




 本文深入探讨Hadoop核心组件HDFS,涵盖Windows下Hadoop环境配置、Maven依赖导入、API操作,如文件系统访问、文件操作、权限控制、小文件合并,以及HDFS的高可用机制(HA)和联邦机制(Federation)。同时,解析ZooKeeper在Hadoop中的应用,如ResourceManager和NameNode的主备切换。
本文深入探讨Hadoop核心组件HDFS,涵盖Windows下Hadoop环境配置、Maven依赖导入、API操作,如文件系统访问、文件操作、权限控制、小文件合并,以及HDFS的高可用机制(HA)和联邦机制(Federation)。同时,解析ZooKeeper在Hadoop中的应用,如ResourceManager和NameNode的主备切换。
Hadoop 核心-HDFS
1:HDFS 的 API 操作
1.1 配置Windows下Hadoop环境
在windows系统需要配置hadoop运行环境,否则直接运行代码会出现以下问题:
缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
步骤:
第一步:将hadoop2.7.5文件夹拷贝到一个没有中文没有空格的路径下面
第二步:在windows上面配置hadoop的环境变量: HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中
第三步:把hadoop2.7.5文件夹中bin目录下的hadoop.dll文件放到系统盘: C:\Windows\System32 目录
第四步:关闭windows重启
1.2 导入 Maven 依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
1.3 使用url方式访问数据(了解)
@Test
public void demo1()throws Exception{
//第一步:注册hdfs 的url
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//获取文件输入流
InputStream inputStream = new URL("hdfs://node01:8020/a.txt").openStream();
//获取文件输出流
FileOutputStream outputStream = new FileOutputStream(new File("D:\\hello.txt"));
//实现文件的拷贝
IOUtils.copy(inputStream, outputStream);
//关闭流
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
}
1.4 使用文件系统方式访问数据(掌握)
1.4.1 涉及的主要类
在 Java 中操作 HDFS, 主要涉及以下 Class:
-
Configuration- 该类的对象封转了客户端或者服务器的配置
-
FileSystem- 该类的对象是一个文件系统对象, 可以用该对象的一些方法来对文件进行操作, 通过 FileSystem 的静态方法 get 获得该对象
FileSystem fs = FileSystem.get(conf)-
get方法从conf中的一个参数fs.defaultFS的配置值判断具体是什么类型的文件系统 -
如果我们的代码中没有指定
fs.defaultFS, 并且工程 ClassPath 下也没有给定相应的配置,conf中的默认值就来自于 Hadoop 的 Jar 包中的core-default.xml-
hadoop-common.jar包
<property> <name>fs.default.name</name> <value>file:///</value> <description>Deprecated. Use (fs.defaultFS) property instead</description> </property>
-
-
默认值为
file:///, 则获取的不是一个 DistributedFileSystem 的实例, 而是一个本地文件系统的客户端对象
-
- 该类的对象是一个文件系统对象, 可以用该对象的一些方法来对文件进行操作, 通过 FileSystem 的静态方法 get 获得该对象
1.4.2 获取 FileSystem 的几种方式
- 第一种方式
@Test
public void getFileSystem1() throws IOException {
Configuration configuration = new Configuration();
//指定我们使用的文件系统类型:
configuration.set("fs.defaultFS", "hdfs://node01:8020/");
//获取指定的文件系统
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem.toString());
}
- 第二种方式
@Test
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
System.out.println("fileSystem:"+fileSystem);
