




@浙大疏锦行

今日作业:对加州房价数据进行处理。
如果你的网络较差无法下载(一般是没问题的,可以多和ai沟通,并没有墙),可以通过该kaggle链接下载,后续专题我们也会在合适的时候提kaggle网站的更详细的使用方法和如何白嫖他的GPU资源。
California Housing Prices
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.utils import resample
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
# ====================== 1. 全局设置 ======================
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文显示
plt.rcParams['axes.unicode_minus'] = False # 负号显示
sns.set(style="whitegrid", font='SimHei')
# ====================== 2. 加载数据 ======================
# 数据路径(替换为你的实际路径)
data_path = r"D:\桌面\PythonStudy\python60-days-challenge-master\archive (1)\housing.csv"
# 加载数据并查看基本信息
df = pd.read_csv(data_path)
print("===== 加州房价数据集基本信息 =====")
print(f"数据形状: {df.shape}")
print("\n数据前5行:")
print(df.head())
print("\n数据信息:")
print(df.info())
print("\n缺失值统计:")
print(df.isnull().sum())
print("\n数值特征统计:")
print(df.describe())
# ====================== 3. 数据预处理 ======================
# 3.1 处理缺失值(总卧室数有缺失)
imputer = SimpleImputer(strategy='median') # 中位数填充数值缺失值
df['total_bedrooms'] = imputer.fit_transform(df[['total_bedrooms']])
# 3.2 处理类别特征(ocean_proximity)
# 独热编码
encoder = OneHotEncoder(sparse_output=False, drop='first') # 避免虚拟变量陷阱
ocean_encoded = encoder.fit_transform(df[['ocean_proximity']])
ocean_df = pd.DataFrame(
ocean_encoded,
columns=[f'ocean_{cat}' for cat in encoder.categories_[0][1:]], # 跳过第一个类别
index=df.index
)
# 合并编码后的特征,删除原类别列
df = pd.concat([df.drop('ocean_proximity', axis=1), ocean_df], axis=1)
# 3.3 特征/标签划分
X = df.drop('median_house_value', axis=1) # 特征
