 离散特征的独热编码处理
离散特征的独热编码处理





https://blog.youkuaiyun.com/weixin_45655710?type=blog
@浙大疏锦行
DAY 5 离散特征的处理(独热编码)
知识点回顾:
- 独热编码和填补缺失值的顺序关系
- 部分代码不能跳步执行的原因
题目:离散特征的独热编码
先按照示例代码过一遍,然后完成下列题目
现在在py文件中一次性处理data数据中所有的连续变量和离散变量,注意是py文件中,所以每一步的输出是否正确需要你来使用debugger功能来逐步查看
- 读取data数据
- 填补缺失值(离散+连续)
- 对离散变量进行one-hot编码
- 对独热编码后的变量转化为int类型
注意: 这里区分离散变量仅仅通过object类型,实际中还需要结合对数据的认识,这里为了方便没有考虑现实意义。
课后作业: 尝试按照正确的逻辑来处理下,借助AI理解下如何操作。
小提示: 可以把之前的所有代码按照顺序(删除冗余部分)整理到一个单元格中,让ai修改逻辑即可。
# 导入必要库
import pandas as pd
import warnings
warnings.filterwarnings('ignore') # 忽略无关警告
def preprocess_data(file_path):
"""
完整的数据预处理流程:处理连续变量和离散变量
步骤:1.读取数据 → 2.填补缺失值(连续+离散)→ 3.独热编码 → 4.转换int类型
"""
# -------------------------- 1. 读取数据 --------------------------
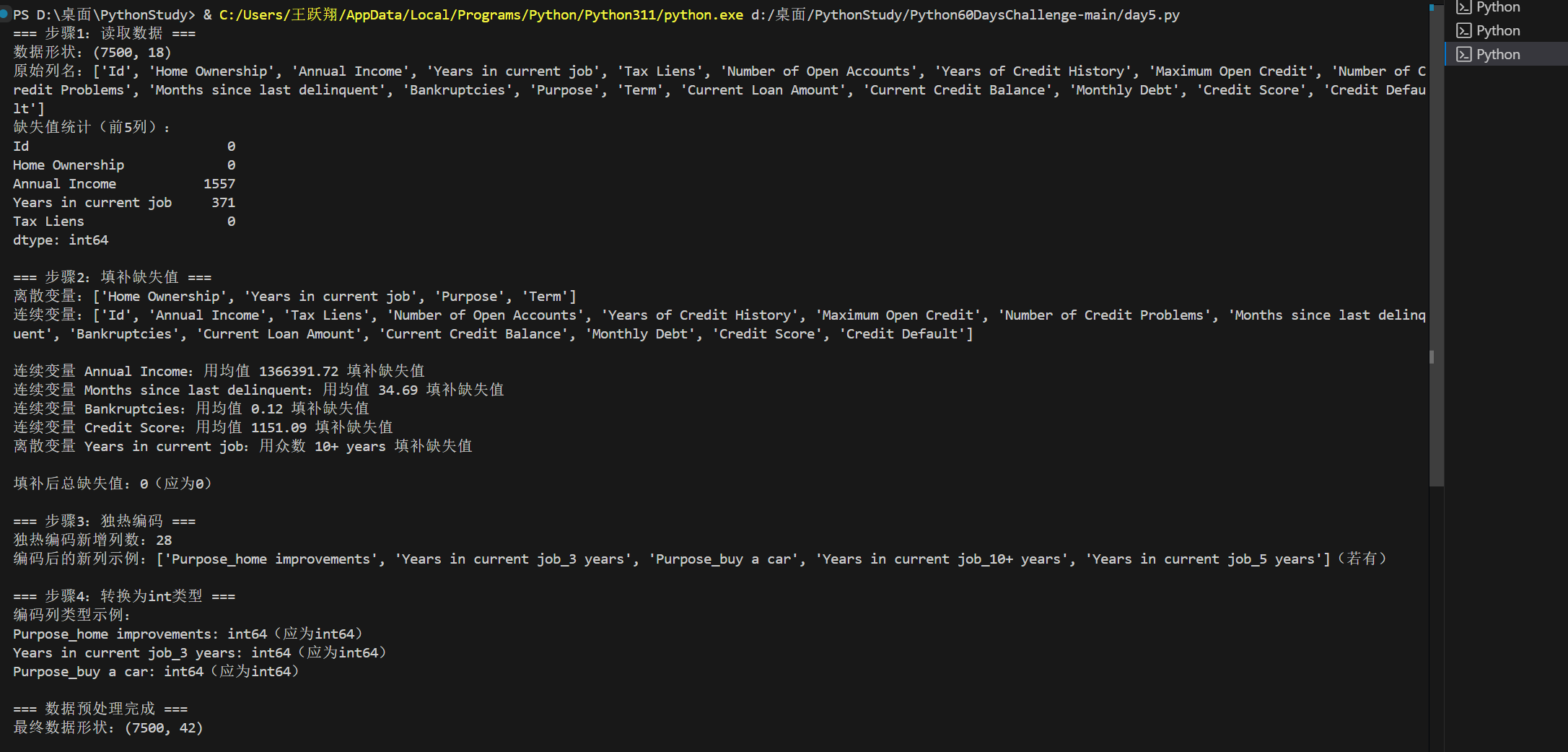
print("=== 步骤1:读取数据 ===")
data = pd.read_csv(file_path)
# 调试:查看数据基本信息(可通过debugger观察)
print(f"数据形状:{data.shape}")
print(f"原始列名:{list(data.columns)}")
print(f"缺失值统计(前5列):\n{data.isnull().sum().head()}\n")
# -------------------------- 2. 填补缺失值(连续+离散)--------------------------
print("=== 步骤2:填补缺失值 ===")
# 区分连续变量(非object类型)和离散变量(object类型)
discrete_cols = [col for col in data.columns if data[col].dtype == 'object']
continuous_cols = [col for col in data.columns if data[col].dtype != 'object']
print(f"离散变量:{discrete_cols}")
print(f"连续变量:{continuous_cols}\n")
# 填补连续变量缺失值:用均值(数值型数据的常用填充方式)
for col in continuous_cols:
if data[col].isnull().sum() > 0:
mean_val = data[col].mean()
data[col].fillna(mean_val, inplace=True)
print(f"连续变量 {col}:用均值 {mean_val:.2f} 填补缺失值")
# 填补离散变量缺失值:用众数(类别型数据的常用填充方式)
for col in discrete_cols:
if data[col].isnull().sum() > 0:
mode_val = data[col].mode()[0] # mode()返回Series,取第一个众数
data[col].fillna(mode_val, inplace=True)
print(f"离散变量 {col}:用众数 {mode_val} 填补缺失值")
# 调试:确认缺失值已填补完成
missing_after = data.isnull().sum().sum()
print(f"\n填补后总缺失值:{missing_after}(应为0)\n")
# -------------------------- 3. 对离散变量进行one-hot编码 --------------------------
print("=== 步骤3:独热编码 ===")