}
- 第三种方式
@Test
public void getFileSystem3() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
- 第四种方式
//@Test
public void getFileSystem4() throws Exception{
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://node01:8020") ,new Configuration());
System.out.println(fileSystem.toString());
}
1.4.3 遍历 HDFS 中所有文件
- 使用 API 遍历
@Test
public void listMyFiles()throws Exception{
//获取fileSystem类
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
//获取RemoteIterator 得到所有的文件或者文件夹,第一个参数指定遍历的路径,第二个参数表示是否要递归遍历
//只能看到root下的文件,空文件夹不显示
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true);
while (locatedFileStatusRemoteIterator.hasNext()){
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
System.out.println(next.getPath().toString());
}
fileSystem.close();
}
1.4.4 HDFS 上创建文件夹及文件
@Test
public void mkdirs() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test"));
//能遍历创建目录
fileSystem.create(new Path("mydir1/test/a.txt"));
fileSystem.close();
}
1.4.4 下载文件
@Test
public void getFileToLocal()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
FSDataInputStream inputStream = fileSystem.open(new Path("/timer.txt"));
FileOutputStream outputStream = new FileOutputStream(new File("e:\\timer.txt"));
IOUtils.copy(inputStream,outputStream );
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
fileSystem.close();
}
//moveToLocalFile可以使用,但是,会生成一个.filename.crc和一个filename
1.4.5 HDFS 文件上传
@Test
public void putData() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration());
fileSystem.copyFromLocalFile(new Path("file:///c:\\install.log"),new Path("/hello/mydir/test"));
fileSystem.close();
}
1.4.6 hdfs访问权限控制
- 停止hdfs集群,在node01机器上执行以下命令
cd /export/servers/hadoop-2.7.5
sbin/stop-dfs.sh
- 修改node01机器上的hdfs-site.xml当中的配置文件
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
- 修改完成之后配置文件发送到其他机器上面去
scp hdfs-site.xml node02:$PWD
scp hdfs-site.xml node03:$PWD
- 重启hdfs集群
cd /export/servers/hadoop-2.7.5
sbin/start-dfs.sh
- 随意上传一些文件到我们hadoop集群当中准备测试使用
cd /export/servers/hadoop-2.7.5/etc/hadoop
hdfs dfs -mkdir /config
hdfs dfs -put *.xml /config #put时可以用通配符,上传多个文件
hdfs dfs -chmod 600 /config/core-site.xml
- 使用代码准备下载文件
//Permission denied: user=hadoop, access=READ, inode="/config/core-site.xml":root:supergroup:-rw-------
@Test
