hashmap,
10、hashtable和hashmap:hashtable通过给方法加上synchronized关键字保证线程安全,所以串行,效率低。不允许null,初始容量和负载因子固定。
11、为啥用红黑树:红黑树是自平衡的二叉查找树,查找时间复杂度为logn,比链表好。如果用二叉树则可能因为插入顺序有序变成链表,而平衡二叉树又因为严格的定义导致每次插入调整多次。
TreeMap
底层是红黑树,当put时,如果根节点为空直接插入,否则根据key对象的comparator来比较大小,用红黑树规则插入。因此插入时间复杂度是logn。适合范围查询或有序遍历。
创建线程方法
1、继承Thread类:重写run方法,并调用start方法。
2、实现runable接口:重写run方法,并将此类实例传给Thread构造方法,再调用start
3、实现callable接口:重写call方法,将此类实例传给futuretask构造方法,再将futuretask传给thread,调用start方法。
start和run的区别
run是在当前线程运行逻辑,而start是创建新线程并置于就绪态,来运行逻辑。
java中的锁
1、互斥锁
2、自旋锁
3、悲观锁
4、乐观锁
synchronized理解
锁升级:无锁 偏向锁 轻量级锁 重量级锁
1、当线程A访问无锁的对象时,会升级成偏向锁,将该对象的mark word里的线程ID改为自己,偏向锁位置1.
2、当线程B访问偏向锁对象时,发现对象的偏向锁位为1,线程ID不为自己,然后让JVM查找A是否活跃,如果不活跃则置无锁让B获取偏向锁;如果A活跃,则让JVM查找A的栈帧查找A是否还要持有偏向锁,如果不持有则置无锁,如果持有则进行偏向锁撤销,升级为轻量级锁。JVM首先STW,把锁对象的markword区域大重造为一个指针,指向A的锁记录区域。
3、当线程B要获取轻量级锁时,CAS的期望值永远是原来锁对象的Markword原数据和他自己的锁记录地址值。当自旋次数过多或者两个线程CAS时会升级成重量级锁。
4、锁对象中记录Moniter的地址值,moniter里面记录了持有当前锁对象的线程ID,并把其他线程放入等待队列中等待被notified
synchronized和lock
1、synchronized是jvm内部自动实现加锁放锁。
2、lock需主动获取和释放。
synchronized和reentrantlock
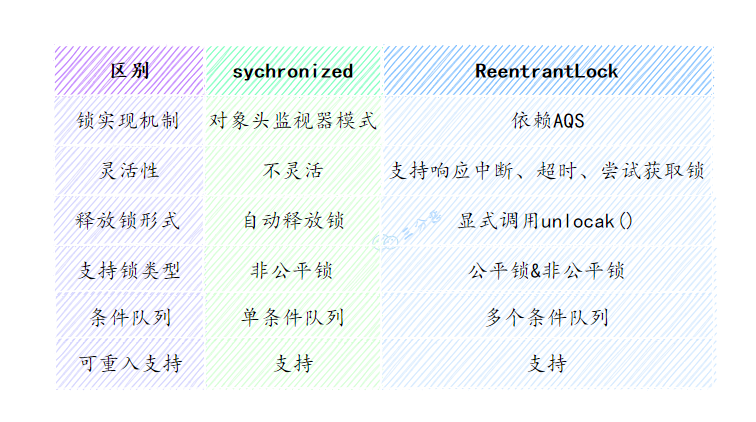
AQS
AQS里面有三个东西state记录线程进入次数,当前线程ID,同步队列(FIFO)储存获取锁的线程对象。
A线程首先CAS(C的是state,期望值是0,set值是1)获取锁,成功后设置当前线程ID。B线程再CAS发现state不为0,那么再CAS,如果还不为0则检查当前线程ID是不是B(可重入),如果不是则将自己包装成节点放到同步队列的队尾。当A线程unlock时,会唤醒同步队列的头节点的后一个节点来CAS。如果是非公平锁,此时可能有C线程也来CAS且比B线程快,那么B线程会获取失败,再放回队尾。
jwt
jwt有三个部分,jwt头,有效载荷,签名。
1、jwt头是个json对象,里面记录了用到的签名算法。然后用Base64 URL编码成字符串1。
2、有效载荷:放入需要传递的真实信息。然后用Base64 URL编码成字符串2。
3、签名:用jwt头中的签名算法编码 字符串1.字符串2.服务端自定的字符串。编码后的字符串3就是签名。
volatile作用
1、修饰变量,使变量多线程可见。(通过直接修改内存中而不是从内存复制到CPU)
2、防止指令重排(内存屏障)
内存屏障有四种,其实作用就是保证前一个单词必须在后一个单词前执行。
LoadLoad屏障:确保Load1的数据加载先于Load2及其后续所有加载指令
StoreStore屏障:确保Store1的数据对其他处理器可见先于Store2及其后续所有存储指令
LoadStore屏障:确保Load1的数据加载先于Store2及其后续所有存储指令
StoreLoad屏障:确保Store1的数据对其他处理器可见先于Load2及其后续所有加载指令
