




 本文深入探讨了Hadoop MapReduce的工作原理,包括MapTask和ReduceTask的执行过程,以及Combiner、Partitioner和InputFormat的概念与区别。详细解释了Shuffle过程,涉及数据分区、排序和归约。此外,还讨论了Hadoop集群中的关键进程,如NameNode、DataNode和ResourceManager的角色。文章最后提到了Hadoop参数调优和MapReduce性能优化的策略,如调整内存大小、使用Combiner和推测执行。
本文深入探讨了Hadoop MapReduce的工作原理,包括MapTask和ReduceTask的执行过程,以及Combiner、Partitioner和InputFormat的概念与区别。详细解释了Shuffle过程,涉及数据分区、排序和归约。此外,还讨论了Hadoop集群中的关键进程,如NameNode、DataNode和ResourceManager的角色。文章最后提到了Hadoop参数调优和MapReduce性能优化的策略,如调整内存大小、使用Combiner和推测执行。
Hadoop篇
- hadoop 篇
- 问题 1 大数据如何存储?举例说明
- 问题 2 说说 mr 执行过程
- 问题 3 mr 环形数组怎么设置? 大能设置多大?
- 问题 4 两个类 TextInputFormatand 和 KeyValueInputFormat 的区别是什么
- 问题 5 在一个运行的 hadoop 任务中,什么是 inputSplit
- 问题 6 什么是 combiner
- 问题 7 hive 和 hbase 和 mysql 的区别、列存储优缺点。
- 问题 8 MapReduce 如何调优
- 问题 9 Hadoop 处理数据时,出现内存溢出的处理方法?
- 问题 10 hdfs 上传文件的流程
- 问题11 YARN的理解.
- 问题 12 fsimage 和 edit 的区别?
- 问题 13 datanode 首次加入 cluster 的时候,如果 log 报告不兼容文件版本,那需要 namenode 执行格式化 操作,这样处理的原因是?
- 问题 14 列出 hadoop 集群中的都分别需要启动哪些进程 它们分别是作用是什么?
- 问题 15 mapreduce 中的 combiner 和 partition 的区别
- 问题16 讲一讲checkpoint
- 问题 17 MapReduce 的 Shuffle 过程
- 问题 18 如果 Reduce 个数和分区数不一致时,会发生什么
- 问题 19 Shuffle 过程中排序用的什么算法
- 问题20、哪个程序通常与 NameNode 在一个节点启动?
- 问题21、你所知道的hadoop调度器,并简要说明其工作方法?
- 问题22、使用的是什么版本的hadoop,了解过CDH或者TDH么
- 问题23、如何监控Hadoop集群,hadoop的管理工具是什么
- 问题24、Mapreduce的工作机制
- 问题25、yarn的基本组成结构和资源分配流程
- 问题26、HDFS的读写流程
- 问题27、Combiner, partition作用,如何设置Compression
- 问题28、Hadoop参数调优,性能优化
- 问题29、hadoop三种原先模式的适用场景
- 问题30、Hadoop中的Sequence File(序列化文件)是什么?