public void getConfig()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), new Configuration(),"hadoop");
fileSystem.copyToLocalFile(new Path("/config/core-site.xml"),new Path("file:///c:/core-site.xml"));
fileSystem.close();
}
1.4.7 小文件合并
由于 Hadoop 擅长存储大文件,因为大文件的元数据信息比较少,如果 Hadoop 集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理
在我们的 HDFS 的 Shell 命令模式下,可以通过命令行将很多的 hdfs 文件合并成一个大文件下载到本地
cd /export/servers
hdfs dfs -getmerge /config/*.xml ./hello.xml
既然可以在下载的时候将这些小文件合并成一个大文件一起下载,那么肯定就可以在上传的时候将小文件合并到一个大文件里面去
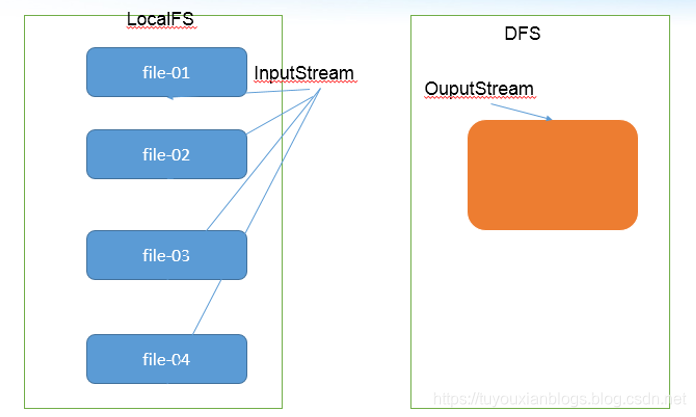
@Test
public void mergeFile() throws Exception{
//获取分布式文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration(),"root");
FSDataOutputStream outputStream = fileSystem.create(new Path("/bigfile.txt"));
//获取本地文件系统
LocalFileSystem local = FileSystem.getLocal(new Configuration());
//通过本地文件系统获取文件列表,为一个集合;该目录下不能有文件夹,否则拒绝访问
FileStatus[] fileStatuses = local.listStatus(new Path("file:///E:\\input"));
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream inputStream = local.open(fileStatus.getPath());
IOUtils.copy(inputStream,outputStream);
IOUtils.closeQuietly(inputStream);
}
IOUtils.closeQuietly(outputStream);
local.close();
fileSystem.close();
}
2:HDFS的高可用机制 (HA)
2.1 HDFS高可用介绍
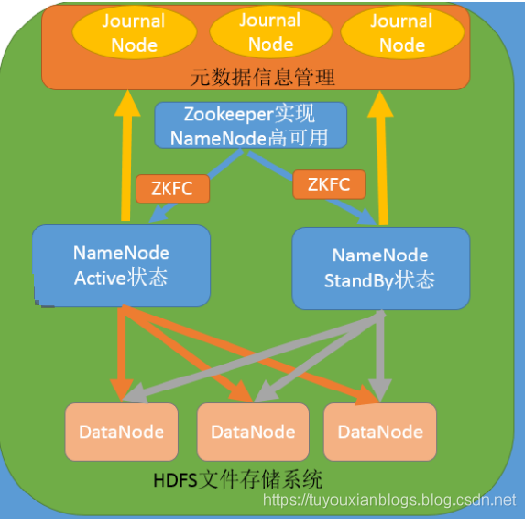
在Hadoop 中,NameNode 所处的位置是非常重要的,整个HDFS文件系统的元数据信息都由NameNode 来管理,NameNode的可用性直接决定了Hadoop 的可用性,一旦NameNode进程不能工作了,就会影响整个集群的正常使用。
在典型的HA集群中,两台独立的机器被配置为NameNode。在工作集群中,NameNode机器中的一个处于Active状态,另一个处于Standby状态。Active NameNode负责群集中的所有客户端操作,而Standby充当从服务器。Standby机器保持足够的状态以提供快速故障切换(如果需要)。
HA补充
在 HDFS 1.x 中只有一个 NameNode 来管理整个集群的元数据信息,一旦 NameNode 挂掉后,整个集群将处于不可用状态,因此为了解决 NameNode 单点故障问题,在 HDFS 2.x 中使用两个 NameNode 来解决,一个 NameNode 是 active 状态,来对外提供服务,另一个 NameNode 是 standby 状态,同步主 NameNode 的元数据信息,这就是 HA (高可用)模型,一旦主 NameNode(active) 挂掉后,备用的 NameNode(standby) 就能立刻切换成主 NameNode,从而继续保证整个集群仍能继续对外提供服务。
但是主 NameNode 挂掉之后,备用的 NameNode 如何能立刻切换成主 NameNode 呢?(要保证和主 NameNode 挂掉之前的状态一样)这就是 HA 要解决的核心问题:如何使两个 NameNode 内存中的元数据信息一致。
在讨论备用 NameNode 如何同步元数据之前,我们先将 NameNode 中管理的元数据信息分成两类,一类是静态的元数据,包括目录树结构、文件大小,文件属主、权限、创建日期等,这些元数据信息是由 Client 和主 NameNode 交互产生的;另一类是动态的元数据,是由 DataNode 通过心跳机制汇报给 NameNode Block 的位置信息,NameNode 本身并不存储 Block 的位置信息(不记录到日志),只是管理。因此,备用的 NameNode 只需同步主 NameNode 的静态元数据信息,而动态的元数据信息由 DataNode 同时向两个 NameNode 通过心跳机制汇报 Block 的位置信息即可。
如何同步主 NameNode 的静态元数据信息呢?