y = df['median_house_value'] # 标签(房价中位数)
# 3.4 划分训练集/测试集(8:2)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, shuffle=True
)
print(f"\n预处理后特征维度:{X.shape}")
print(f"训练集大小:{X_train.shape}, 测试集大小:{X_test.shape}")
# ====================== 4. 多模型训练与评估 ======================
# 定义回归模型
regressors = {
"线性回归": LinearRegression(),
"决策树回归": DecisionTreeRegressor(random_state=42, max_depth=10), # 限制深度避免过拟合
"随机森林回归": RandomForestRegressor(n_estimators=100, random_state=42, max_depth=15),
"梯度提升回归": GradientBoostingRegressor(n_estimators=100, random_state=42, max_depth=8)
}
# 存储结果和预测值
results = []
preds_dict = {}
print("\n===== 模型训练与评估 =====")
for name, model in regressors.items():
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
preds_dict[name] = y_pred
# 计算评估指标
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
# 存储结果
results.append({
"模型名称": name,
"R2得分": round(r2, 4),
"RMSE": round(rmse, 2),
"MAE": round(mae, 2)
})
print(f"{name} 训练完成 | R2: {r2:.4f} | RMSE: {rmse:.2f} | MAE: {mae:.2f}")
# 展示指标对比表
results_df = pd.DataFrame(results).sort_values(by="R2得分", ascending=False)
print("\n===== 模型性能排行榜 =====")
print(results_df)
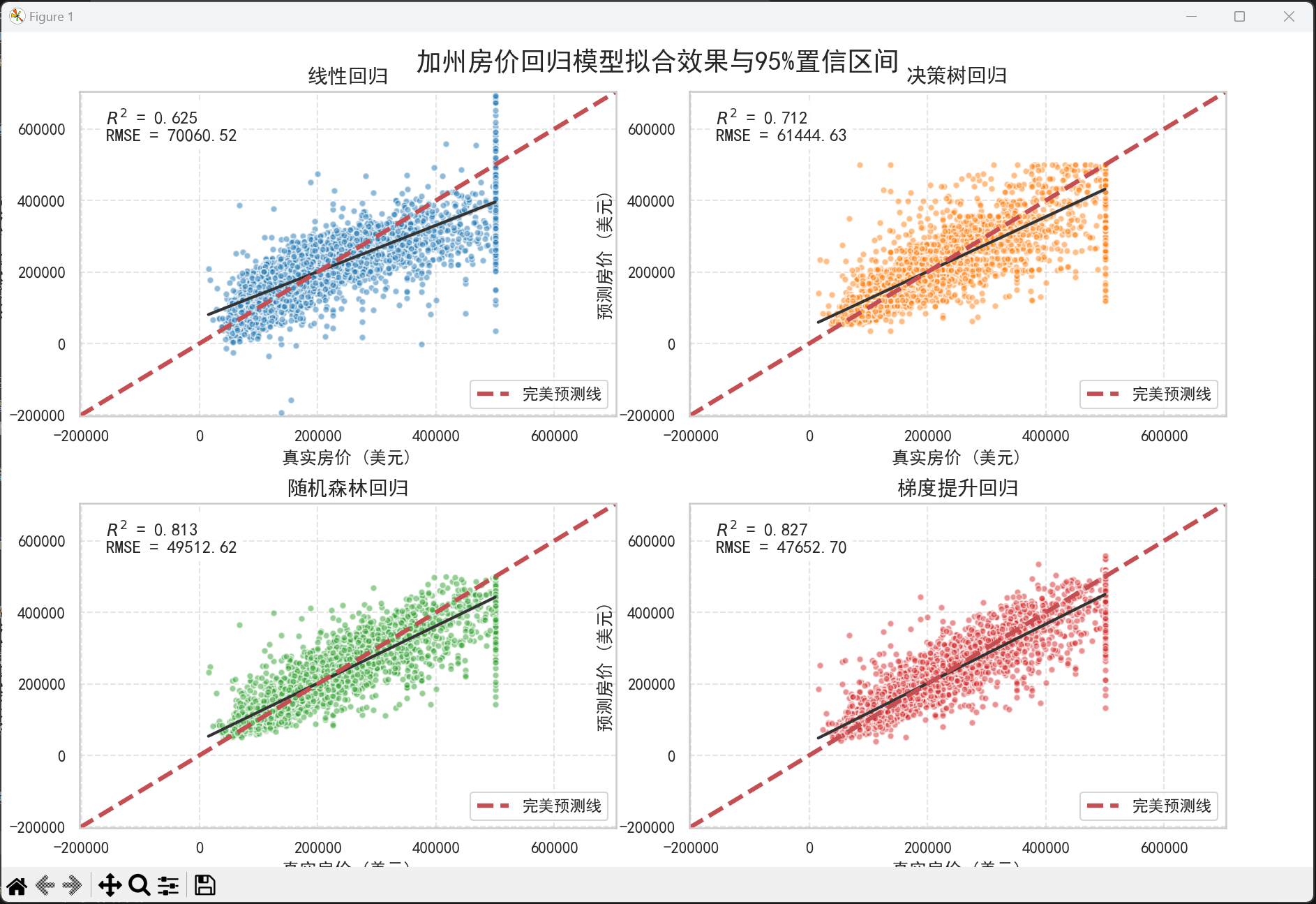
# ====================== 5. 回归拟合效果 + 置信区间可视化(Seaborn版) ======================
# 设置画布:2行2列
fig, axes = plt.subplots(2, 2, figsize=(18, 14))
axes = axes.flatten()
colors = ["#1f77b4", "#ff7f0e", "#2ca02c", "#d62728"] # 模型对应颜色
# 统一坐标轴范围
all_preds = [preds_dict[m] for m in regressors.keys()]
data_min = min(y_test.min(), np.min(all_preds)) - 10000