- 问题31、你觉得MR引擎, 在调参方面, 调整哪些参数可以优化
- 问题32、小表关联大表, 大表关联大表, 怎么优化
hadoop 篇
问题 1 大数据如何存储?举例说明
说明 hdfs 的存储机制,不仅限于存储机制、机架感知等,这道面试题的目的不仅仅是想问你存储的机
制,而是想问你在公司是如何进行大数据存储的,这时候你就要从两方面着手回答这个问题:
1、 公司 hdfs 集群的设计方式,采用多少台机器,存储策略是什么样的
2、 存储的手段是采用的 sqoop、canel 还是 flume、logstash
问题 2 说说 mr 执行过程
1. MapTask 工作机制
整个 Map 阶段流程大体如上图所示。简单概述:input File 通过 split 被逻辑切分为多个 split 文件,通过 Record 按行读取内容给 map(用户自己实现的)进行处理,数据被 map 处理结束之后交给 OutputCollector 收集 器,对其结果 key 进行分区(默认使用 hash 分区),然后写入 buffer,每个 map task 都有一个内存缓冲区,存储着 map 的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个 map task 结束后再对磁盘中这个 map task 产生的所有临时文件做合并,生成最终的正式输出文件,然后等待 reduce task 来拉数据。
详细步骤:
-
首先,读取数据组件 InputFormat(默认 TextInputFormat)会通过 getSplits 方法对输入目录中文件 进行逻辑切片规划得到 splits,有多少个 split 就对应启动多少个 MapTask。split 与 block 的对应关系默 认是一对一。
-
将输入文件切分为 splits 之后,由 RecordReader 对象(默认 LineRecordReader)进行读取,以\n 作 为分隔符,读取一行数据,返回<key,value>。Key 表示每行首字符偏移值,value 表示这一行文本内 容。
-
读取 split 返回<key,value>,进入用户自己继承的 Mapper 类中,执行用户重写的 map 函数。 RecordReader 读取一行这里调用一次。
-
map 逻辑完之后,将 map 的每条结果通过 context.write 进行 collect 数据收集。在 collect 中,会先对其进行分区处理,默认使用 HashPartitioner。MapReduce 提供 Partitioner 接口,它的作用就是根据 key 或 value 及 reduce 的数量来决定当前的这对输 出数据最终应该交由哪个 reduce task 处理。默认对 key hash 后再以 reduce task 数量取模。默认的取模方式只是为了平均 reduce 的处理能力,如果用户自己对 Partitioner 有需求,可以订制并设置到 job 上。
-
接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集 map 结果,减少磁盘 IO 的影响。我们的 key/value 对以及 Partition 的结果都会被写入缓冲区。当然写入之前,key 与 value 值都会被序列化成字节数组。 环形缓冲区其实是一个数组**,数组中存放着 key、value 的序列化数据和 key、value 的元数据信息,包 括 partition、key 的起始位置、value 的起始位置以及 value 的长度。环形结构是一个抽象概念。 缓冲区是有大小限制,默认是 100MB**。当 map task 的输出结果很多时,就可能会撑爆内存,所以需要在 一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过 程被称为 Spill,中文可译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写 map 结果的 线程。溢写线程启动时不应该阻止 map 的结果输出,所以整个缓冲区有个溢写的比例 spill.percent。 这个比例默认是 0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 =* 80MB**),溢写线程启动,锁定这 80MB 的内存,执行溢写过程。Map task 的输出结果还可以往剩下的 20MB 内存中写,互不影响。
-
当溢写线程启动后,需要对这 80MB 空间内的 key 做排序(Sort)。排序是 MapReduce 模型默认的行 为,这里的排序也是对序列化的字节做的排序。 如果 job 设置过 Combiner,那么现在就是使用 Combiner 的时候了。将有相同 key 的 key/value 对的 value 加起 来,减少溢写到磁盘的数据量。Combiner 会优化 MapReduce 的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用 Combiner 呢?从这里分析,Combiner 的输出是 Reducer 的输入,Combiner 绝不能改变最 终的计算结果。Combiner 只应该用于那种 Reduce 的输入 key/value 与输出 key/value 类型完全一致,且 不影响最终结果的场景。比如累加,最大值等。Combiner 的使用一定得慎重,如果用好,它对 job 执行效 率有帮助,反之会影响 reduce 的最终结果。