由于主 NameNode 的静态元数据信息是由 Client 和主 NameNode 交互产生的,在 Client 和主 NameNode 发送请求时,主 NameNode 会将这些数据先写到 edits 日志中,然后再返回给 Client 执行结果,因此有以下几种同步数据的方式:
1、使用同步阻塞,主 NameNode 将数据写到 edits 中,然后和备 NameNode 建立 Socket 连接,将数据同步给备用的 NameNode,备 NameNode 执行成功后,再将结果返回给主 NameNode,主 NameNode 再将结果返回给 Client。但是这样做虽然保证了两个 NameNode 的数据一致性,但在同步数据的这段过程中,主 NameNode 一直处于阻塞状态,此时不可对外提供服务,只有等到备 NameNode 将数据同步完成后,将结果返回给 Client 之后,主 NameNode 才可以继续对外提供服务,因此破坏了可用性。
2、使用异步阻塞,主 NameNode 将数据写到 edits 中后,直接将结果返回给 Client,备 NameNode 之后再同步数据并将结果返回给主 NameNode。但是这样会使数据不一致,一旦主 NameNode 挂掉后,数据还没有同步,此时数据将不一致。
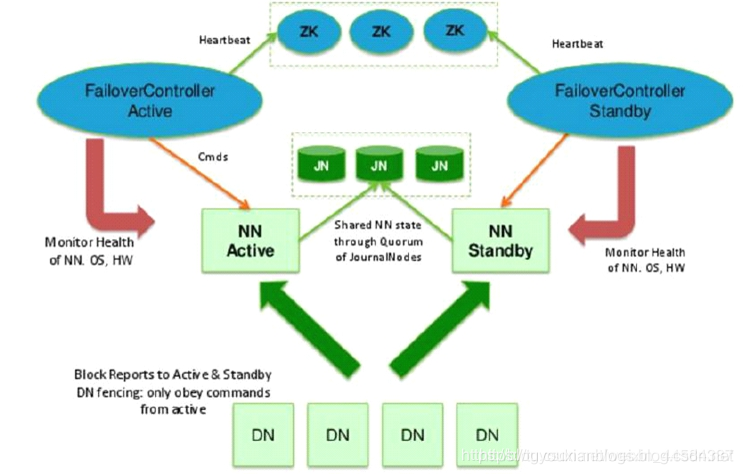
3、准备一个 JournalNode 集群,主 NameNode 将数据直接写到 JN(JournalNode)中,由 JN保存 edits 信息,standby 从 JN 中同步元数据信息。一旦主 NameNode 挂掉,只要最终 standby 从 JN 中同步完所有元数据信息,standby 就可以成为主 NameNode。注意这里 standby 是最终一致性而不是强一致性;JN 还可以用 NFS(Network FileSystem)来代替,只不过要解决 NFS 的单点故障。
active 挂掉后两种切换选择:
1、手动切换:通过命令实现主备之间的切换,可以用 HDFS 升级等场合。
2、自动切换:基于 Zookeeper 实现。
基于 Zookeeper 自动切换方案
ZKFC(ZooKeeper Failover Controller):监控 NameNode 健康状态,并向 Zookeeper 注册 NameNode,NameNode 挂掉后,ZKFC 为 NameNode 竞争锁,获得 ZKFC 锁的 NameNode 变为 active。
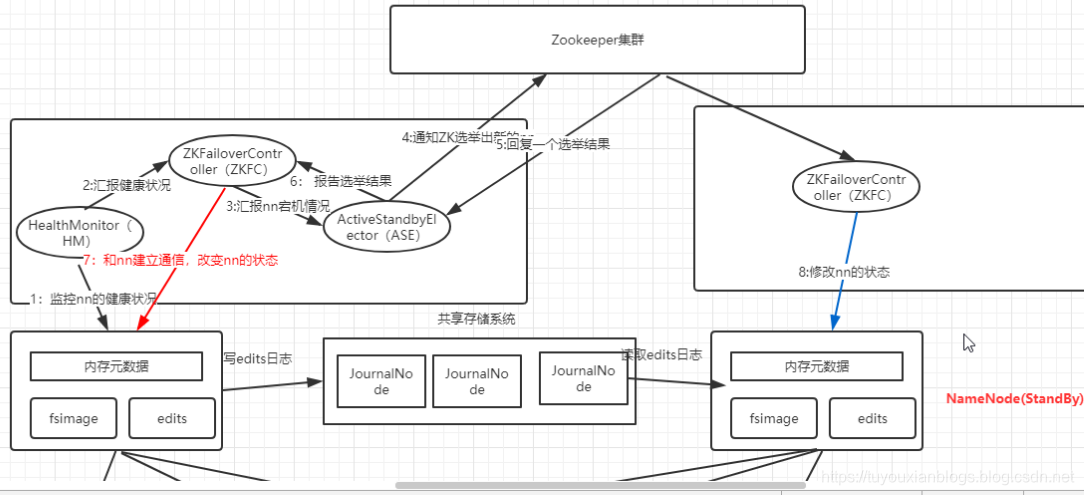
2.2 组件介绍
ZKFailoverController
是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFailoverController会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和Standby状态的切换
HealthMonitor
周期性调用NameNode的HAServiceProtocol RPC接口(monitorHealth 和 getServiceStatus),监控NameNode的健康状态并向ZKFailoverController反馈
ActiveStandbyElector
接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFailoverController的主备切换方法对NameNode进行Active和Standby状态的切换.
