




今天分享一个用Stable Diffusion换背景的小教程。在以往为产品或照片更换背景时,我们通常需要先仔细地将主体内容抠出,再利用PS或其他图像处理工具将主体与新背景进行融合。这个过程往往需要花费大量的时间和精力。这个方法虽然可行,但不够高效,非常考验图片处理技术。
今天我将分享一个简单又高效又实用的背景替换小教程,不需要深厚的图片处理技术就可以在几分钟内轻松完成背景替换。


1、前期准备
本文将会用到“Inpaint anything”插件,也可以使用“Segment anything”有这俩插件任意一个就行。
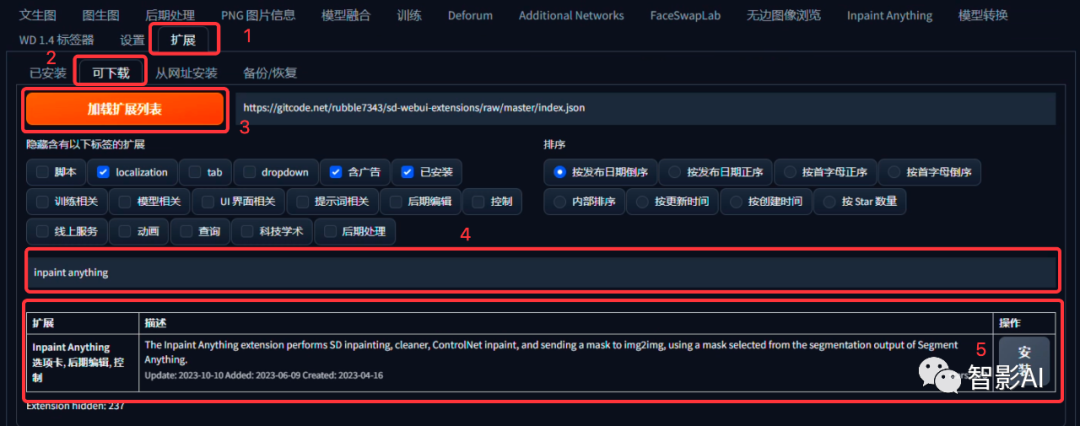
如果还没有安装插件的可以启动“Stable Diffusion”,点击“扩展”—“可下载”—再点击“加载扩展列表”,搜索关键词“inpaint anything”或“segment anything”,点击“安装“,安装完成之后,重启一下“Stable Diffusion”即可。
2、卡通图片
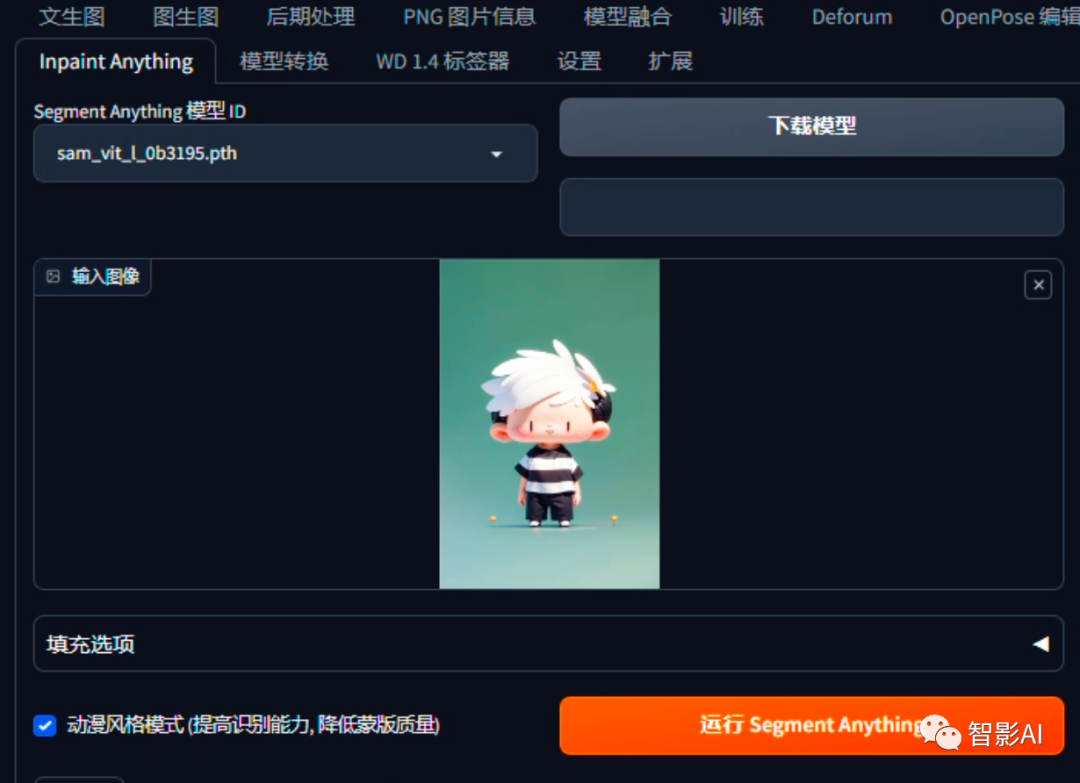
