




 本文介绍使用Python爬虫抓取裁判文书网数据。先给出网站地址,接着分析该动态网站,找到json接口及post请求参数,破解vl5x和guid参数来源。最后进行代码实现,包括创建项目、配置文件、编写爬虫代码,处理调试错误,成功构造请求参数并获取列表页和详情页数据。
本文介绍使用Python爬虫抓取裁判文书网数据。先给出网站地址,接着分析该动态网站,找到json接口及post请求参数,破解vl5x和guid参数来源。最后进行代码实现,包括创建项目、配置文件、编写爬虫代码,处理调试错误,成功构造请求参数并获取列表页和详情页数据。
1、裁判文书网地址
2、网站分析
(1)网站类型是动态网站。
(2)网页源代码中并没有我们想要的页面内容,且引用许多js代码。
(3)查看列表页是否有专门的json接口。
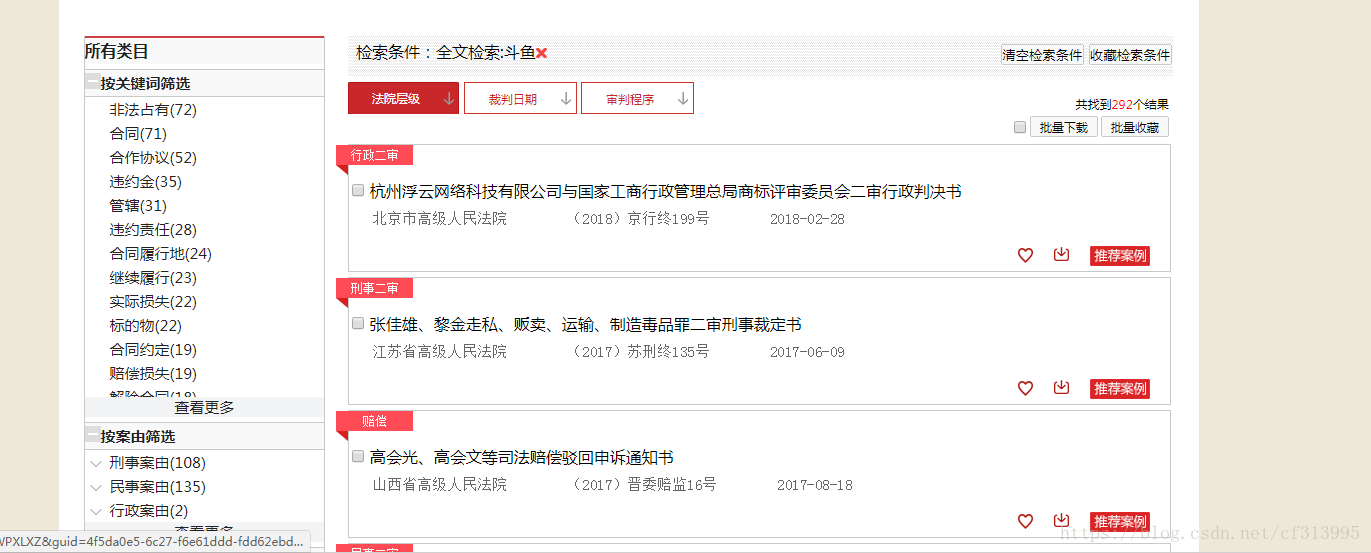
(4)通过开发者工具查看network,发现了一个json接口。即ListContent。
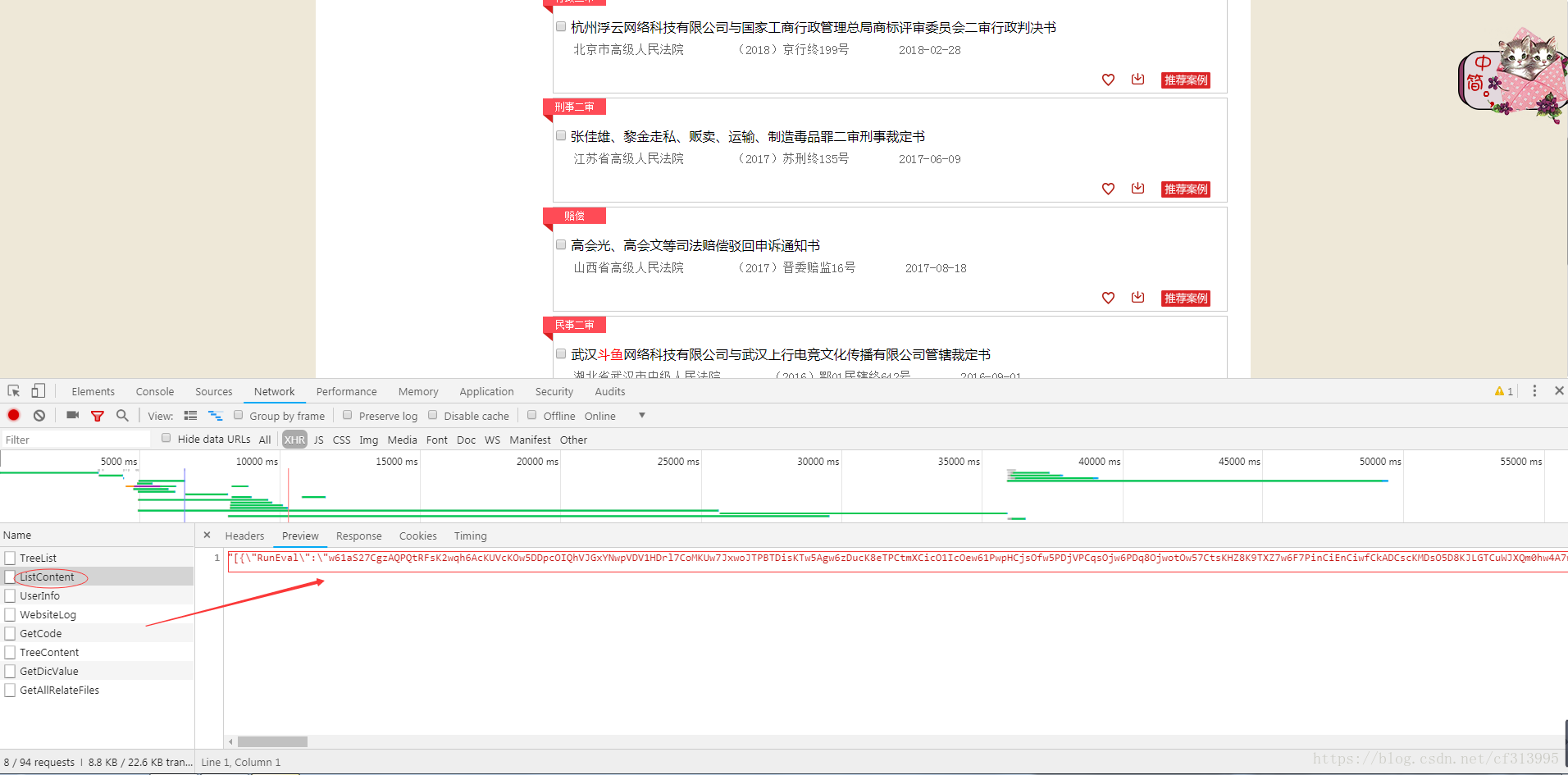
(5)通过研究json接口,发现它是一个post请求。

(6)发现是post请求,我们继续寻找其对应post请求提交的参数。
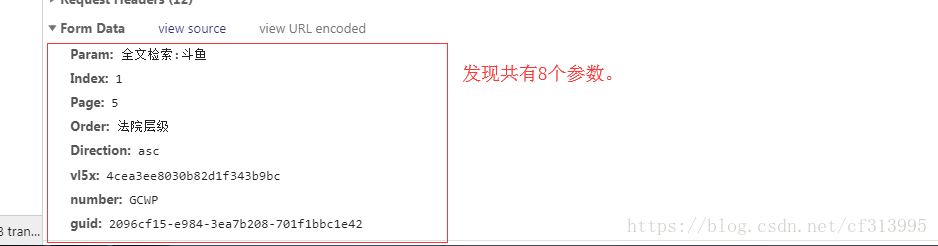
(7)通过分析,Param是我们输入的关键字斗鱼,index为页号,page为一页返回的文书数量,Order为法院层级,Direction为排序(asc为升序),推测这5个为固定参数,剩下3个参数vl5x,number,guid。多次切换页面以及切换关键词后发现number可以算作一个固定参数,只是不同的关键词对应的number不同,暂时假定它为固定参数。此时剩下vl5x和guid这两个参数,我们需要分析出这两个参数的来源,以及参数值是怎么设置的?