# 保存编码前的列名(用于后续筛选编码后的新列)
cols_before_encoding = set(data.columns)
# 独热编码:drop_first=True避免多重共线性(可选,根据需求调整)
data = pd.get_dummies(data, columns=discrete_cols, drop_first=True)
# 调试:查看编码后的变化
cols_after_encoding = set(data.columns)
encoded_cols = list(cols_after_encoding - cols_before_encoding) # 编码后的新列
print(f"独热编码新增列数:{len(encoded_cols)}")
print(f"编码后的新列示例:{encoded_cols[:5]}(若有)\n")
# -------------------------- 4. 对独热编码后的变量转化为int类型 --------------------------
print("=== 步骤4:转换为int类型 ===")
# 独热编码后的列默认是bool/uint8,统一转为int
for col in encoded_cols:
data[col] = data[col].astype(int)
# 调试:确认编码列类型正确
print(f"编码列类型示例:")
for col in encoded_cols[:3]: # 打印前3个编码列的类型
print(f"{col}: {data[col].dtype}(应为int64)")
print("\n=== 数据预处理完成 ===")
print(f"最终数据形状:{data.shape}")
return data
# -------------------------- 主程序执行 --------------------------
if __name__ == "__main__":
# 请替换为你的data.csv文件路径(相对路径或绝对路径均可)
DATA_PATH = r"D:\桌面\PythonStudy\Python60DaysChallenge-main\data.csv"
# 执行预处理
processed_data = preprocess_data(DATA_PATH)
# 可选:保存预处理后的数据(方便后续使用)
processed_data.to_csv("processed_data.csv", index=False)
print("\n预处理后的数据已保存为 processed_data.csv")
关键说明(确保正确执行)
| 类别 | 说明 |
|---|---|
| 文件路径 | 请将 DATA_PATH 替换为你本地 data.csv 的实际路径(Windows系统注意用 r 开头避免转义字符问题)。 |
| 逻辑正确性 | 严格遵循「先填补缺失值,后独热编码」,避免编码后填充导致的逻辑错误。 |
| 缺失值填充规则 | - 连续变量(数值型):用「均值」填充(符合数值分布特性)。 - 离散变量(类别型):用「众数」填充(符合类别分布特性)。 |
| 独热编码细节 | drop_first=True 会删除每个离散变量的第一个类别(避免多重共线性),若需保留全部类别,可改为 drop_first=False。 |
| 调试要点 | - 用 print 语句查看每一步的输出(如数据形状、缺失值数量、列类型)。- 若使用PyCharm等IDE,可在关键步骤(如填补后、编码后)设置断点,通过debugger查看 data 的具体内容。 |
如何运行和调试
- 将上述代码保存为
data_preprocessing.py文件。 - 确保已安装 pandas:
pip install pandas。 - 运行脚本:直接双击文件,或在终端执行
python data_preprocessing.py。 - 调试步骤(以 PyCharm 为例):
- 在
data = pd.read_csv(file_path)行设置第一个断点。 - 右键选择「Debug ‘data_preprocessing’」。
- 按「Step Over(F8)」逐步执行,观察
data变量的变化(在「Variables」窗口查看)。
- 在

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