所以volatile读写逻辑就很清楚了。
写操作:围绕volatile变量的写操作 记住规律 前两个重复 所以是SS SL
读操作:LL LS
为啥要有线程池
1、因为线程创建销毁需要时间,所以为了节约时间。
2、线程创建销毁需要资源,为了节约资源。
3、防止线程过多。
4、提高响应速度。
线程池参数
当任务数小于核心线程数时,直接调用核心线程,满了则进入等待队列,队列满了则启动非核心线程,非核心线程满了则采用拒绝策略,非核心线程存活时间超过时长则回收。
1、核心线程数
2、最大线程数
3、线程工厂
4、等待队列
5、非核心线程存活时间
6、非核心线程存活时间单位
7、饱和拒绝策略
线程池的拒绝策略
1、AbortPolicy
2、CallerRuns
3、DiscardOldest
4、Discard
BIO NIO AIO
都是针对IO操作,都是针对单线程来说。
1、BIO:一个IO操作对应一个线程来监控,如果该线程的IO操作不完成,则不进行后面的逻辑。
2、NIO:一个线程监控多个IO操作。这是种思想,JAVA里的实现是选择器selector,将多个IO操作注册到选择器中,然后执行select操作阻塞该线程,轮询有IO操作完成,再处理IO操作。
3、AIO:一个线程监控多个IO,但是异步,将IO操作交给操作系统,然后该线程可以做其他事,IO完成后,操作系统会通知该线程哪个IO完成了,然后处理该IO。
JAVA内存区域
1、堆:存放对象,静态变量,字符串常量池
2、元空间:存放类的元信息
3、虚拟机栈:存放线程的方法栈帧
4、本地方法栈:存放本地方法的栈帧
5、程序计数器:
强 软 弱 虚 引用

1、强引用:即使内存不足也不会回收此对象。
2、软引用:下次回收时,内存不足时回收。
3、弱引用:下次回收时,不论内存足不足,都回收。
4、虚引用:无论何时 都回收。
如何判断对象是否需回收
可达性算法:从GC roots开始找存活对象。
垃圾回收算法
1、标记清除
2、标记复制
3、标记整理
4、分代收集
Minor,major,full gc
1、minor:是young gc,用标记复制清除新生代,时机是eden区空间不足
2、major:是old gc,用标记整理法清除老年代、
3、full gc:新生代和老年代都清除,时机是young gc时发现老年代空间不足以这次新生代晋升。
垃圾回收器
1、serial单线程串行,parNew多线程并行,serial old单线程
2、parallel scavenge 多线程并行,parallel old多线程并行
3、CMS 标记清除算法。初始标记(只标记从gc roots直接可达),并发标记(标记所有),重新标记(处理并发阶段的标记变动),并发清除
4、G1 标记整理算法,将堆分成一个个的region,每个region可为新生代也可为老年代。 初始标记,并发标记,最终标记,筛选回收(对region进行价值评估,在用户预期时间内先回收成本低而价值大的。)
JVM
类加载器
类加载器加载A类的时机:1、new A 2、调用了A的静态变量或方法。3、 反射。
类加载器有加载、链接、初始化三个过程。
加载:将需要的class文件转化为二进制流,读取class文件内容的元信息(类全名,父类名,字段名,类常量池),把这些信息复制到元空间并改进,根据元空间内的元信息在堆中创建对应类的Class对象并指向元空间内的元信息。

链接:检查class文件的格式是否正确;将为静态变量分配内存空间(元空间)并赋空值;将符号引用转为直接引用(根据运行时常量池的全名如果在堆没找到具体的Class对象,则会根据运行时常量池的信息创建新的Class对象,将这个Class对象的地址值替代到表中具体位置)。
初始化:将静态变量赋class文件里设定的初始值;执行静态代码块。
双亲委派机制

JVM根据类的全名来分配类加载器。
当一个类加载器收到加载请求时,先委托父加载器加载,如果父加载不了,当前加载器再加载。
优点:1、安全:保证JAVA的核心库(java.lang.*)由启动类加载器加载,保证不被恶意代码篡改。2、类加载的唯一性:同一个类由同一个类加载器加载。3、避免重复加载
缺点:1、类加载时间长。2、灵活性低。