(8)根据经验,一般参数来源如下:
(1)、某一个url,它的响应头(Response Headers)内的Set-Cookie字段中,可能会含有一些参数。值得注意的是,需先将网站的cookie数据从浏览器内全部清空,因为cookie有过期时间,如果cookie没有过期之前,服务器是不会将cookie放在Set-Cookie中的。
(2)、从json接口返回的数据中,可能含有后续请求的参数,尤其是翻页参数很常见。
(3)、js加密得到的参数。
- ①简单的js加密,我们可以直接使用python语言将其还原。
- ②在python中执行js代码,execjs(windows下,需安装PyExecJS)直接调用js文件里的函数。
- ③ 异常复杂的js代码,可以考虑app端的信息提取。
(9)根据上述思路,开始寻找vl5x之路。
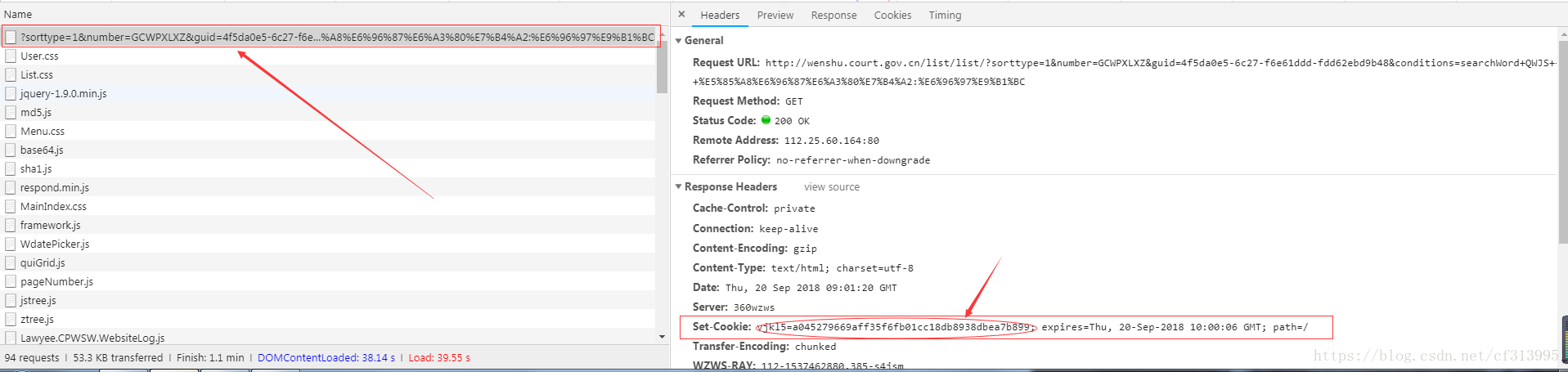
①、首先在network中寻找, 发现