data_max = max(y_test.max(), np.max(all_preds)) + 10000
# 绘制每个模型的拟合图+置信区间
for i, (name, model) in enumerate(regressors.items()):
ax = axes[i]
y_pred = preds_dict[name]
# 绘制回归拟合图 + 95%置信区间
sns.regplot(
x=y_test, y=y_pred, ax=ax,
color=colors[i], ci=95, # 95%置信区间
scatter_kws={'s': 20, 'alpha': 0.5, 'edgecolor': 'white'},
line_kws={'color': '#333333', 'linewidth': 2}
)
# 绘制完美预测线(y=x)
ax.plot([data_min, data_max], [data_min, data_max],
'r--', linewidth=3, label='完美预测线')
# 添加指标文本框
r2 = r2_score(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
text_str = f'$R^2$ = {r2:.3f}\nRMSE = {rmse:.2f}'
ax.text(0.05, 0.95, text_str, transform=ax.transAxes, fontsize=12,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
# 图表装饰
ax.set_title(name, fontsize=14, fontweight='bold')
ax.set_xlabel('真实房价 (美元)', fontsize=12)
ax.set_ylabel('预测房价 (美元)', fontsize=12)
ax.set_xlim(data_min, data_max)
ax.set_ylim(data_min, data_max)
ax.legend(loc='lower right')
ax.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.suptitle('加州房价回归模型拟合效果与95%置信区间', fontsize=18, y=0.98)
plt.show()
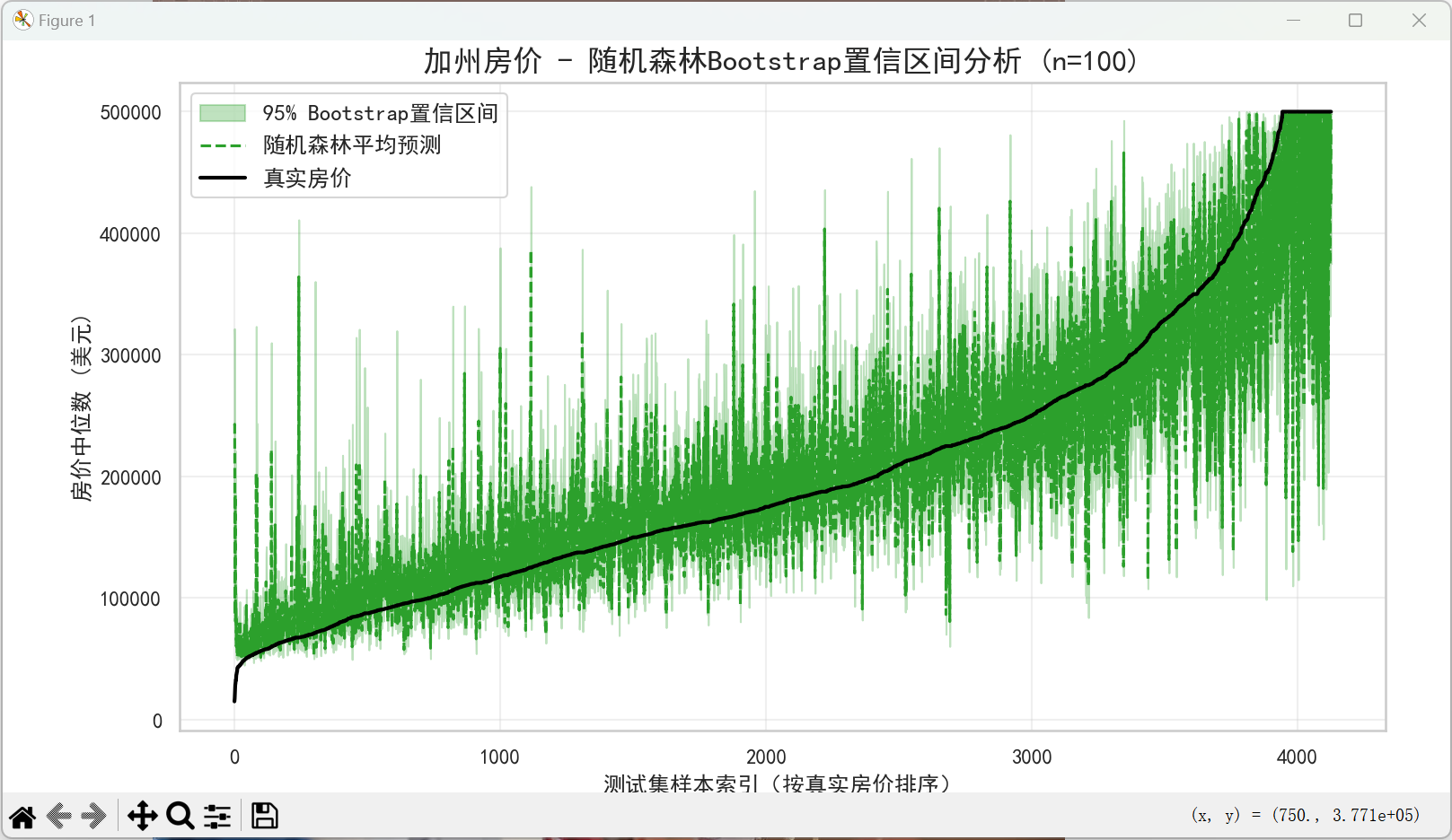
# ====================== 6. Bootstrap置信区间(随机森林) ======================
print("\n===== 随机森林Bootstrap置信区间计算 =====")
# 选择性能最优的随机森林模型做Bootstrap
n_bootstraps = 100 # 100次重采样
bootstrap_preds = []
# 进度提示
print(f"正在进行{n_bootstraps}次Bootstrap重采样...")
for i in range(n_bootstraps):
if i % 10 == 0:
print(f"进度: {i}/{n_bootstraps}", end='\r')
# 重采样训练集(有放回)
X_boot, y_boot = resample(X_train, y_train, random_state=i)
