




📘
一、什么是 Kernel Panic?
Kernel Panic 是 Linux 内核在遇到不可恢复错误时采取的一种保护机制。类似于用户态程序崩溃(Segmentation Fault),但 Panic 发生在内核态,意味着整个系统处于无法继续执行的状态。
典型表现包括:
- 串口或屏幕打印出大量堆栈信息;
- 系统卡死无法响应;
- 有时会重启,取决于内核配置。
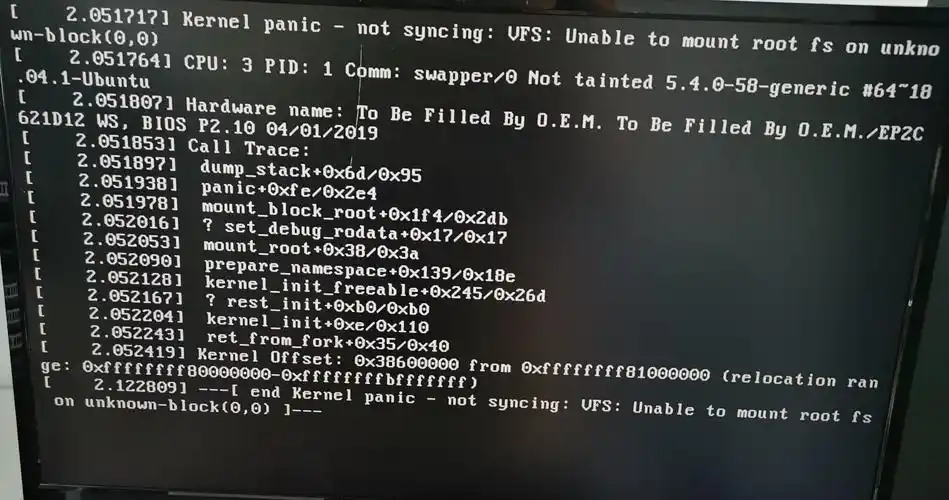
二、常见 Kernel Panic 分类与分析
| Panic 类型 | 本质概念说明 |
|---|---|
| Null pointer dereference | 解引用空指针(即访问指向 NULL 的内存) |
| Kernel paging request error | 访问了非法地址,常见为用户态误传指针给内核、越界访问 |
| stack overflow / 栈空 / 栈溢出 | 内核栈空间被递归或大数据结构撑爆,或者函数返回路径错误导致“栈帧清空” |
| BUG_ON / WARN_ON | 内核主动调用 BUG_ON(condition) 强制中止执行(调试时常用) |
| Watchdog timeout | 某任务长时间无响应,系统认为“卡死”,触发超时重启 |
| 死锁 / 竞争 | 同一资源多任务争用导致系统阻塞 |
| OOM(内存不足) | Out-of-Memory 触发 panic 或进程被 kill |
| 初始化失败 | 驱动加载或平台初始化错误,可能无法继续启动 |
三、术语解释(针对初学者常见困惑)
✅ 1. 什么是“栈空”?什么又是“栈溢出”?
- 栈(stack) 是函数调用的临时变量与返回地址的保存区,属于线程私有区域,位于内存高地址区域。
- 栈溢出(stack overflow):函数递归太深,或局部变量太大,把整个栈顶端撑爆。内核的栈大小通常只有 4K~16K,很容易溢出。
- 栈空(stack underflow):函数调用过程中栈帧未按预期压栈或返回,导致返回地址丢失,从而“跳”到不可预测位置。
📌 举例说明:
void foo() {
foo(); // 无限递归,堆叠函数栈帧 -> stack overflow
}
✅ 2. 什么是“迭代 / 递归”?为什么会引发 panic?
-
递归:函数调用自身,适合处理树形、图结构等自包含数据结构;
-
若递归终止条件写错,会形成“死递归”,造成栈溢出。
-
迭代:使用
while或for等语句反复处理数据,不会产生新的栈帧,内存更安全。
📌 示例:
void dfs(struct node *n) {
if (!n) return;
dfs(n->left);
dfs(n->right);
}
// 如果节点链表出现环,终止条件永远不成立,堆栈爆炸!
✅ 3. 什么是 BUG_ON()?
BUG_ON(condition) 是一种内核内部的断言机制。若 condition 为 true,系统立即触发 panic,打印调用栈,停止内核。
BUG_ON(ptr == NULL);
通常用于调试阶段防御异常状态,生产环境应谨慎使用,否则可能导致轻微错误变成系统性崩溃。
✅ 4. 什么是“非法内存访问”?
内核不能随意访问任意内存区域,否则会破坏整个系统的稳定性。
- 访问未映射物理页(如空指针、地址越界);
- 使用未初始化结构体字段指针;
- 传入用户空间地址未经过校验。
这些都会触发如下 panic 日志:
Unable to handle kernel NULL pointer dereference at virtual address 0x00000000
四、实战案例讲解(更注重初学者视角)
🎯 案例一:Null 指针访问导致的 panic
- 现象:系统刚启动访问 at24 EEPROM 就 panic
- 代码片段:
struct eeprom *e = i2c_get_clientdata(client);
if (e->size > 1024) { ... } // e 是 NULL
-
分析方法:
- 查看
/sys/kernel/debug/tracing/trace使用function_graph; - 确认
i2c_set_clientdata()是否在 probe 中执行;
- 查看
-
修复建议:所有指针使用前都应检查是否为 NULL!
🎯 案例二:递归过深造成 stack overflow
-
现象:kernel panic,日志显示 stack overflow
-
分析方法:
- 编写简单递归链表扫描函数,若链表结构异常(如自环)会无限递归;
- 用
CONFIG_DEBUG_STACKOVERFLOW启用内核栈溢出检测;
-
处理建议:替换为迭代式写法,或增加检查环路机制。
🎯 案例三:SLAB 内存耗尽引发 OOM
-
现象:系统运行一段时间 panic,
slabtop显示某缓存占用 90%+ -
日志信息:
Out of memory: Kill process 456 (daemon) score 1090 or sacrifice child -
分析手段:
slabtop实时分析缓存如dentry,inode_cache;- 清理缓存:
echo 3 > /proc/sys/vm/drop_caches
🎯 案例四:Watchdog 超时触发 panic
-
现象:系统运行一段时间重启,dmesg 出现 watchdog timeout
-
分析:
- 任务死锁、调度器饥饿,长时间无法响应
-
调试方式:
- 开启调度器追踪
echo 1 > /proc/sys/kernel/sched_debug - 使用
perf sched或ftrace分析任务执行路径
- 开启调度器追踪
五、建议与调试组合工具表
| 工具 | 使用说明 |
|---|---|
ftrace | 分析函数路径,定位哪个函数导致 panic |
slabtop | 查看内存分配器(SLAB)实时使用情况 |
dmesg | 捕获 panic 前的系统内核日志信息 |
crash vmcore | 使用 crash 分析 vmcore 堆栈和内存结构 |
lockdep | 分析死锁、锁顺序冲突 |
KASAN/KFENCE | 内核空间的内存访问越界动态检测 |
六、总结
Linux 内核 Panic 的问题广泛但有迹可循。每一类 Panic 背后都对应某种编程模型的不当使用:
- 指针未检查 ➜ NULL deref
- 递归结构未限制 ➜ 栈溢出
- 资源分配未回收 ➜ 内存耗尽
- 同步模型不清晰 ➜ 死锁或卡顿
📌 学会使用 ftrace, slabtop, crash, lockdep 等工具,配合构建良好的模块设计与防御性编程,是避免 panic 的核心策略。

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