http://wenshu.court.gov.cn/list/list/?sorttype=1&number=GCWPXLXZ&guid=4f5da0e5-6c27-f6e61ddd-fdd62ebd9b48&conditions=searchWord+QWJS+++全文检索:斗鱼
这个地址中,其响应头Set-Cookie:vjkl5=a045279669aff35f6fb01cc18db8938dbea7b899。并不是我们想要寻找的vl5x。
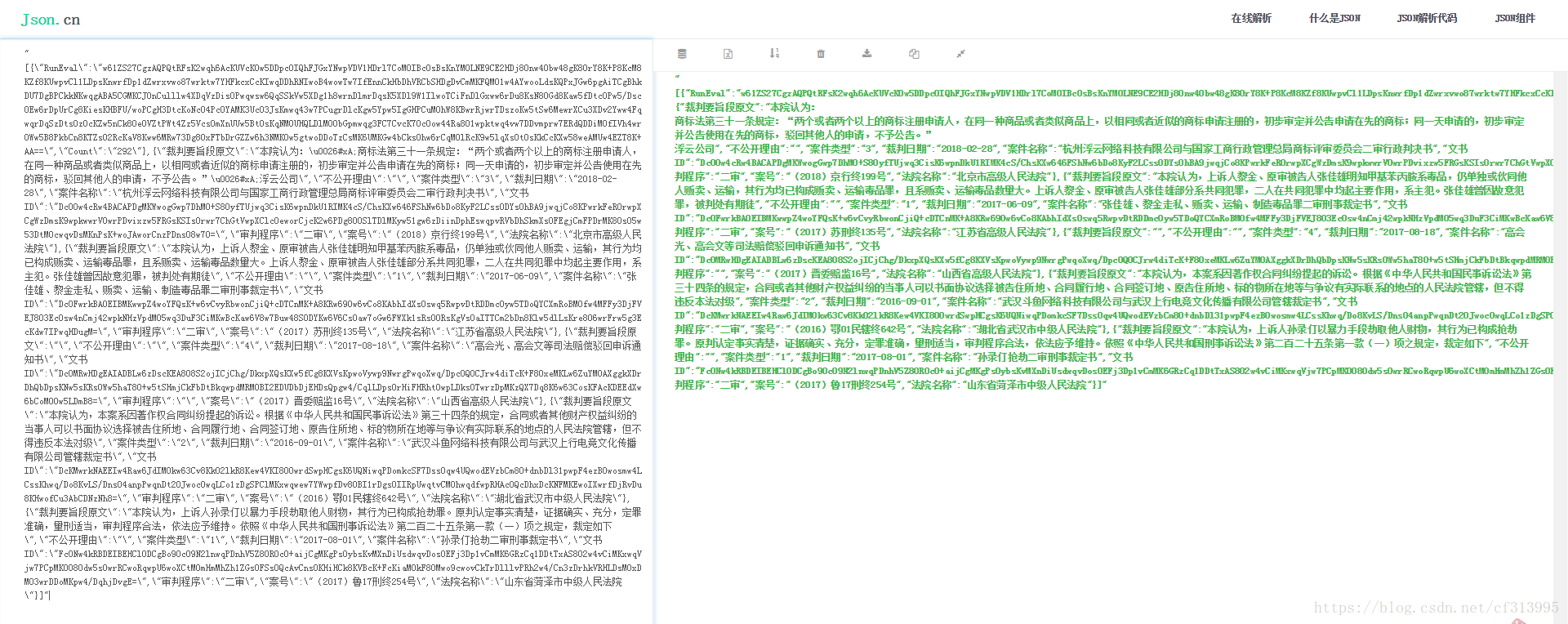
②、其次,查看我们之前从第(4)步里找到的json接口,查看其内容是否含有这些参数。将json响应的内容复制后进行json解析(网址为:https://www.json.cn/),发现并没有这些参数。
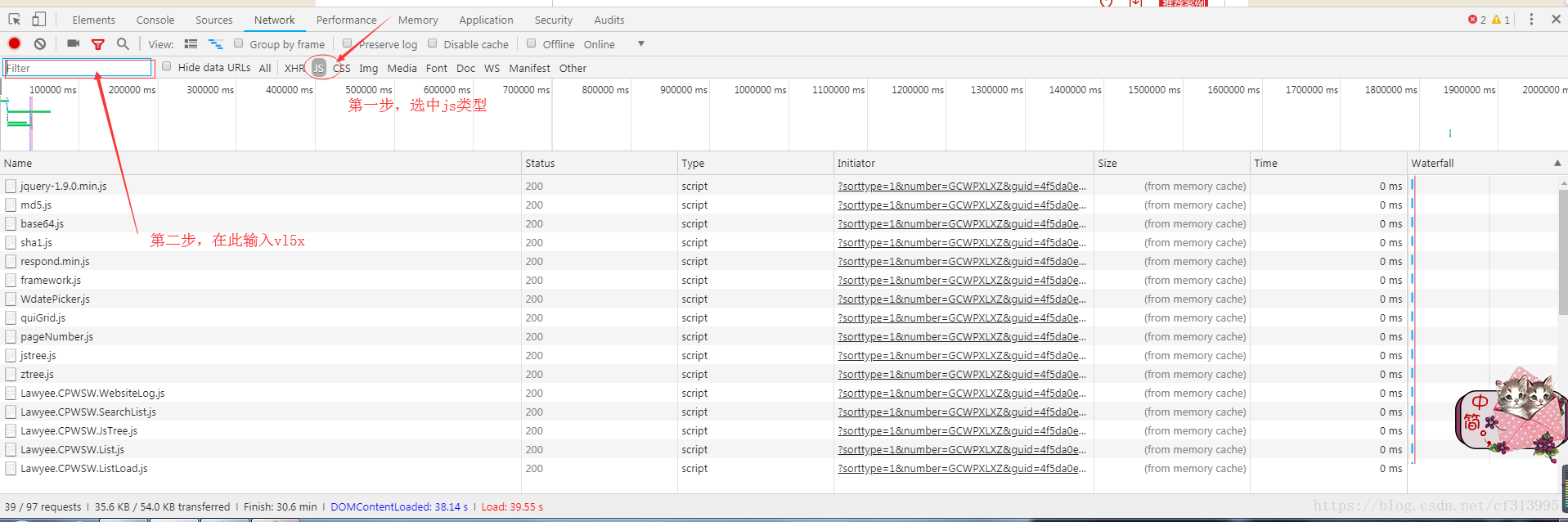
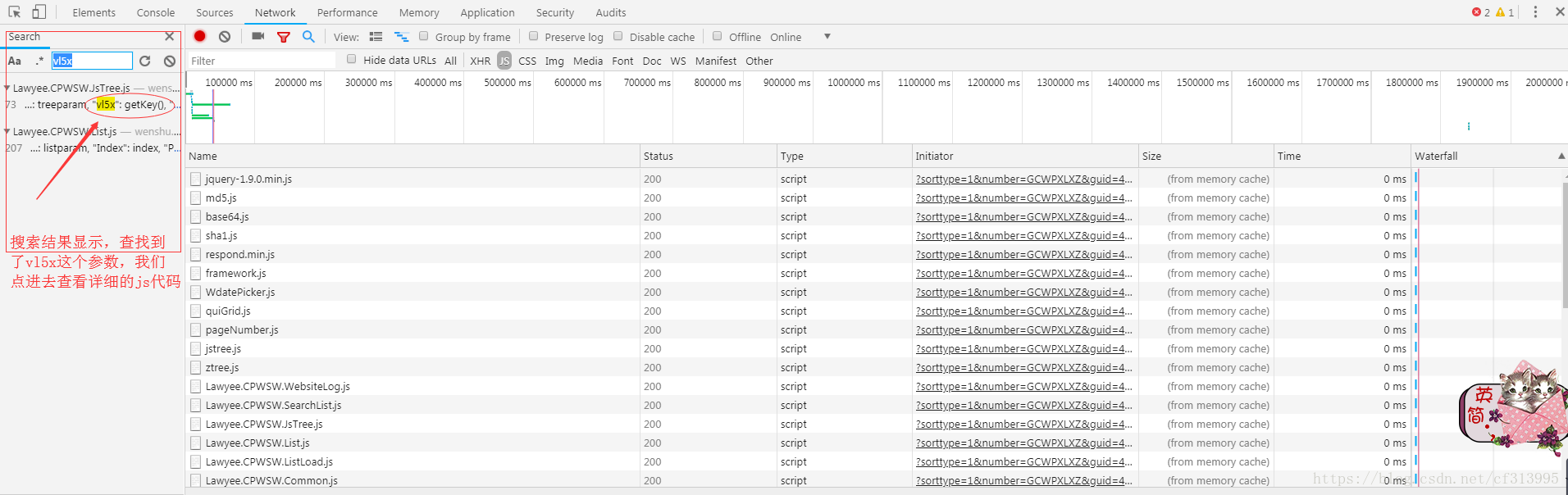