# 训练随机森林
rf_boot = RandomForestRegressor(n_estimators=50, random_state=42, max_depth=15)
rf_boot.fit(X_boot, y_boot)
# 预测测试集
y_pred_boot = rf_boot.predict(X_test)
bootstrap_preds.append(y_pred_boot)
print(f"\nBootstrap完成!")
# 转换为矩阵
bootstrap_preds = np.array(bootstrap_preds)
# 计算95%置信区间
ci_lower = np.percentile(bootstrap_preds, 2.5, axis=0) # 下分位数
ci_upper = np.percentile(bootstrap_preds, 97.5, axis=0) # 上分位数
mean_pred = np.mean(bootstrap_preds, axis=0) # 平均预测值
# 排序绘制带状图
plot_df = pd.DataFrame({
'y_true': y_test.values,
'y_pred_mean': mean_pred,
'ci_lower': ci_lower,
'ci_upper': ci_upper
}).sort_values(by='y_true').reset_index(drop=True)
# 绘制置信区间带状图
plt.figure(figsize=(16, 8))
# 95%置信区间阴影
plt.fill_between(
plot_df.index, plot_df['ci_lower'], plot_df['ci_upper'],
color='#2ca02c', alpha=0.3, label='95% Bootstrap置信区间'
)
# 平均预测线
plt.plot(
plot_df.index, plot_df['y_pred_mean'],
color='#2ca02c', linewidth=1.5, linestyle='--', label='随机森林平均预测'
)
# 真实值基准线
plt.plot(
plot_df.index, plot_df['y_true'],
color='black', linewidth=2, label='真实房价'
)
# 图表装饰
plt.title(f'加州房价 - 随机森林Bootstrap置信区间分析 (n={n_bootstraps})', fontsize=16)
plt.xlabel('测试集样本索引(按真实房价排序)', fontsize=12)
plt.ylabel('房价中位数 (美元)', fontsize=12)
plt.legend(loc='upper left', fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
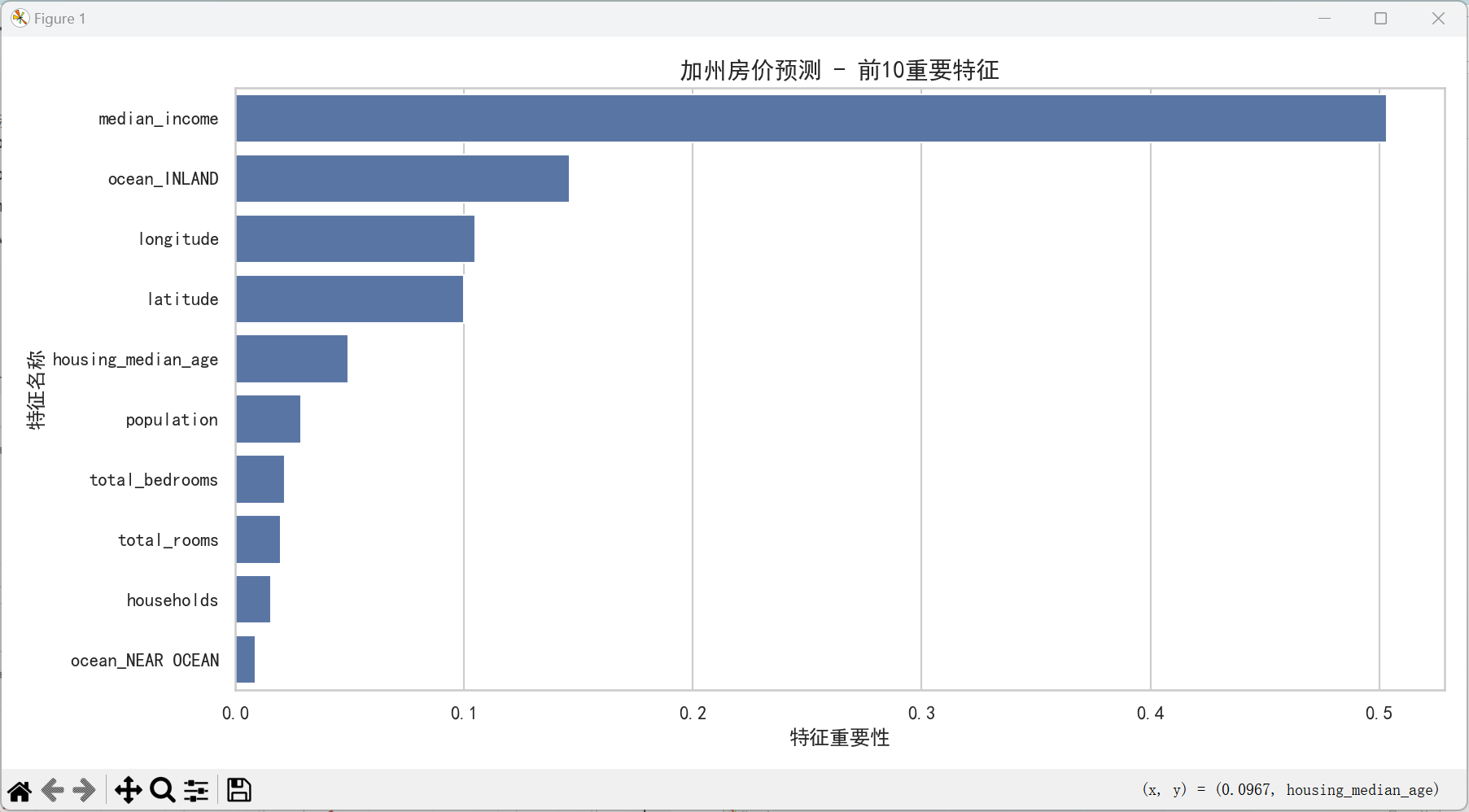
# ====================== 7. 特征重要性分析(随机森林) ======================
# 提取随机森林模型的特征重要性
rf_model = regressors["随机森林回归"]
feature_importance = pd.DataFrame({
'特征名称': X.columns,
'重要性': rf_model.feature_importances_