DataNode
NameNode包含了HDFS的元数据信息和数据块信息(blockmap),其中数据块信息通过DataNode主动向Active NameNode和Standby NameNode上报
共享存储系统
共享存储系统负责存储HDFS的元数据(EditsLog),Active NameNode(写入)和 Standby NameNode(读取)通过共享存储系统实现元数据同步,在主备切换过程中,新的Active NameNode必须确保元数据同步完成才能对外提供服务
3: Hadoop的联邦机制(Federation)
3.1背景概述
单NameNode的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode成为了性能的瓶颈。因而提出了namenode水平扩展方案-- Federation。
Federation中文意思为联邦,联盟,是NameNode的Federation,也就是会有多个NameNode。多个NameNode的情况意味着有多个namespace(命名空间),区别于HA模式下的多NameNode,它们是拥有着同一个namespace。既然说到了NameNode的命名空间的概念,这里就看一下现有的HDFS数据管理架构,如下图所示:
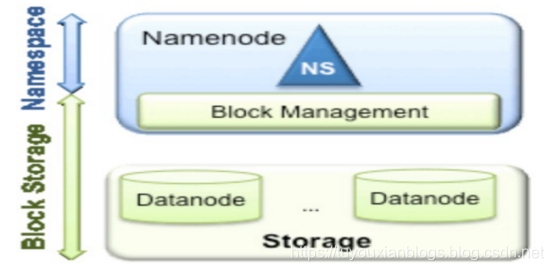
从上图中,我们可以很明显地看出现有的HDFS数据管理,数据存储2层分层的结构.也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下.而这些隶属于同一个NameNode所管理的数据都是在同一个命名空间下的.而一个namespace对应一个block pool。Block Pool是同一个namespace下的block的集合.当然这是我们最常见的单个namespace的情况,也就是一个NameNode管理集群中所有元数据信息的时候.如果我们遇到了之前提到的NameNode内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高NameNode的jvm大小绝对不是一个持久的办法.这时候就诞生了HDFS Federation的机制.
3.2 Federation架构设计
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。
Federation意味着在集群中将会有多个namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
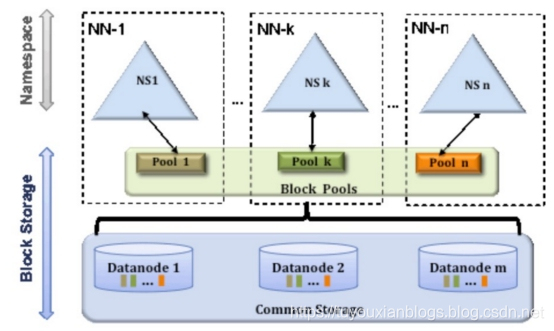
Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的 。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的datadir所在目录里面查看BP-xx.xx.xx.xx打头的目录)。
概括起来:
多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储。
DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况。
HDFS Federation不足
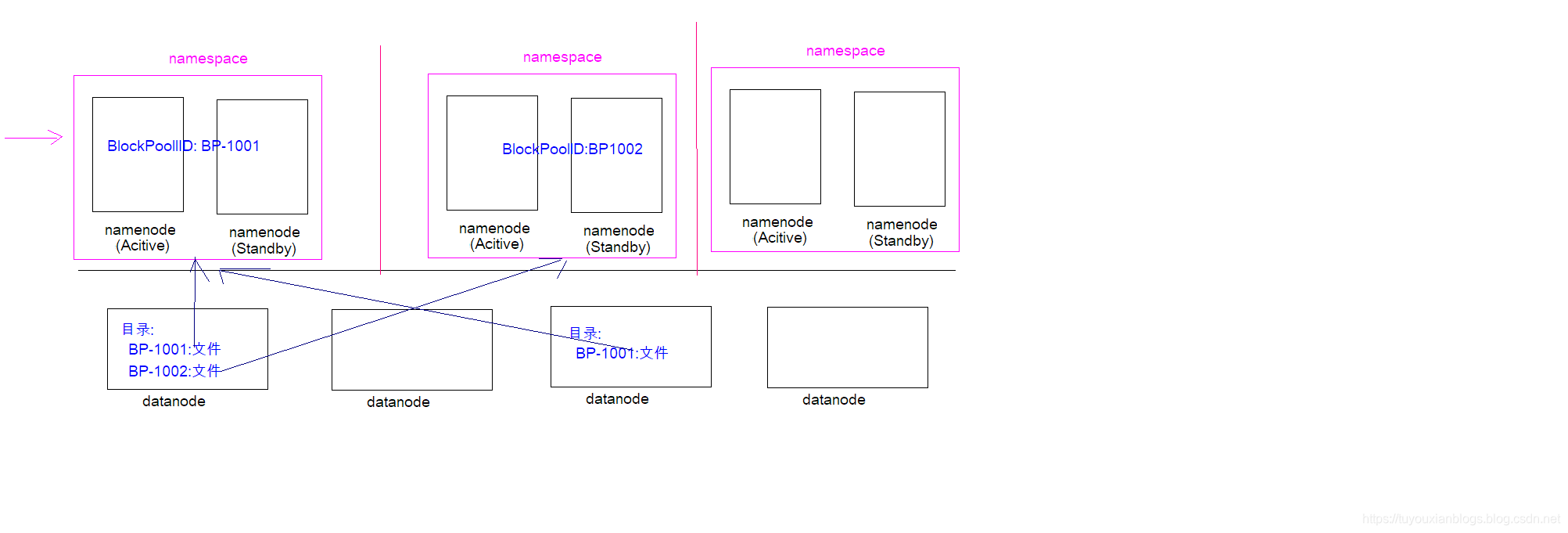
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
所以一般集群规模真的很大的时候,会采用HA+Federation的部署方案。也就是每个联合的namenodes都是ha的。
4.ZooKeeper在Hadoop中的应用
- 参考链接https://cloud.tencent.com/developer/article/1043395
4.1 HA中NodeDate和ResourceManager在Zookeeper的主备切换
- 主备切换
创建锁节点 在ZooKeeper上会有一个/yarn-leader-election/appcluster-yarn的锁节点,所有的ResourceManager在启动的时候,都会去竞争写一个Lock子节点:/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb,该节点是临时节点。ZooKeepr能够为我们保证最终只有一个ResourceManager能够创建成功。创建成功的那个ResourceManager就切换为Active状态,没有成功的那些ResourceManager则切换为Standby状态。
- 注册Watcher监听
所有Standby状态的ResourceManager都会向/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点注册一个节点变更的Watcher监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
- 主备切换
当Active状态的ResourceManager出现诸如宕机或重启的异常情况时,其在ZooKeeper上连接的客户端会话就会失效,因此/yarn-leader-election/appcluster-yarn/ActiveBreadCrumb节点就会被删除。此时其余各个Standby状态的ResourceManager就都会接收到来自ZooKeeper服务端的Watcher事件通知,然后会重复进行步骤1的操作。
以上就是利用ZooKeeper来实现ResourceManager的主备切换的过程,实现了ResourceManager的HA。
HDFS中NameNode的HA的实现原理跟YARN中ResourceManager的HA的实现原理相同。其锁节点为/hadoop-ha/mycluster/ActiveBreadCrumb。

















 6170
6170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