③、此时,以上两步都没有发现vl5x和guid这两个参数。那么我们考虑去js文件中查找这些参数。选中js类型,在filter处输入vl5x进行全局搜索。
④此时发现了vl5x存在于Lawyee.CPWSW.JsTree.js文件中。
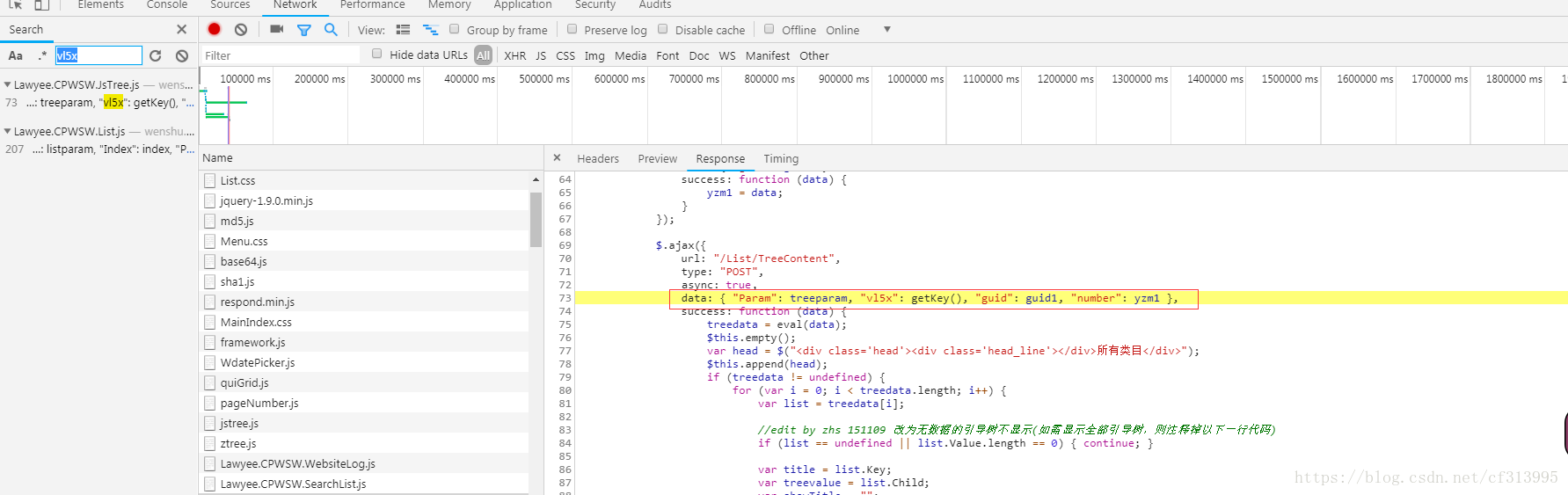
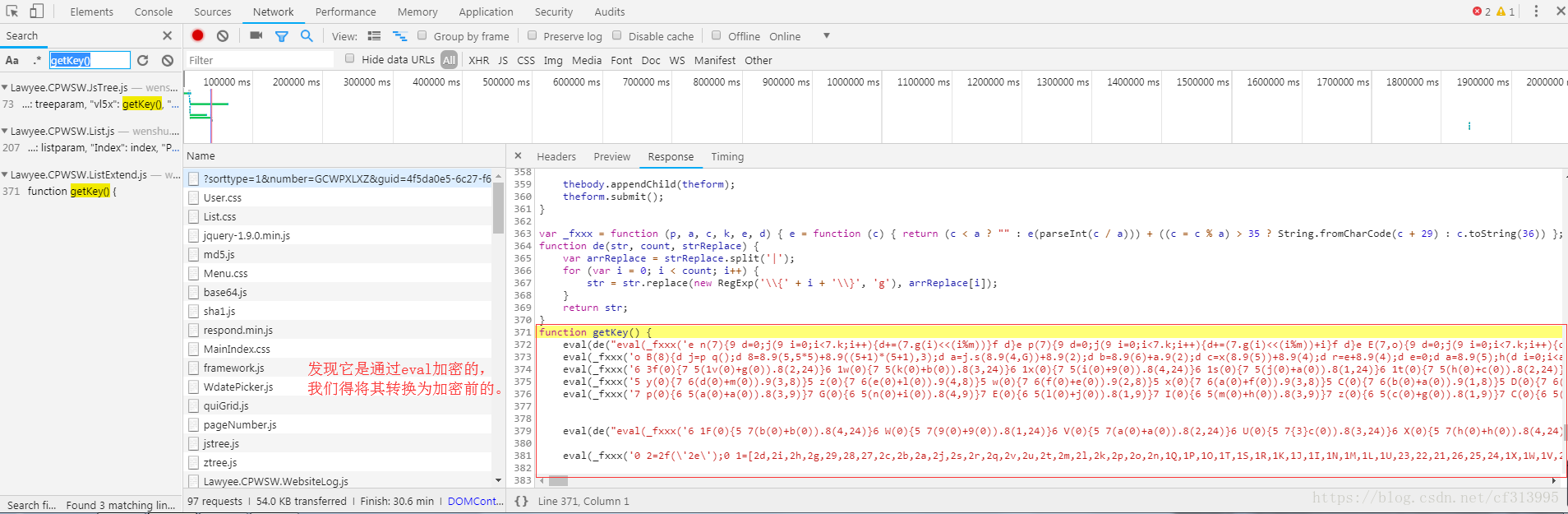
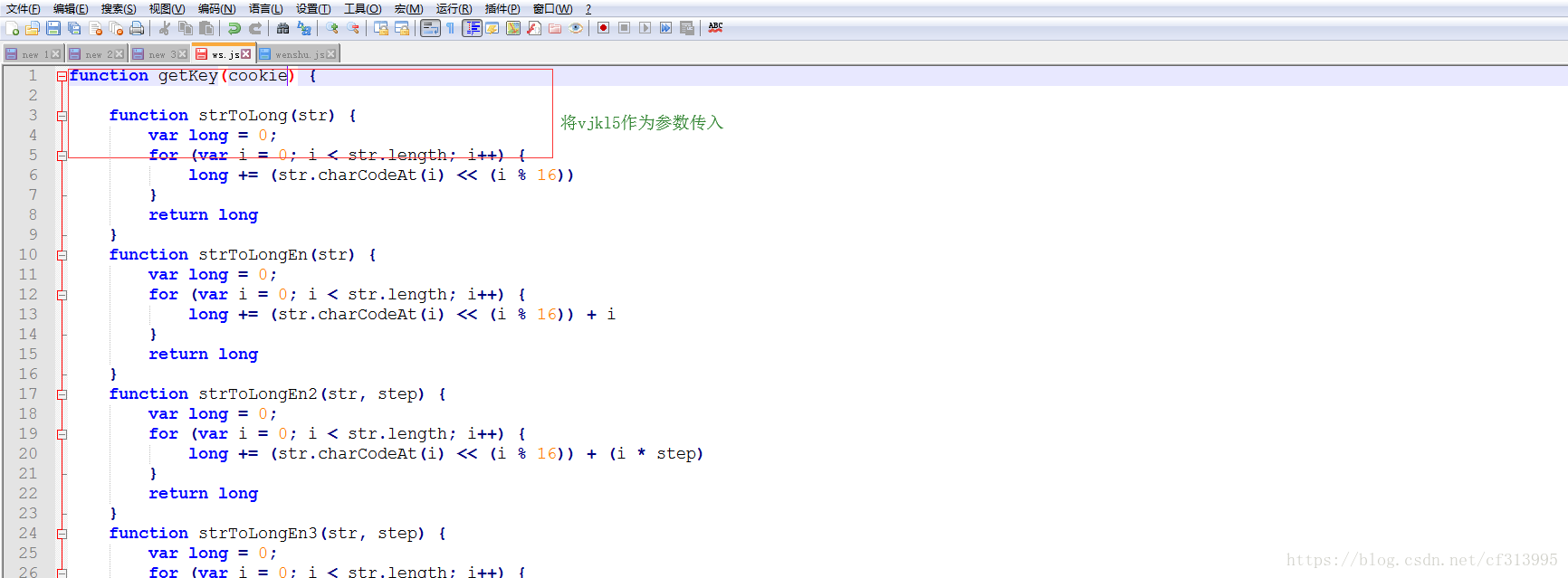
⑤点击进入查看,发现了vl5x是通过getKey()函数加密的 ,guid是通过guid1加密的。
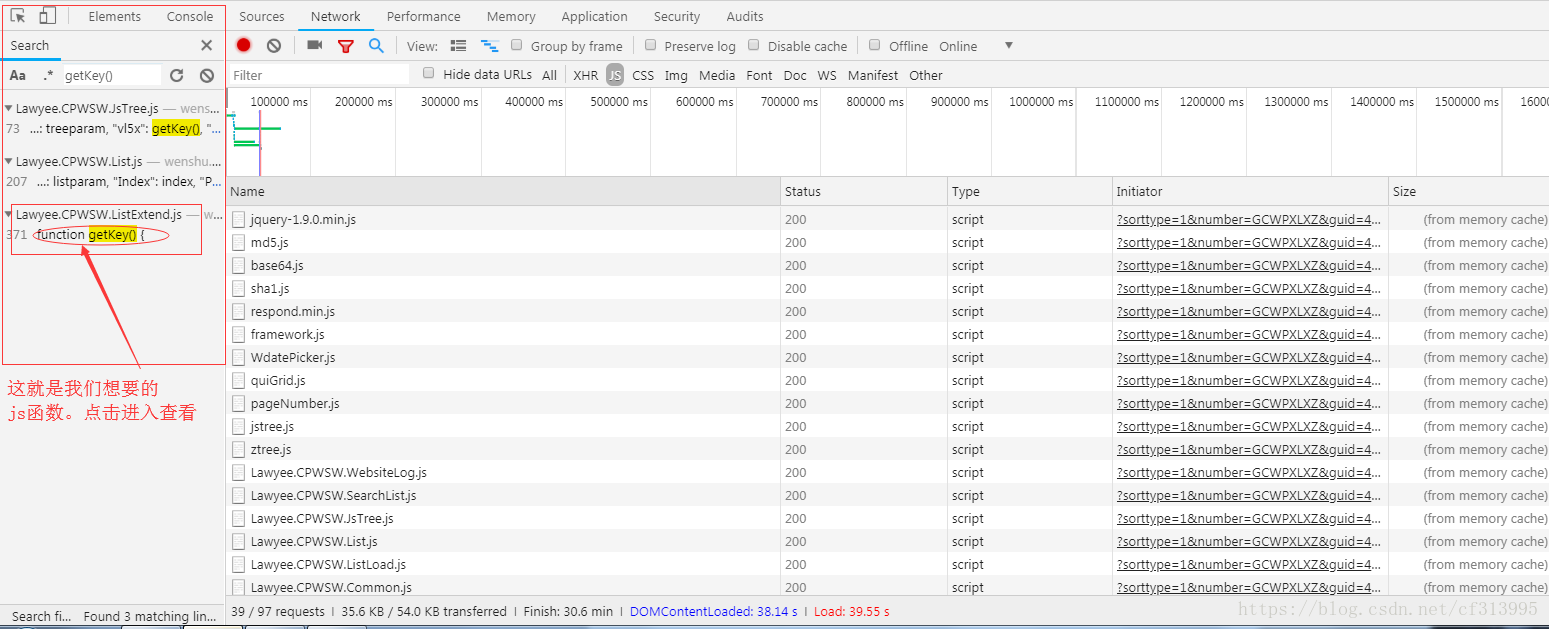
⑥按照第4步的方法,继续全局搜索getKey()函数。点击进入查看。
⑦进去这个函数后,发现getKey()函数是加密过的。
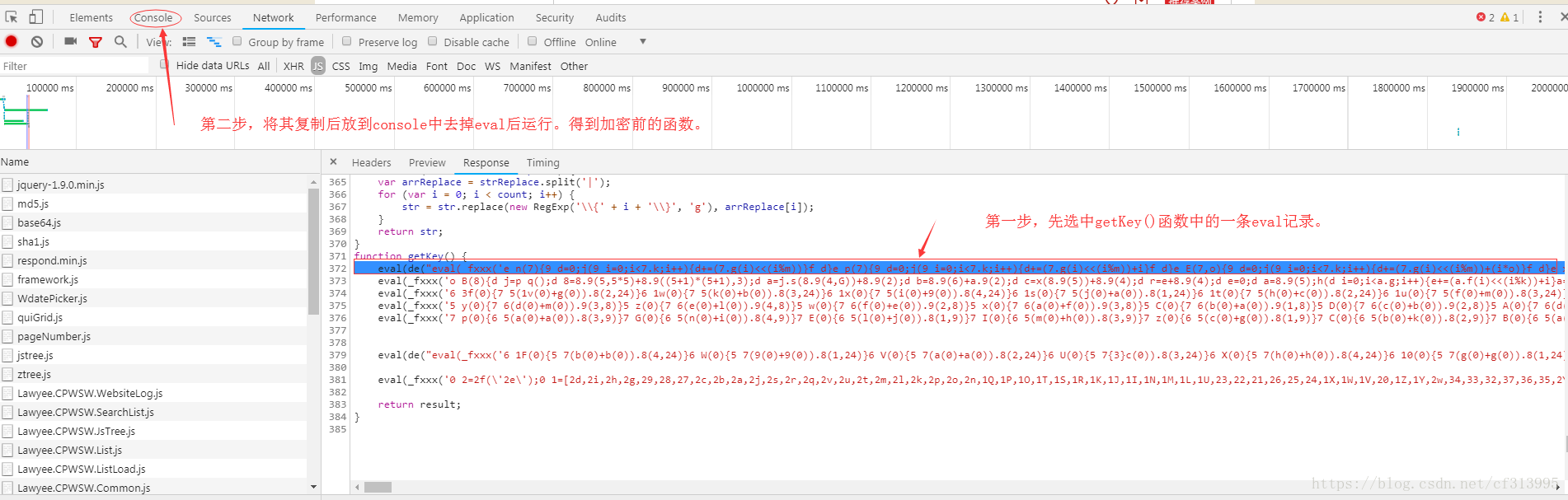