}).sort_values(by='重要性', ascending=False)
# 绘制特征重要性
plt.figure(figsize=(12, 6))
sns.barplot(x='重要性', y='特征名称', data=feature_importance.head(10))
plt.title('加州房价预测 - 前10重要特征', fontsize=14)
plt.xlabel('特征重要性', fontsize=12)
plt.ylabel('特征名称', fontsize=12)
plt.tight_layout()
plt.show()
===== 加州房价数据集基本信息 =====
数据形状: (20640, 10)
数据前5行:
longitude latitude housing_median_age total_rooms total_bedrooms population households median_income median_house_value ocean_proximity
0 -122.23 37.88 41.0 880.0 129.0 322.0 126.0 8.3252 452600.0 NEAR BAY
1 -122.22 37.86 21.0 7099.0 1106.0 2401.0 1138.0 8.3014 358500.0 NEAR BAY
2 -122.24 37.85 52.0 1467.0 190.0 496.0 177.0 7.2574 352100.0 NEAR BAY
3 -122.25 37.85 52.0 1274.0 235.0 558.0 219.0 5.6431 341300.0 NEAR BAY
4 -122.25 37.85 52.0 1627.0 280.0 565.0 259.0 3.8462 342200.0 NEAR BAY
数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20640 non-null float64
1 latitude 20640 non-null float64
2 housing_median_age 20640 non-null float64
3 total_rooms 20640 non-null float64
4 total_bedrooms 20433 non-null float64
5 population 20640 non-null float64
6 households 20640 non-null float64
7 median_income 20640 non-null float64
8 median_house_value 20640 non-null float64
9 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
None
缺失值统计:
longitude 0
latitude 0
housing_median_age 0
total_rooms 0
total_bedrooms 207
population 0
households 0
median_income 0
median_house_value 0
ocean_proximity 0
dtype: int64
数值特征统计:
longitude latitude housing_median_age total_rooms total_bedrooms population households median_income median_house_value