破坏方式:1、tomcat web加载。2、自定义类加载器URL加载。3、Java Agent
垃圾回收算法
1、标记清除:遍历一遍gc roots,再遍历一遍堆来清除。
2、标记复制:遍历一遍gc roots同时复制。
3、标记整理:遍历一遍gc roots,遍历堆进行移动。
垃圾回收器
1、serial 和serial old:单线程串行,年轻代标记复制,老年代标记整理。
2、parnew:serial的年轻代的多线程并行版本。
3、parallel scavenge 和parallel old:多线程并行,专注吞吐量 = 代码时间/(代码时间+垃圾回收时间)
4、CMS:并发。包括四个阶段1、初始标记。2、并发标记。3、重新标记。4、并发清除。13需要STW。
5、G1:并发。四个阶段1、初始标记。2、并发标记。3、最终标记。4、筛选回收
AOP
面向切面编程,在不改动核心业务代码的情况下,横向切入新的功能。通过反射调用被代理的方法,接口,类。
1、切入点:连接点的汇总
2、切面
3、连接点:要被切入的方法
4、通知:切入时实施的逻辑。
AOP的动态代理
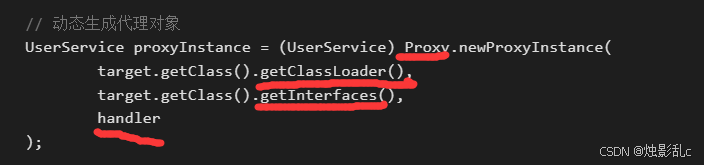
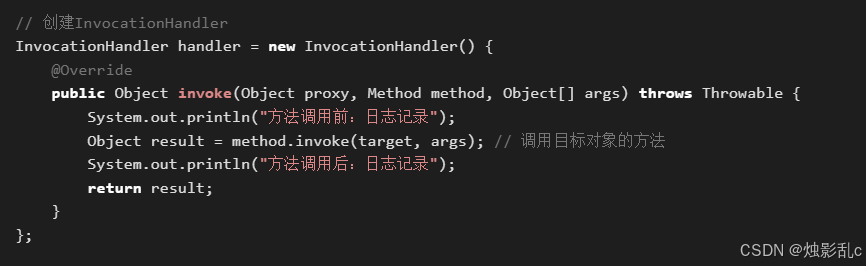
1、JDK:用proxy创建动态代理,只能代理实现了接口的类
当使用 Proxy.newProxyInstance() 创建代理对象时,需要提供三个参数:
类加载器:指定用来加载代理类的类加载器。
接口:指定代理类需要实现的接口。
InvocationHandler:指定代理逻辑。
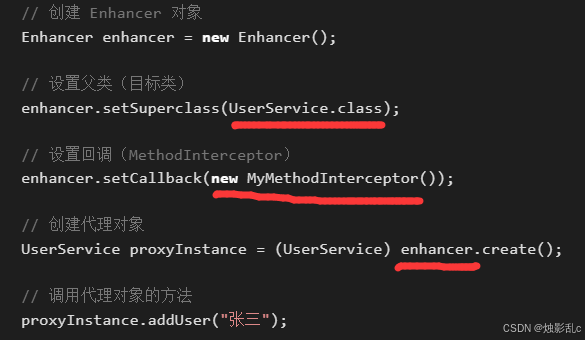
2、CGLIB:用enhancer创建动态代理,可以代理没有实现接口的类。
传入:被代理的类,方法逻辑。
IOC的理解
控制反转,是一种思想,将创建对象的权利交给Spring框架,无需手动创建。在Spring中的具体实现是DI。
1、构造器注入
2、setter方法注入
3、注解注入
Configuration注解和component注解
使用 @Component 等注解的场景:
你自己编写的业务类
可以直接修改源码的类
较为简单的对象创建场景
使用 @Configuration + @Bean 的场景:
第三方库中的类(无法直接在类上添加注解)
需要复杂配置的对象
需要条件化配置的场景
需要在创建时进行特殊处理的对象
比如redis的使用,需要配置地址和密码,既是第三方库里的类,这个类可能没加component注解,我们不敢赌;又需要设置东西,所以需要用Configuration注解
Bean的作用域
1、单例
2、原型:每次对该bean的请求都换产生新的实例。
3、request:每次http请求产生新bean,在该请求内有效。
4、session:同一个 Session 共享一个 Bean。
5、global session:同一个全局 Session 共享一个 Bean。
Bean的生命周期
1、实例化(运行构造器)
2、依赖注入(成员变量赋值)
运行 BeanNameAware等aware接口的方法
运行 BeanPostProcess 实现类的before方法
运行initialingbean接口的方法
3、初始化(运行自定义初始化方法)
运行 BeanPostProcess 实现类的after方法
4、使用Bean
运行disablebean接口的方法
5、销毁Bean(运行自定义销毁方法)
Bean的循环依赖解决方法
三级缓存,singleonFactioies,earlysingletonobjects,singletonobjects。无法解决构造器依赖注入的循环依赖。
1、实例化A的同时把A的工厂放入singletonfactories中,进行A的依赖注入时发现B。此时从一到三级缓存都未找到B的Bean对象,进入B的Bean创建。
2、B实例化后依赖注入时从三级缓存找到A的工厂,把通过工厂获得的A注入到B中,再把A的工厂从三级缓存删除,把A放入二级缓存,把依赖注入好,初始化好的B放入一级缓存中。
3、此时A再从一级缓存中找到B的bean进行依赖注入,完成后把A的Bean放入一级缓存,把二级缓存的A删除。