⑧那么我们得将其还原为加密前的函数。选中一个eval函数。复制后放到console中,去掉eval后运行,得到如下结果。
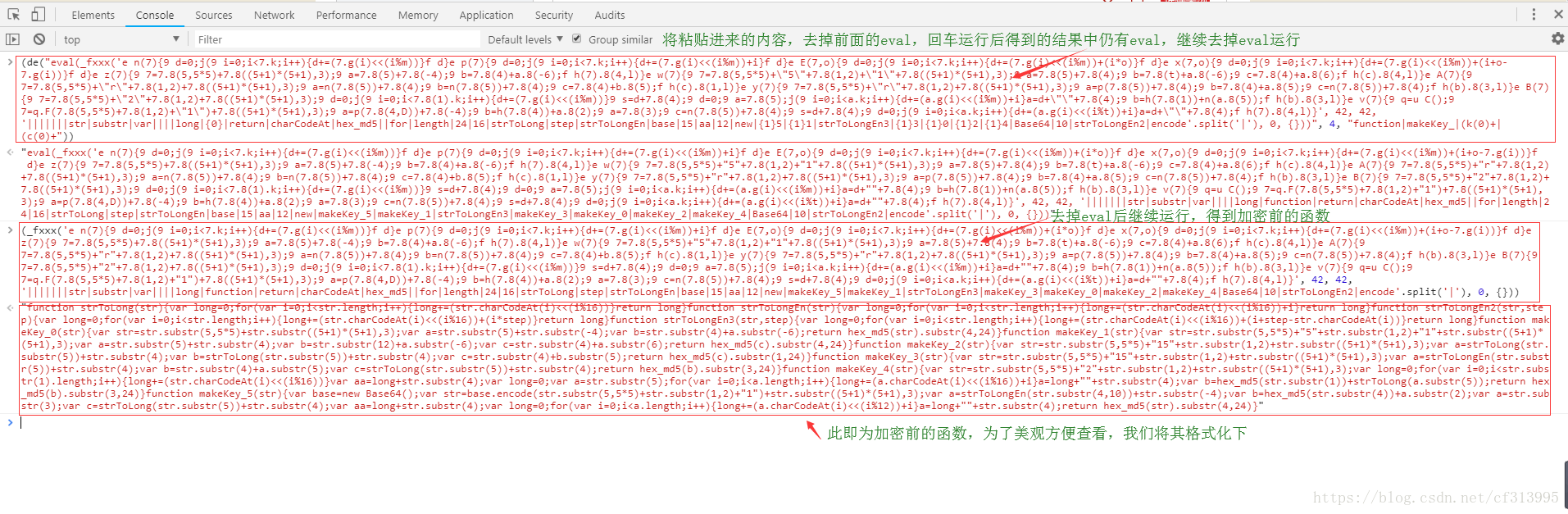
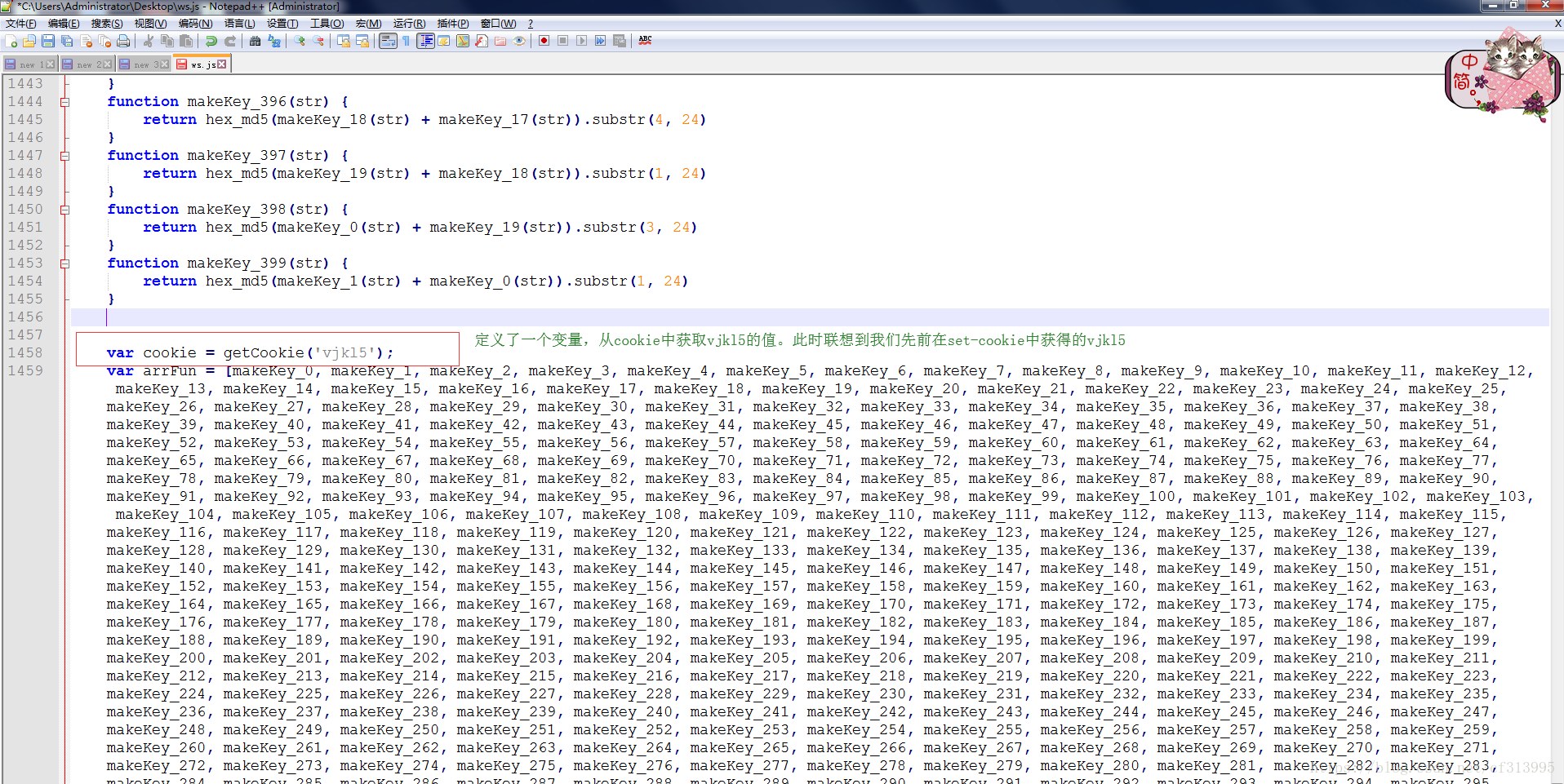
⑨将getKey()函数中的所有eval加密后的内容处理完成后,我们将其放到一个文件中。观察发现:
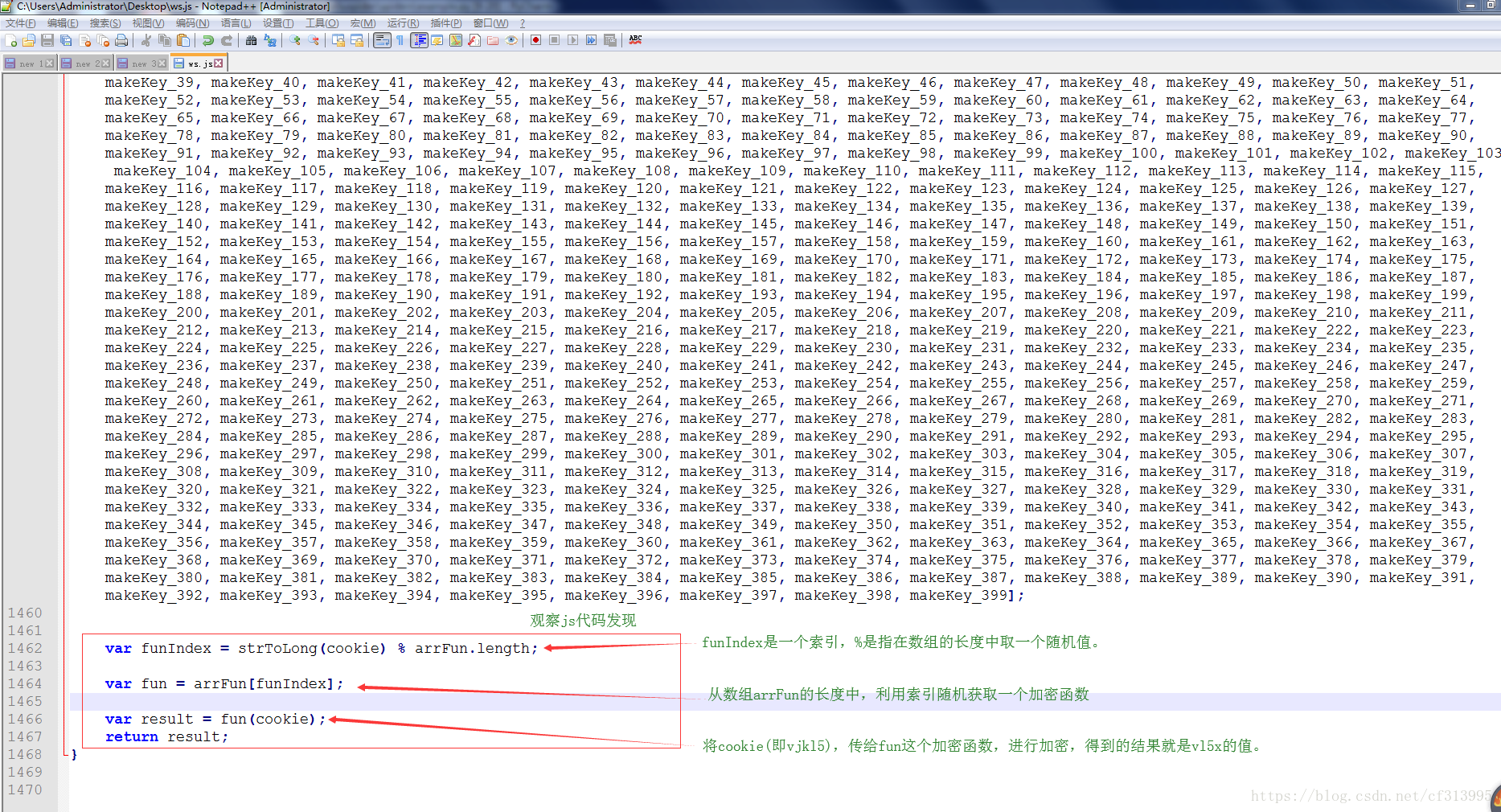
⑩此时我们发现,从第①步获取到的vjkl5此时派上了用场。那么我们注释掉其中的var cookie = getCookie(‘vjkl5’);把vjkl5作为一个参数传递给getKey()函数。
⑪那么vl5x有了,只剩下guid的值了。回到第6步,我们发现guid的值:guid=772785a4-40d0-2fbfa255-e60616a6de83,其加密方法时guid1,这种格式让我们想到python中内置的uuid模块。其uuid1的加密方法似乎和guid的值得是一样的。