-
每次溢写会在磁盘上生成一个临时文件(写之前判断是否有 combiner),如果 map 的输出结果真的很 大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行 merge 合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引 文件,以记录每个 reduce 对应数据的偏移量。 至此 map 整个阶段结束。
2.ReduceTask 工作机制
Reduce 大致分为 copy、sort、reduce 三个阶段,重点在前两个阶段。copy 阶段包含一个 eventFetcher 来获取已完成的 map 列表,由 Fetcher 线程去 copy 数据,在此过程中会启动两个 merge 线程,分别为 inMemoryMerger 和 onDiskMerger,分别将内存中的数据 merge 到磁盘和将磁盘中的 数据进行 merge。待数据 copy 完成之后,copy 阶段就完成了,开始进行 sort 阶段,sort 阶段主要是执 行 finalMerge 操作,纯粹的 sort 阶段,完成之后就是 reduce 阶段,调用用户定义的 reduce 函数进行 处理。
详细步骤:
- Copy 阶段,简单地拉取数据。Reduce 进程启动一些数据 copy 线程(Fetcher),通过 HTTP 方式请求 maptask 获取属于自己的文件。
- Merge 阶段。这里的 merge 如 map 端的 merge 动作,只是数组中存放的是不同 map 端 copy 来的 数值。 Copy 过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活。merge 有三种形 式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定 阈值,就启动内存到磁盘的 merge。与 map 端类似,这也是溢写的过程,这个过程中如果你设置有 Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种 merge 方式一直在运行,直到 没有 map 端的数据时才结束,然后启动第三种磁盘到磁盘的 merge 方式生成最终的文件。
- 把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
- 对排序后的键值对调用 reduce 方法,键相等的键值对调用一次 reduce 方法,每次调用会产生零个或者多个键值对, 后把这些输出的键值对写入到 HDFS 文件中。
3. Shuffle 机制
map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中 关键的一个流程,这个流程就叫 shuffle。
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,规约,分组)。
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。一般把从 Map 产生 输出开始到 Reduce 取得数据作为输入之前的过程称作 shuffle。
1).Collect 阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是 key/value, Partition 分区信息等。
2).Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之 前需要对数据进行一次排序的操作,如果配置了 combiner,还会将有相同分区号和 key 的数据进行排序(简单合并)。
3).Merge 阶段:把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask最终只产生一个中间数据 文件。
4).Copy 阶段: ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge 阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的 数据文件进行合并操作。
6).Sort 阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数据进行了局部的 排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。 Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的次数 越少,执行速度就越快缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认 100M