conpomnent和bean注解的区别
前者用在类上,让通过spring的componentscan设置扫描路径来装配到ioc容器中。后者用在方法上,让方法返回某类的实例。
@Autowire和@resource的区别
1、autowire是spring的,resource是java的。
2、autowire默认是通过接口类型寻找匹配的实现类但可通过qulifer指定名字,resource默认是通过名字(实现类首字母小写)但可通过name属性显式指定名字
3、resource不能用在构造函数。
Spring用到的设计模式
1、单例模式
2、工厂模式
3、代理模式
Spring MVC流程
客户端,servlet,dispatcherservlet,handlermapping,handleradapter,controler,dispatcherservlet,viewresolver,dispatcherservlet
1、客户端的请求传到Servlet,先被分给dispatcherservlet
2、dispatherservlet将请求发给handlermapping
3、handlermapping根据请求的URL等找到匹配的controler。(如果有拦截器则执行prehandler方法)
4、dispatcherservlet调用handleradapter调用controler,把请求中的参数解析给controler。
5、handleradapter将controller的执行结果modelandview返回给dispatcherservlet。
6、dispatcherservlet将modelandview传给viewresolver
7、dispatcherservlet将viewresolver解析后得到的view进行视图渲染并返回给用户。
Spring boot starter作用
简化和加速项目的配置和依赖管理。starter整合了许多有用的依赖。比如web。
threadlocal
每个线程Thread被创建时都有个threadlocalmap属性,这个map的key是ThreadLocal对象本身,value是threadlocal.set时的值。
当调用threadlocal.set时,会先拿到当前线程,然后当前线程把这个threadlocal作为key,set的值为value存到threadlocalmap中。
当调用 ThreadLocal.get() 方法时,当前线程会从自己的 ThreadLocalMap 中,使用当前 ThreadLocal 对象作为 key 查找对应的 value。
threadlocalmap使用软引用存储key,强引用存储value。
spring事务
1、編程式:直接在代码的前后使用事务的开启和关闭
2、声明式:使用transction注解,生成动态代理对象
spring事务传播机制
也就是B方法是个事务,根据B事务的设置的传播机制,在A方法中调用B时会出现哪种情况。例如B加入到A的事务中还是自己另起个事务;如果A没事务,会报错还是自己另起个事务。
1、require:有则加,无则创
2、require_new:无论有无,都自创。
3、nested:有则嵌套,无则自创
4、MANDATORY:有则加入,无则报错
Spring boot自动装配
主要是自动装配spring boot starter中提供的bean。当我需要用A写的类的功能时,当A写的不是starter时,我需要把他的类手动写到XML文件中,如果是starter时,spring boot在启动时会自动把这个bean注入到容器中,我直接autowire就行。
springboot启动时会扫描所有第三方jar包中的META-INF/spring-factory文件,这个文件里是jar作者想把自己的哪些bean注入到IOC容器中供他人使用。
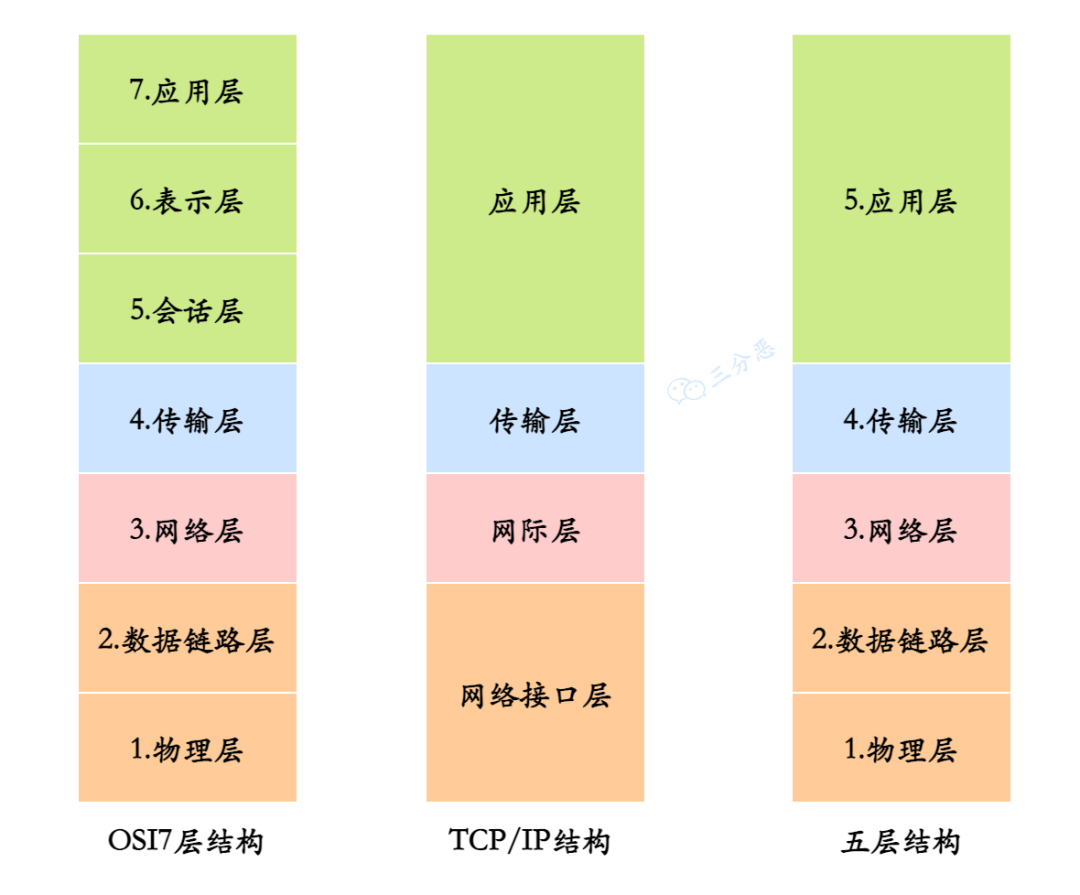
OSI七层和TCP/IP四层
1、物联网输会表用。
2、网络接口层,网际层,传输层,应用层
3、五层体系结构:物理层,数据链路层(交换机),网际层(ip),传输层(TCP),应用层。