那我们来验证下。
⑦现在对比uuid1的值和guid的值。发现他们大同小异。假设他们一样,那么所有参数破解完后,我们开始实现代码。

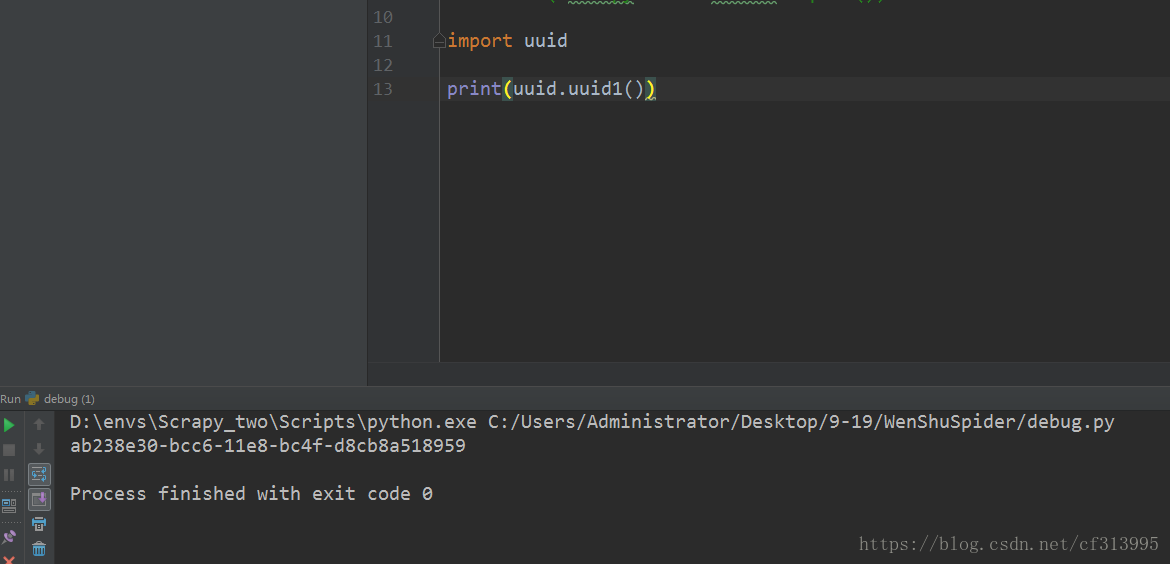
uuid1=ab238e30-bcc6-11e8-bc4f-d8cb8a518959
guid =772785a4-40d0-2fbfa255-e60616a6de83
3、代码实现
1、温馨提示
(1)、此处假设你已经懂得scrapy的基础知识,并能够做一些基本的代码编写,那么请往下走。
2、创建项目
(1)通过scrapy相关命令创建项目,同时在项目的根目录下新建一个debug.py文件,写入相关命令,以便调试。
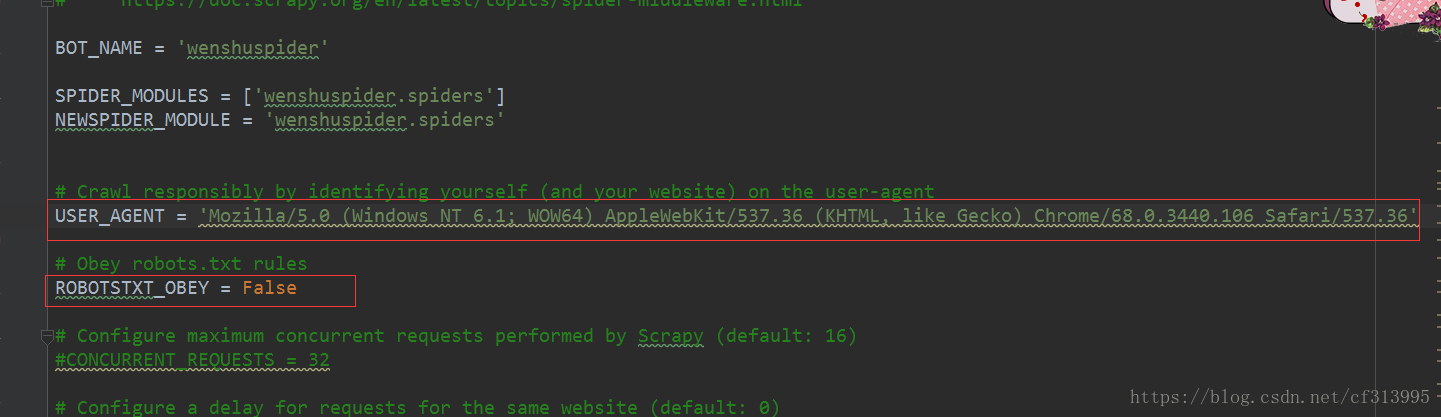
(2)、配置settings.py文件,设置robots协议以及浏览器标识等。
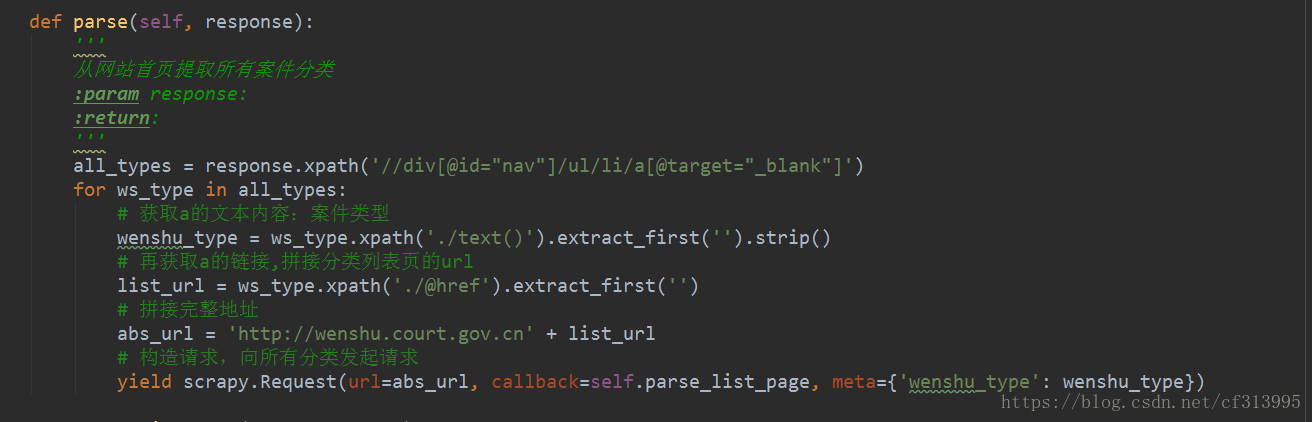