1. 打开Stable Diffusion,点击顶部栏的“Inpaint Anything”,然后上传一张图片,选择一个“Segment Anything”的模型。这里我选择了默认的“sam_vit_l_0b3195.pth”,如果前面还没下载的,记得先点旁边的“下载模型”进行模型下载。
2. 点击“运行 Segment Anything”按钮,大概等待1分钟左右,右边就可以看到在原图上经过分离并用不同的色块标注的物体,然后在背景的色块上点一下或者简单的涂一下来选择区域。
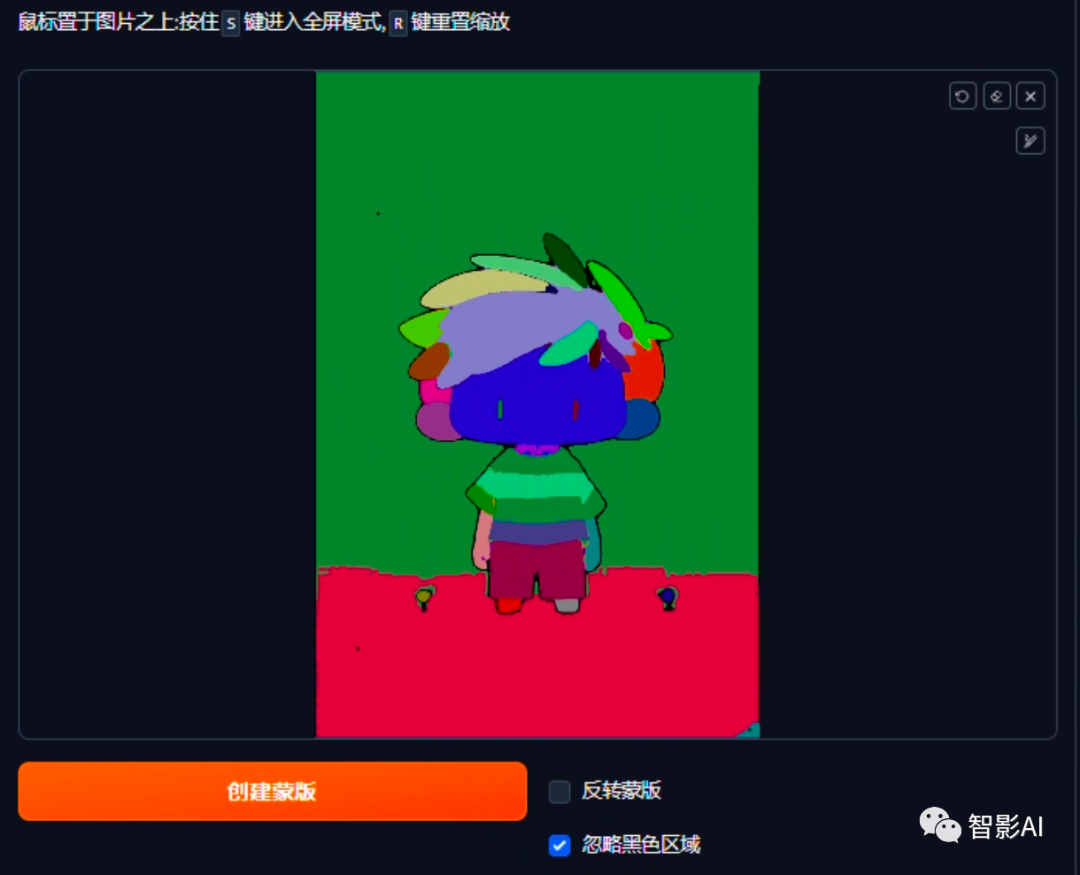