输入URL到页面展示
1、解析URL:先本地缓存,再本地DNS运营商,如果还没有,则让DNS服务商向根域名,顶级域名,最后让权威域名解析URL的IP地址。
2、建立TCP连接:三次握手
3、发出HTTP请求
4、响应HTTP
5、断开TCP连接:四次挥手.
三次握手
1、客户端先发出SYN,seq=x报文。进入sys_sent
2、服务端接收到后,发出SYN,ACK,seq=y,ack=x1的报文,进入sys_rcvd.
3、客户端接收到后,发出ACK,ack=y+1的报文,进入established。服务端接收到后也进入established。
为啥是三次,而不是两次
1、阻止重复的历史连接
当客户端发出两次SYN报文时,服务端会发出两次SYN+ACK,当是三次时,客户端可以根据自身上下文信息判断有个历史连接,然后返回一个RST报文表示终止此次连接,只连接最新的;如果是两次时,客户端会两次都established。
2、同步双方序列号
3、服务端可能因未收到客户端的 ACK 而长期维护无效连接。
四次挥手
1、主动端先发送FIN报文,进入fin wait1.
2、被动端接收到后发送ACK报文,进入closed wait。主动段接收到后进入fin wait2
3、被动端发送完剩余报文后,发送FIN报文,进入last ack。
4、主动段接收到后发送ACK报文,进入time wait 2MSL时间后closed。被动端接收到后closed
为啥是四次
因为TCP发送数据是全双工的,需要保证双方数据都发送完毕,都准备好FIN了。
为啥需要time wait
1、保证被动端能正确接收第四次的ACK,从而正确关闭。
2、保证历史数据能被全部接收。
为啥time wait 是2msl
1msl保证主动端的ack能够到达被动端,后1msl保证被动端没收到ack时重传fin能被主动端收到。
HTTP 请求报文
1、请求行:请求方式,URL,版本协议号
2、请求头:key:value形式。附加信息
3、请求体:要提交的详细信息,用于post,put等
HTTP 响应报文
1、状态行:版本协议号,状态码,状态消息
2、响应头:key:value形式。附加信息
3、响应体:要响应的详细信息。
HTTP请求方式
get,post,put,delete,trace,OPTIONS
GET和POST的区别
1、请求参数:get在url中,post在请求体。
2、幂等性:get幂等,post不幂等。
响应状态码
1、1 是处理中
2、2是成功
3、3是重定向
4、4是客户端问题
5、5是服务端问题
200 请求成功
301 永久重定向
302 临时重定向
304 可直接使用缓存
400 请求语法错误
401 请求需权限
403 资源禁止访问
404 资源未找到
500 服务端内部出错
503 服务器忙
强缓存和协商缓存
1、强缓存:客户端不需要和服务端进行通信,自己就可以判断请求是否命中缓存。expires过期时间和cache control有效时间
2、协商缓存:客户端需要和服务端通信,让服务端判断是否命中缓存,命中则返回304。if modified since和if not match
HTTP1.0 1.1 2.0
短链接,长连接,多路复用
1.0和1.1的区别
1.0是短链接,一次TCP连接内只能有一次HTTP请求和响应。
1.1是长连接,一次TCP连接内能有多次HTTP请求和响应。得益于长连接,1.1允许当前请求在上一个请求的响应没回来时发送当前请求,但是要求服务端发送响应时必须按照请求顺序来。
1.1 和 2.0 区别
2.0实现多路复用。复用的是TCP,多路是逻辑上把每个请求响应开通一个stream通道,每个stream通道里有多个帧,帧内包含stream ID和帧的顺序信息。从而解决1.1的响应队头阻塞。
HTTP3.0
采用UPD,解决2.0的TCP阻塞问题。因为TCP还是字节流形式,所以当前一个字节流丢失时,接收端需等待重传,造成阻塞。
HTTPS和HTTP
多了SSL+TSL
非对称加密+对称加密
1、客户端输入URL发送请求给服务端。
2、服务端发送包含公钥和证书信息的证书
3、客服端收到后判断证书安全性,如果安全则用公钥加密自己生成的会话密钥,发送给服务端
