




 本文解析了裁判文书网的爬虫难点,包括vl5x、number、guid参数的生成规则,尤其是vl5x的实时性和依赖于cookie的特性。介绍了如何通过解密JS代码获取这些参数,并指出了数据加密及解密方法,以及接口限制和应对策略。
本文解析了裁判文书网的爬虫难点,包括vl5x、number、guid参数的生成规则,尤其是vl5x的实时性和依赖于cookie的特性。介绍了如何通过解密JS代码获取这些参数,并指出了数据加密及解密方法,以及接口限制和应对策略。
文书更新有兴趣的可以找我探讨探讨
一、裁判文书网难点:vl5x、number、guid 三个参数(内容、列表抓取必须的参数)。
guid
生成规则页面源码里面找,非常简单,是一段js代码。
number
~~向 http://wenshu.court.gov.cn/ValiCode/GetCode 发送post请求,可得到(参数为guid)~~改版之后此参数不是必须参数 。
vl5x
这个参数比较复杂,服务端生成规则如下:
1>、访问服务端生成cookie
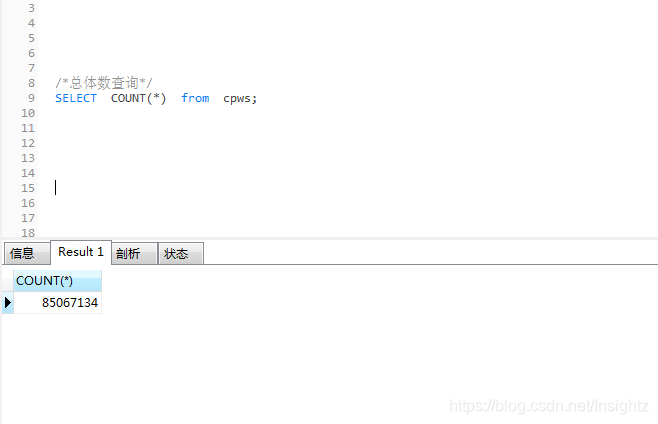
2>、通过js代码对cookie进行一些计算生成vl5x(这个js代码是一个加密函数,策略主要是对cookie中的vjkl5转换为long型数值,然后对一个加密数组长度取余,获取到加密函数对vjkl5加密得到vl5x,所以这里的vl5x具有实时性)。

关于js解密,可使用如下方法:
打开谷歌或者火狐浏览器,然后按 F12,把代码复制进去,
最后,去掉开头 4 个字母 eval 然后回车运行下就得到源码了。
裁判文书解密后全部js
二、带上上面的三个参数,还有cookie,向接口发送请求,顺利拿到数据(此处成立的条件是服务端计算出来的vl5x值和你提交的一致),注意此处用于计算vl5x的cookie和发送post请求的cookie要一致。
三、关于数据加密,改版之后接口返回的数据文档ID是加密的字符,解密规则是执行JS中Navi函数,执行之前需要先执行eval(unzip(RunEval)),否则数据解密失败。
四、有个坑,就是接口最多翻100页,也就是最多只能拿到2000条数据,如果想拿到全部数据,可以根据关键词、年份、地域等参数缩小范围。

















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