(3)、万事具备,只欠东风。开始编写spider下的爬虫文件内容。打断点使用debug进行调试,看能否成功输出vlx5。
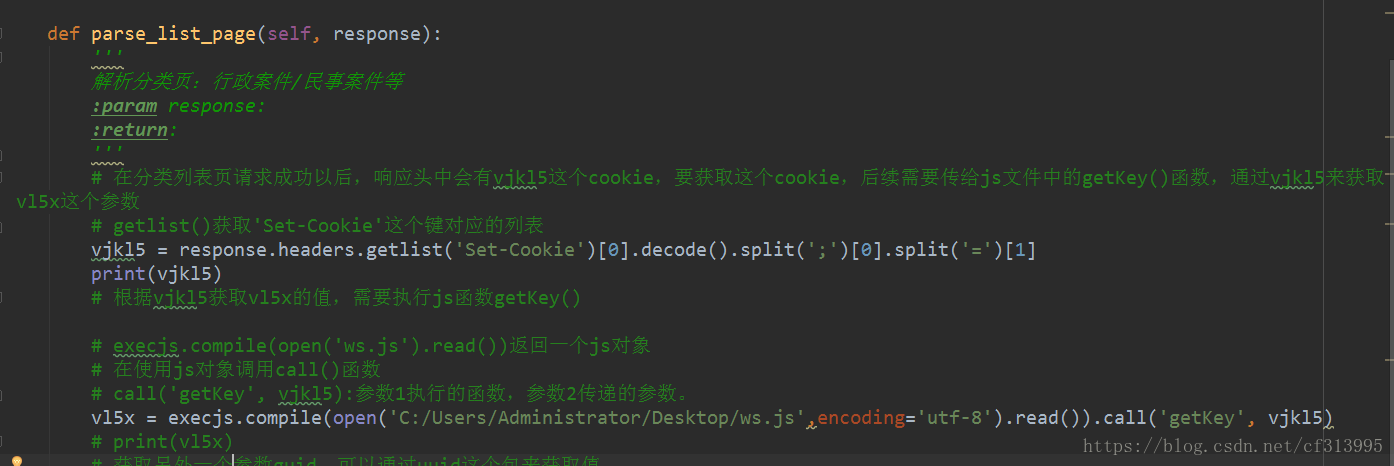
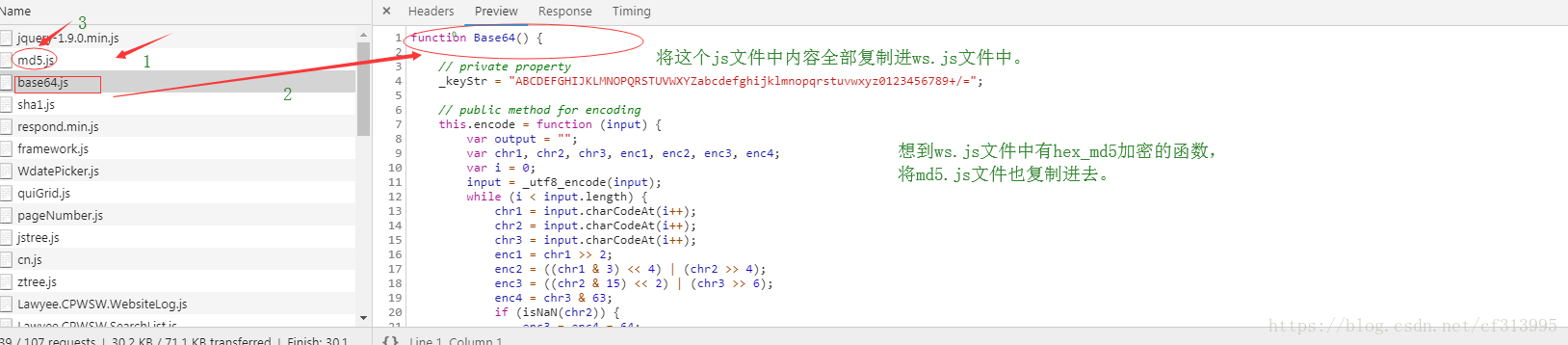
(4)此时debug调试运行,发现报了一个错误。Base64未定义。那就是说我们的ws.js文件中缺少这个函数。寻找这个js函数,并将其放入我们的ws.js文件中,想到ws.js文件中还有hex_md5加密的函数,将md5.js文件中的内容也复制进去。
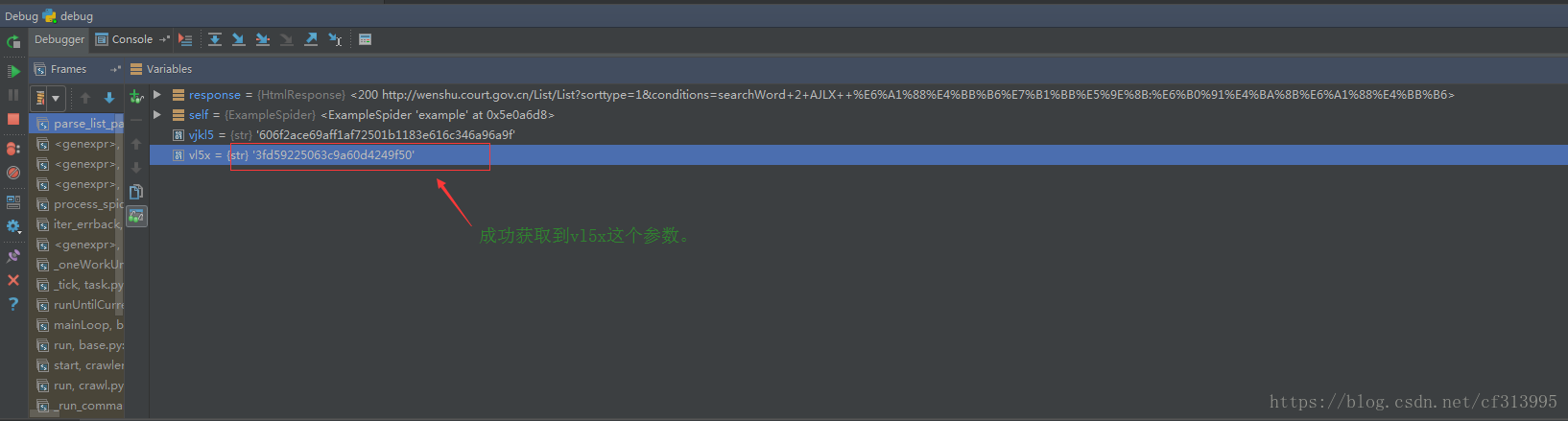
(5)再次调试,发现成功获取到vlx5这个参数。
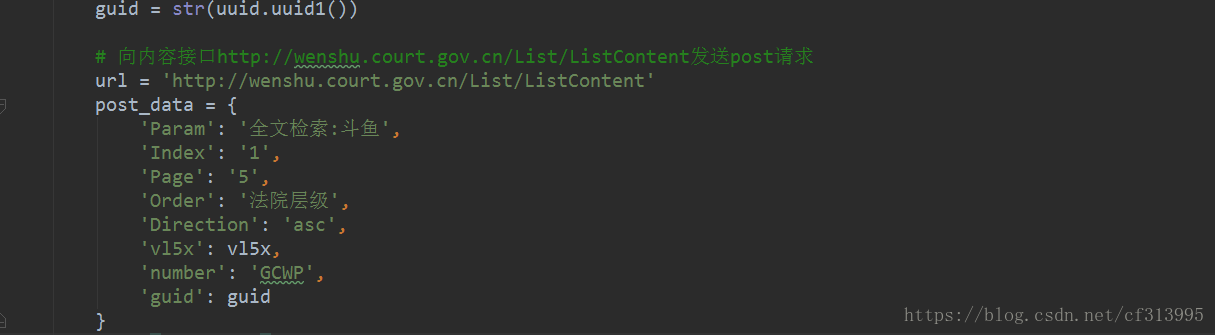
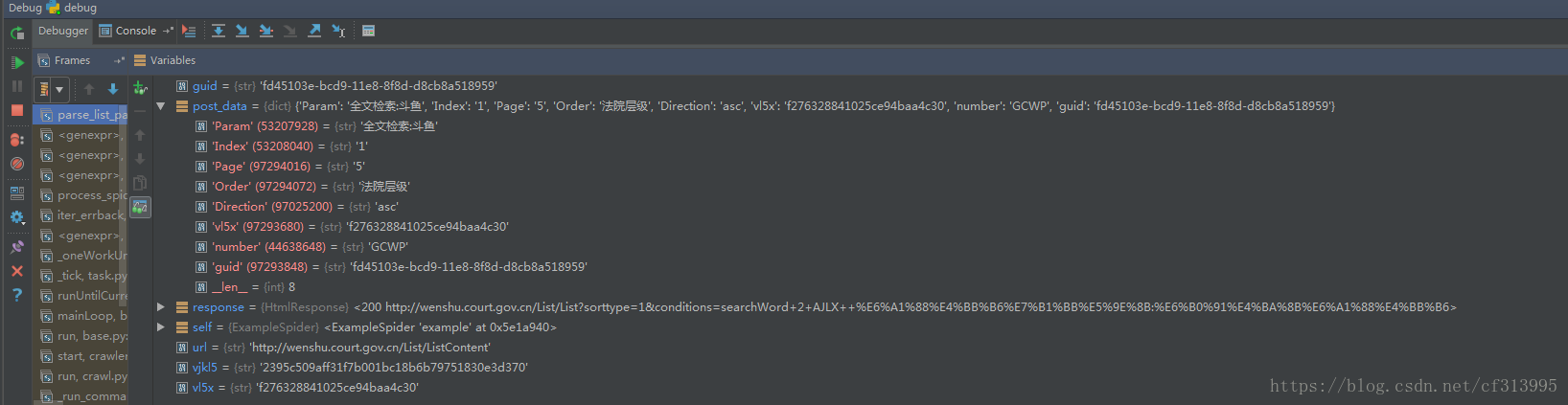
(6)一路向西,继续编写代码。并开始构建post请求的参数。debug调试运行,发现成功构造整个post请求的参数。