3. 区域选择完之后,如果背景是黑色的色块,记得取消勾选“忽略黑色区域”然后点击“创建蒙版”。
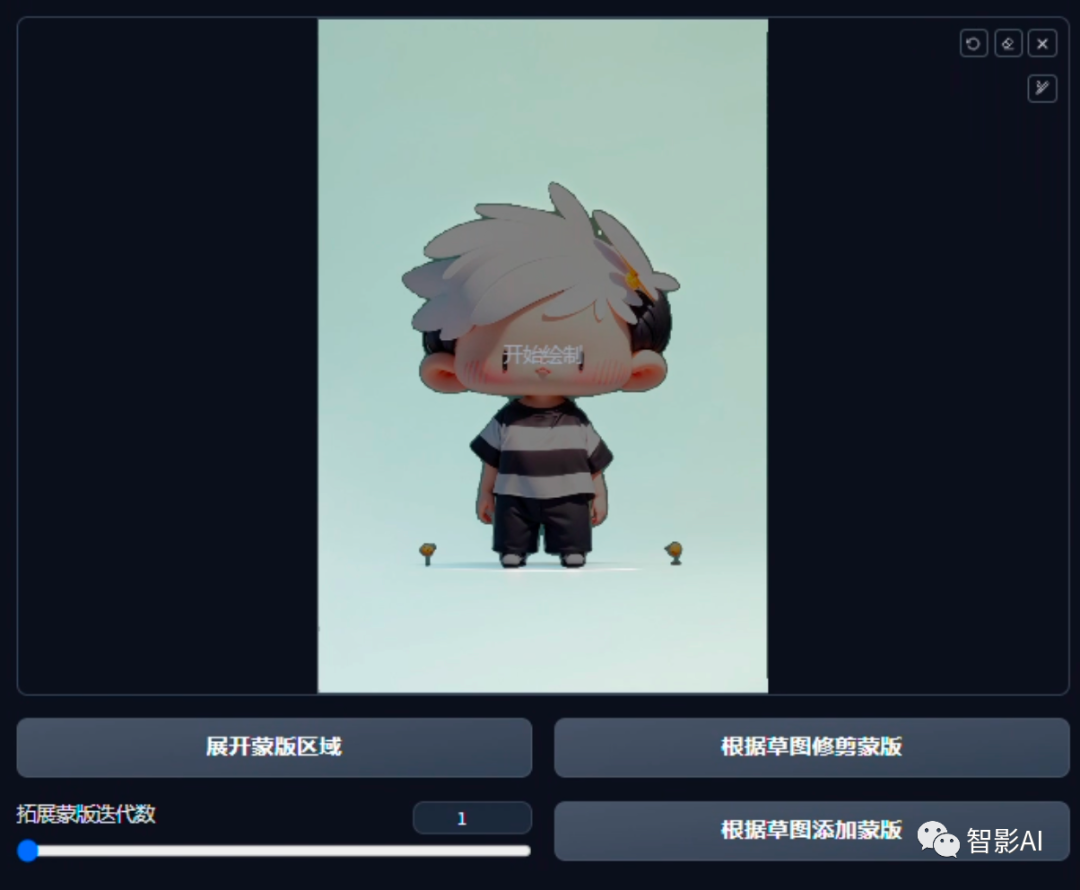
4. 蒙版创建完之后,点击左侧的“仅蒙版”选项,然后在点击“获取蒙版”。
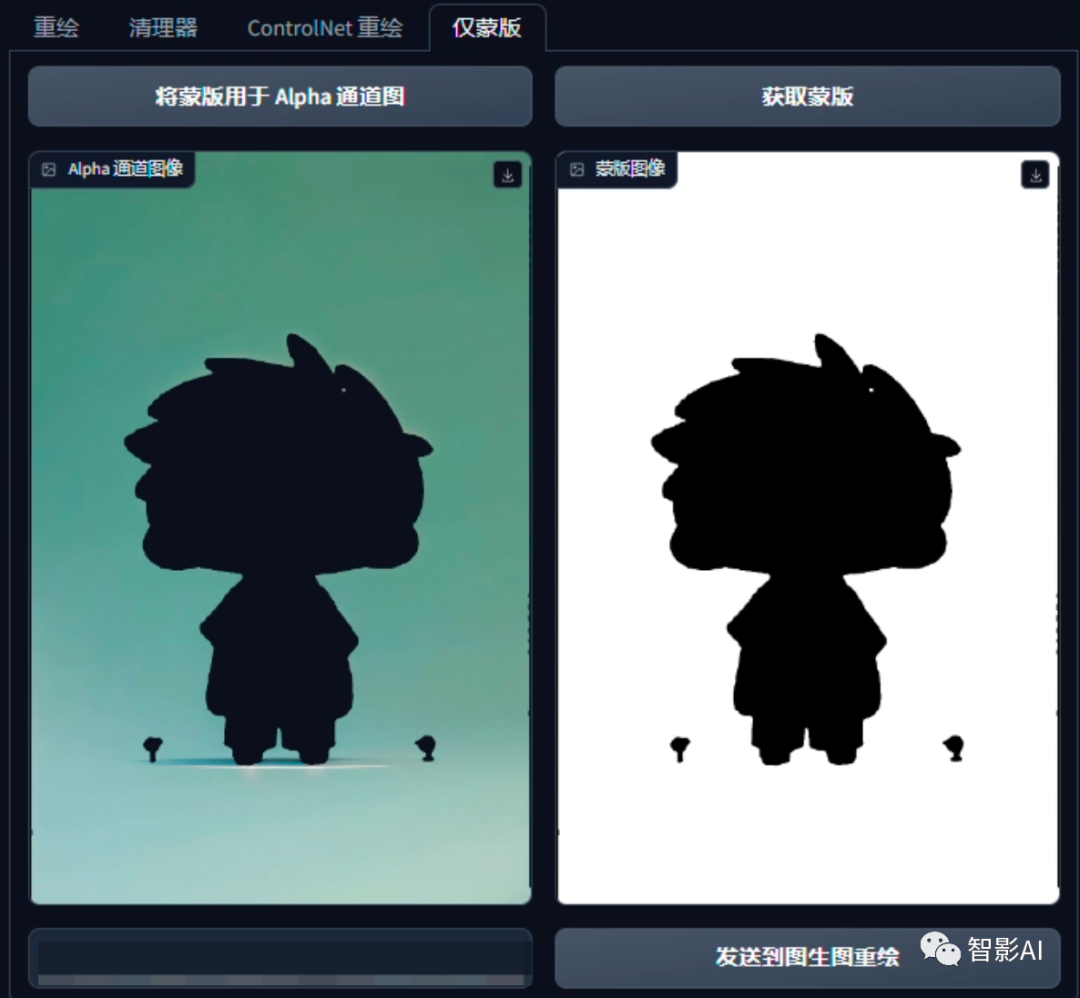
5. 获取到了蒙版之后,点击下方的“发送到图生图重绘”按钮,将蒙版发送到图生图。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