4、服务端接收到后用私钥解析得到会话密钥,然后双发用会话密钥通信。
TCP和UDP的区别
1、可靠性
2、连接
3、传输形式
TCP为啥可靠
1、序列号机制:保证顺序和完整。
2、超时重传机制
3、流量控制:接收方在返回确认时会告诉发送发自己的接收窗口大小,以便让发送发调节发送速度。
4、拥塞控制:TCP采用慢启动,一开始发送的少,逐步增加,当监测到网络拥塞时,降低发送速率,缓解后逐步恢复。
TCP的流量控制
接收方通过TCP报文头部中的窗口大小告诉发送方自己还有多少窗口空间。当窗口满了,发送方不再发送数据,而是定时发送探测报文监测接收方窗口大小。
TCP拥塞控制
1、慢启动:发送方从较小的数开始指数增长。
2、拥塞避免:达到慢启动阈值时,线性增长。
3、快速重传:当发送发收到重复3个ACK时,快速重传丢失的数据包。将拥塞窗口除以2,并将慢启动阈值设为当前拥塞窗口。
4、快速恢复:将拥塞窗口设为慢启动阈值+3
HTTP的KeepAlive和TCP的keepalive
1、HTTP的KeepAlive是长连接
2、TCP的是保活机制,当一个TCP连接超时任务触发后,会发送探测报文给对端,判断对端是否存活。
CDN
conten delivery network 内容分发网络。将内容储存在分布式服务器上,使用户可以从距离较近的服务器获取资源。
工作流程:让输入URL时,如果启用了CDN,则DNS会返回最近的CDN节点IP,而不是网站源IP。当用户访问CDN节点IP时,CDN会判断请求是否命中缓存,如果命中则直接返回,否则向源IP请求资源再返回。
Cookies和Session
用于记录用户信息。
1、cookies存放再客户端,当响应中有setcookies字段时,浏览器会将相应信息保存到本地,之后的请求会将cookies信息放在请求头中。
2、session存放在服务端,当客户端访问服务端时,服务端会将信息记录在服务器上。
进程和线程的区别
进程是计算机资源分配和调度的基本单位。
线程是计算机调度的最小单位。
1、内存空间:进程独立,线程共享。所以进程的创建和销毁,切换开销大。
2、通信:由于进程相互隔离,需要特殊机制如管道、消息队列,共享内存等。线程直接共享内存。
3、安全性:进程不会影响其他进程稳定性。但是线程可能会影响。
用户态和核心态
是CPU的运行级别,是操作系统设计的,可以控制进程对计算机硬件资源的访问权限和操作范围。
1、用户态:只能执行有限的指令集和访问有限的资源,不能访问操作系统的核心部分,不能直接访问硬件资源。
2、核心态:进程可以直接访问硬件资源,执行系统调用,管理内存、文件系统等。
切换场景:1、系统调用。2、异常.3、中断(外部设备如鼠标键盘磁盘)
进程调度算法
1、先来先服务
2、短作业优先
3、最短剩余时间优先
4、优先级调度
5、时间片轮转
6、多级队列(优先级调度+时间片轮转)
进程通信
1、管道:半双工,父子进程之间
2、命名管道:半双工,允许非父子进程
3、信号量:计数器,控制多个进程对共享资源访问,常作为锁机制
4、消息队列:存放在内核区,消息的链表。
5、信号:通知接收进程某个时间已经发生。
6、共享内存:映射一段能被其他进程访问的内存,这段共享内存由一个进程创建,但多个进程都可访问,是最快的通信方法,通常配合心信号量使用
7、Socket套接字:TCP/IP网络通信的基本操作单元。
线程同步方式
1、互斥锁
2、信号量
进程同步和互斥
1、同步:协调多个进程执行顺序,使其按照预定顺序执行。
2、互斥:确保多个进程不会同时访问共享资源。
实现方式:1、信号量 2、互斥锁
死锁
多个进程在互相等待对方释放资源而无法正常继续执行。
1、互斥
2、不可剥夺
3、持有并等待
4、循环等待
解决方法:1、消除不可剥夺:当进程请求不到另外的资源时,主动释放已有资源。
2、消除持有并等待:一次性拿到所有资源
3、消除循环等待:按资源顺序,线性申请资源。
锁
1、互斥锁:同一时刻只有一个线程能持有互斥锁。
2、自旋锁:尝试获取锁时会不断轮询,直到锁被释放。
3、读写锁:允许多个线程读,只允许一个线程写。
4、悲观锁:认为同时修改共享资源概率高,访问时要上锁
5、乐观锁:先修改,如果遇到同时修改,则放弃本次操作。