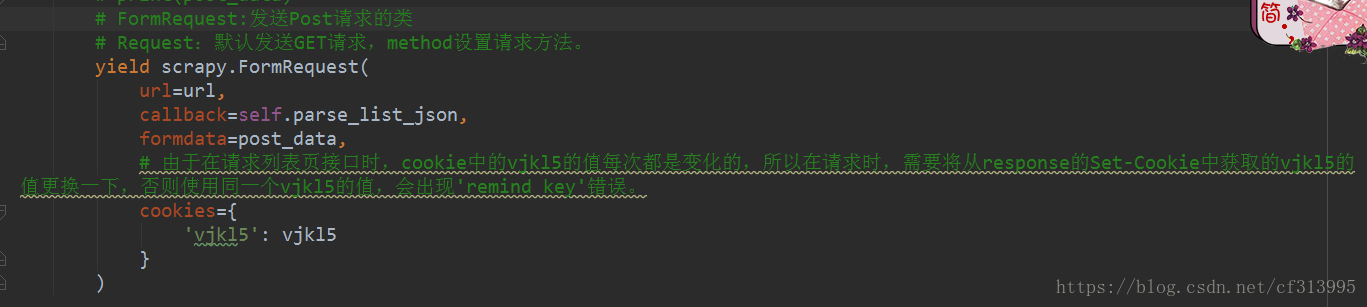
(7)开始发送post请求。值得一提的是,由于在请求列表页接口时,cookie中的vjkl5的值每次都是变化的,所以在请求时,需要将从response的Set-Cookie中获取的vjkl5的值更换一下,否则使用同一个vjkl5的值,会出现’remind key’错误。
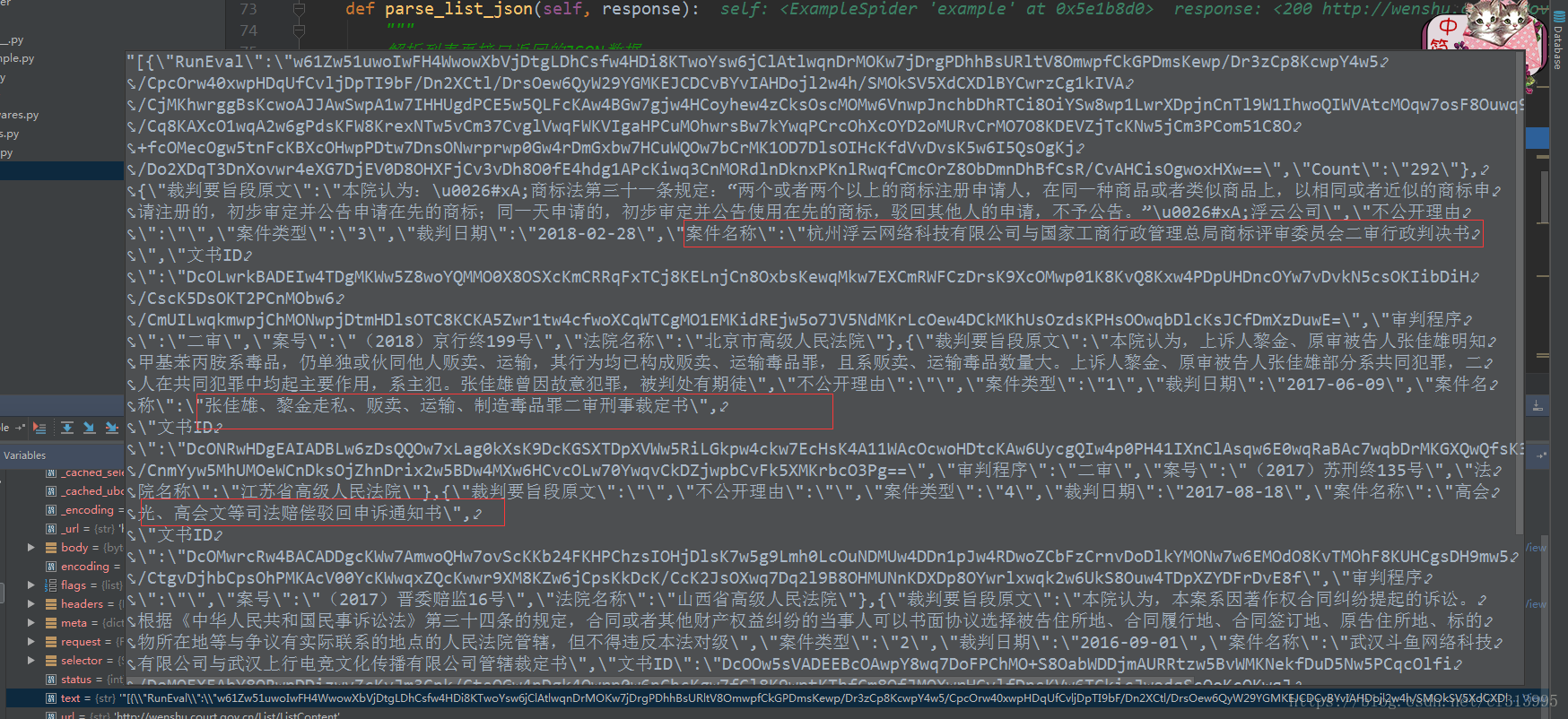
(8)继续编写代码,并调试输出查看。对比查看获取的是我们想要的数据。
(9)那么下一步就是获取每一个标题页的详情信息了。通过抓包发现了请求每一个标题页详情的网址,是个get请求。但同时它携带了一个DocID参数。




















 1988
1988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