count 20640.000000 20640.000000 20640.000000 20640.000000 20433.000000 20640.000000 20640.000000 20640.000000 20640.000000
mean -119.569704 35.631861 28.639486 2635.763081 537.870553 1425.476744 499.539680 3.870671 206855.816909
std 2.003532 2.135952 12.585558 2181.615252 421.385070 1132.462122 382.329753 1.899822 115395.615874
min -124.350000 32.540000 1.000000 2.000000 1.000000 3.000000 1.000000 0.499900 14999.000000
25% -121.800000 33.930000 18.000000 1447.750000 296.000000 787.000000 280.000000 2.563400 119600.000000
50% -118.490000 34.260000 29.000000 2127.000000 435.000000 1166.000000 409.000000 3.534800 179700.000000
75% -118.010000 37.710000 37.000000 3148.000000 647.000000 1725.000000 605.000000 4.743250 264725.000000
max -114.310000 41.950000 52.000000 39320.000000 6445.000000 35682.000000 6082.000000 15.000100 500001.000000
预处理后特征维度:(20640, 12)
训练集大小:(16512, 12), 测试集大小:(4128, 12)
===== 模型训练与评估 =====
线性回归 训练完成 | R2: 0.6254 | RMSE: 70060.52 | MAE: 50670.74
决策树回归 训练完成 | R2: 0.7119 | RMSE: 61444.63 | MAE: 40772.48
随机森林回归 训练完成 | R2: 0.8129 | RMSE: 49512.62 | MAE: 32240.31
梯度提升回归 训练完成 | R2: 0.8267 | RMSE: 47652.70 | MAE: 31184.42
===== 模型性能排行榜 =====
模型名称 R2得分 RMSE MAE
3 梯度提升回归 0.8267 47652.70 31184.42
2 随机森林回归 0.8129 49512.62 32240.31
1 决策树回归 0.7119 61444.63 40772.48
0 线性回归 0.6254 70060.52 50670.74
===== 随机森林Bootstrap置信区间计算 =====
正在进行100次Bootstrap重采样...
进度: 90/100
Bootstrap完成!


















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