虚拟内存
允许访问比物理内存更大的地址空间。
页面置换算法
1、最佳页面:以后都不会用到的出去,难实现
2、先进先出
3、最近最久未使用
4、最不常用:记录页面访问次数,访问次数少的出去。
5、时钟:当访问位为1则置零,直至访问到0。
Linux命令
ls,cd,mkdir,top,pwd,rm,cp,kill
SQL查询语句如何执行
1、客户端发送SQL语句给MYSQL服务端
2、连接器:跟客户端建立连接,获取权限等。
3、解析器:解析SQL语句是否正确
4、优化器:确定执行顺序,比如使用哪些索引,表的连接顺序等
5、执行器:调用存储引擎来执行SQL语句。
6、客户端收到查询结果,结束。
事务的特性
ACID
1、原子性:事务的操作必须一次全部完成,要不就回滚。
2、一致性:确保数据库的状态从一致的一个状态到另一个一致的状态。
3、隔离性:一个事务在执行的过程中,不被其他事务影响。
4、持久性:一旦事务提交,其所做的修改被永久保存到数据库中。
事务隔离级别
1、读未提交:当前事务可以看到其他事务未提交的数据。脏读,不可重复读,幻读
2、读已提交:当前事务只能看到其他事务已提交的数据。不可重复读,幻读。
3、可重复读:当前事务看到的数据,和启动时的数据一致。幻读。
4、序列化:强制事务串行执行。
索引分类
1、功能分类:
主键索引:指定主键时自动创建的索引,唯一性和非空性
唯一索引:保证数据列中每行的唯一性,允许空值。
普通索引:基本的索引类型,用于加速查询。
2、存储位置
簇族索引:叶子节点包含了完整的行记录
非簇族索引:叶子节点只含有对应的主键值,需要回表到簇族索引查询完整的行记录。
索引失效
1、索引列上使用函数或表达式
2、Like语句中通配符在前面
3、不满足最左匹配
4、使用<或>或NOT,因为会扫描全表。
为啥用B+树
1、B+树的非叶子节点只存储索引值,可以储存更多的索引值,可以更加的矮胖,查询底层节点时可以减少磁盘IO次数。
2、B+树的叶子节点用链表前后连接,在范围查询时更加快速。
undo log,redo log ,bin log
bin log用于记录所有写操作SQL。redo log记录页的物理变动(例如某个字符由a变成了b)。undo log 记录事务修改前的数据状态,以便在事务失败或显式回滚时能恢复数据。
慢查询,优化
查询时间超过指定时间的查询语句。
原因:
1、查询语句过于复杂:多个表连接等
2、查询到的数据量大
3、缺少索引
4、数据库设计不合理
优化:
1、优化查询的列:避免使用*
2、索引优化:避免索引失效场景
Mysql的锁
按颗粒度:
1、表锁
2、行锁
3、页锁
按兼容性:
1、共享锁(S,读):有S能来S,不能来X
2、排他锁(X,写):有X谁都不能来
MVCC(多版本并发控制)
当某一行数据被多个事务访问和修改时,MySQL通过MVCC机制管理数据的多个版本,实现读写并发控制。
核心组件:
隐藏字段(数据行级别):
每行记录都包含隐藏字段:DB_TRX_ID(最近修改的事务ID)和 DB_ROLL_PTR(指向Undo Log的指针)
每次更新数据时,生成新版本并将旧版本保存到Undo Log中
通过指针将同一行的各个版本串成Undo Log版本链
ReadView(事务级别):
事务在读取数据时创建ReadView,用于判断数据版本的可见性
ReadView包含四个关键字段:
m_creator_trx_id:创建ReadView的事务ID
m_ids:活跃事务ID列表(未提交事务)
m_up_limit_id:活跃事务中的最小事务ID
m_low_limit_id:当前系统最大事务ID + 1
可见性判断机制:
事务通过ReadView中的信息与数据行隐藏字段中的DB_TRX_ID进行比较,判断该版本是否对当前事务可见。如果不可见,则沿着版本链查找合适的历史版本。
隔离级别应用:
READ COMMITTED:每次SELECT都创建新的ReadView,能读取到其他事务新提交的数据
REPEATABLE READ:事务第一次读取时创建ReadView,整个事务期间复用同一个ReadView,保证可重复读
关键区别:
ReadView属于事务,记录事务的"快照视图"
隐藏字段属于数据行,记录行的版本信息
两者协作实现精确的并发控制和数据一致性
Mysql和Redis区别
1、存储位置
2、键值对和数据结构
3、命令集
Redis为什么快
1、基于内存
2、高效的数据结构
3、单线程:因为redis查询的确实快,所以用单线程足够了,单线程还能减少线程切换带来的开销。
4、IO多路复用:redis的主线程还能通过IO多路复用监听多个socket,当有socket可读或可写时再操作。
redis数据类型
String,hash,list,set,zset
ZSET数据结构
压缩列表,跳表
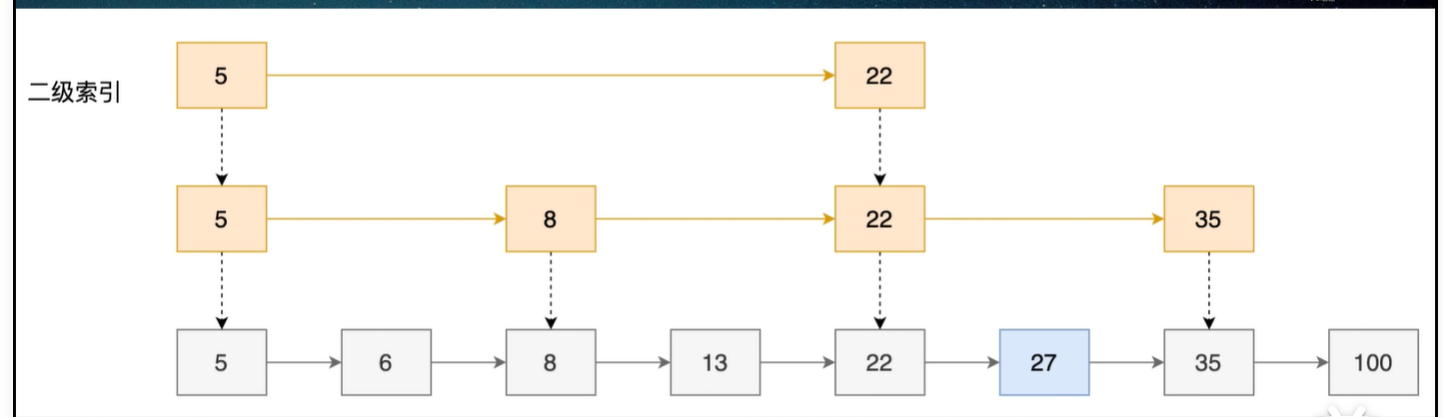
跳表是一种多层有序链表,底层是完整的有序链表,上层比下层节点数少、是下层的快速通道,每个节点包含不同指针,指向不同层的下一个节点。
增删改最好都是logn最坏n
范围差logn+m
什么时候用压缩列表
元素数量不超过某值(128)并且元素大小不超过某值字节(64)
为啥用跳表不用二叉树或红黑树
1、维护成本:平衡二叉树或红黑树在增删时可能需要旋转等操作,成本高;跳表则不需要。
2、范围查找:跳表天然有序,范围查找友好。
redis持久化机制
AOF和RDB
1、AOF:每执行一条写命令,把该命令以追加的形式写入到一个文件里。
2、RDB:将某一时刻的内存数据,以二进制的形式写入磁盘。
3、AOF+RDB混合:当需要恢复数据时,Redis 先加载 RDB 文件来恢复到快照时刻的状态,然后应用 RDB 之后记录的 AOF 命令来恢复之后的数据更改。
AOF的回写策略
1、always:每次写操作执行完后,同步将AOF日志数据写入硬盘
2、everysec:写操作完成后,先将命令写入AOF日志的缓冲区,然后每隔一秒写入硬盘。
3、no:写操作完成后,先将命令写入AOF日志的缓冲区,由操作系统决定何时写入硬盘。
缓存穿透
查询的数据redis中没有,数据库也没有。
解决方法:返回空对象或布隆过滤器
缓存雪崩
某个时刻,大量缓存数据同时失效。
解决方法:设置过期时间时上下浮动。
缓存击穿(热点KEY)
某个经常被访问且重建成本高的缓存数据突然失效
解决方法:设置逻辑过期时间。互斥锁。
如何保持数据库和缓存的一致性
先更新数据库,再删除缓存。
不选择更新缓存原因:每次都更新,如果没有查询操作,则浪费了很多资源。
先更新再删除原因:当读取数据库操作时间大于写入数据库操作时间时才会引发不一致,但是这种可能性很小。
单例模式
1、饿汉式
Public class Singleton(){
private Singleton(){};
private static final Singleton instance = new Singleton();
public Singleton getInstance(){
return instance;
}
2、双重检查
public class Singleton(){
private Singleton(){};
private static final Singleton instace;
public static Singleton getInstance(){
if(instance == null){
synchronized(Singleton.class){
if(instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
3、静态内部类
public class Singleton(){
private Singleton(){};
private static class SingletonHolder(){
public static final INSTANCE= new Singleton();
}
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}
4、枚举
public enum Singleton(){
INSTANCE;
}


















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