问题 3 mr 环形数组怎么设置? 大能设置多大?
mapreduce.task.io.sort.mb调整环形数组大小
问题 4 两个类 TextInputFormatand 和 KeyValueInputFormat 的区别是什么
TextInputFormatand:每次读取的是一行文本数据,如果文本中存在 kv 类型的数据,也作为一行数
据输入,其中输入的 key 是文本数据的偏移量,value 是数据本身
KeyValueInputFormat:每次将数据用分隔符(需要设置)将数据分割成 kv 的形式输入,key 是用
分隔符分割出来的 key,value 是分隔符分割出来的 value 值。
问题 5 在一个运行的 hadoop 任务中,什么是 inputSplit
-
Block 块是以 block size 进行划分数据。 因此,如果群集中的 block size 为 128 MB,则 数据集的每个块将为 128 MB,除非 后一个块小于 block size(文件大小不能被 block size 完全整 除)。例如下图中文件大小为 513MB,513%128=1, 后一个块(e)小于 block size,大小为 1MB。 因此,块是以 block size 的硬切割,并且块甚至可以在逻辑记录结束之前结束(blocks can end even before a logical record ends)。 假设我们的集群中 block size 是 128 MB,每个逻辑记录大约 100 MB(假设为巨大的记录)。所以 第一个记录将完全在一个块中,因为记录大小为 100 MB 小于块大小 128 MB。但是,第二个记录不 能完全在一个块中,因此第二条记录将出现在两个块中,从块 1 开始,在块 2 中结束。
-
InputSplit 如果分配一个 Mapper 给块 1,在这种情况下,Mapper 不能处理第二条记 录,因为块 1 中没有完整第二条记录。因为 HDFS 不知道文件块中的内容,它不知道记录会什么时候 可能溢出到另一个块(because HDFS has no conception of what’s inside the file blocks, it can’t gauge when a record mightspill over into another block)。InputSplit 这是解决这种跨越块边界的那些记录问题,Hadoop 使 用逻辑表示存储在文件块中的数据,称为输入拆分(InputSplit)。当 MapReduce 作业客户端计算 InputSplit 时,它会计算出块中第一个完整记录的开始位置和结束位置。在 后一个记录不完整的情况下,InputSplit 包括下一个块的位置信息和完成该记录 所需的数据的字节偏移量(In cases where the last record in a block is incomplete, the input split includes location information for the next block and the byte offset of the data needed tocomplete the record)。下图显示了数据块和 InputSplit 之间的关系
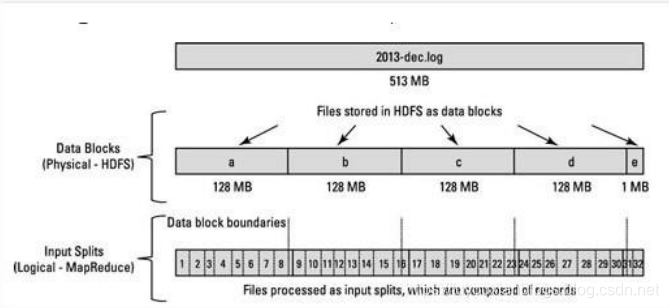
-
块是磁盘中的数据存储的物理块,其中 InputSplit 不是物理数据块。 它是一个 Java 类,指向块中的 开始和结束位置。 因此,当 Mapper 尝试读取数据时,它清楚地知道从何处开始读取以及在哪里停 止读取。 InputSplit 的开始位置可以在块中开始,在另一个块中结束。InputSplit 代表了逻辑记录边界,在 MapReduce 执行期间,Hadoop 扫描块并创建 InputSplits,并且每个 InputSplit 将被分配给一个 Mapper 进行处理。
问题 6 什么是 combiner
在 Hadoop 中,有一种处理过程叫 Combiner,与 Mapper 和 Reducer 在处于同等地位,但其执行 的时间介于 Mapper 和 Reducer 之间,其实就是 Mapper 和 Reducer 的中间处理过程,Mapper 的输出是 Combiner 的输入,Combiner 的输出是 Reducer 的输入。
例如获取历年的 高温度例子,以书中所说的 1950 年为例,在两个不同分区上的 Mapper 计算获得 的结果分别如下:
第一个 Mapper 结果:(1950, [0, 10, 20]) 第二个 Mapper 结果: (1950, [25, 15])
如果不考虑 Combiner,按照正常思路,这两个 Mapper 的结果将直接输入到 Reducer 中处理,如 下所示:
MaxTemperature:(1950, [0, 10, 20, 25, 15]) 终获取的结果是 25。
如果考虑 Combiner,按照正常思路,这两个 Mapper 的结果将分别输入到两个不同的 Combiner 中处理,获得的结果分别如下所示:
第一个 Combiner 结果:(1950, [20]) 第二个 Combiner 结果: (1950, [25])
然后这两个 Combiner 的结果会输出到 Reducer 中处理,如下所示
MaxTemperature:(1950, [20, 25]) 终获取的结果是 25。
由上可知:这两种方法的结果是一致的,使用 Combiner 大的好处是节省网络传输的数据,这对于提
高整体的效率是非常有帮助的。
但是,并非任何时候都可以使用 Combiner 处理机制,例如不是求历年的 高温度,而是求平均温
度,则会有另一种结果。同样,过程如下,
如果不考虑 Combiner,按照正常思路,这两个 Mapper 的结果将直接输入到 Reducer 中处理,如
下所示:
AvgTemperature:(1950, [0, 10, 20, 25, 15]) 终获取的结果是
14。
如果考虑 Combiner,按照正常思路,这两个 Mapper 的结果将分别输入到两个不同的 Combiner
中处理,获得的结果分别如下所示:
第一个 Combiner 结果:(1950, [10]) 第二个 Combiner 结果:
(1950, [20])
然后这两个 Combiner 的结果会输出到 Reducer 中处理,如下所示
AvgTemperature:(1950, [10, 20]) 终获取的结果是
15。
由上可知:这两种方法的结果是不一致的,所以在使用 Combiner 时,一定三思而后行,仔细思量其
是否适合,否则可能造成不必要的麻烦。
问题 7 hive 和 hbase 和 mysql 的区别、列存储优缺点。
mysql:是常用的数据库,采用行存储模式,底层是 binlog,用来存储业务数据,数据量存储较小
hbase:列式数据库,底层是 hdfs,可以存储海量的数据,主要用来存储海量的业务数据和日志数据
hive:数据仓库,用来做数据分析和数据建模使用,数据批量导入。
问题 8 MapReduce 如何调优
mr 调优主要分为 3 步骤:
1、 在代码书写时优化,如尽量避免在 map 端创建变量等,因为 map 端是循环调用的,创建变量会增加内存的消耗,尽量将创建变量放到 setup 方法中
2、 配置调优,可以在集群配置和任务运行时进行调优,如:
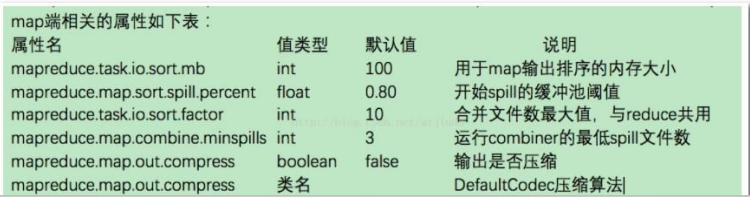
调优总的原则给 shuffle 过程尽量多提供内存空间,在 map 端,可以通过避免多次溢出写磁盘来获得佳性能(相关配置 io.sort.*,io.sort.mb),在 reduce 端,中间数据全部驻留在内存时,就能获得最佳性 能,但是默认情况下,这是不可能发生的,因为一般情况所有内存都预留给 reduce 函数(如需修改 需要配置mapred.inmem.merge.threshold,mapred.job.reduce.input.buffer.percent) 如果能够根据情况对 shuffle 过程进行调优,对于提供 MapReduce 性能很有帮助。 一个通用的原则 是给 shuffle 过程分配尽可能大的内存,当然你需要确保 map 和 reduce 有足够的内存来运行业务逻辑。因此在实现 Mapper 和 Reducer 时,应该尽量减少内存的使用,例如避免在 Map 中不断地叠加。 运行 map 和 reduce 任务的 JVM,内存通过 mapred.child.java.opts 属性来设置,尽可能设大内存。容器的内存大小通过 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb 来设置,默认都是 1024M。
可以通过以下方法提高排序和缓存写入磁盘的效率:
1、调整 mapreduce.task.io.sort.mb 大小,从而避免或减少缓存溢出的数量。当调整这个参数时, 最好同时检测 Map 任务的 JVM 的堆大小,并必要的时候增加堆空间。
2、 mapreduce.task.io.sort.factor 属性的值提高 100 倍左右,这可以使合并处理更快,并减少磁盘的访问。
3、为 K-V 提供一个更高效的自定义序列化工具,序列化后的数据占用空间越少, 缓存使用率就越高。
4、提供更高效的 Combiner(合并器),使 Map 任务的输出结果聚合效 率更高。
5、提供更高效的键比较器和值的分组比较器。
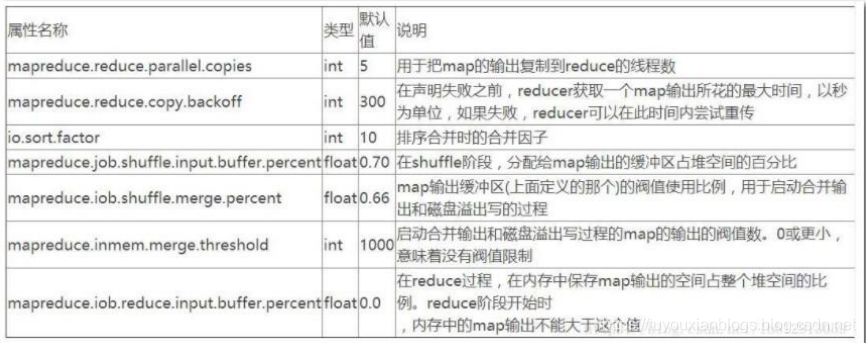
输出依赖于作业中 Reduce 任务的数量,下面是一些优化建议:
1、压缩输出,以节省存储空间,同时也提升 HDFS 写入吞吐量
2、避免写入带外端文件(outofband side file)作为 Reduce 任务的输出
3、根据作业输出文件的消费者的需求,可以分割的压缩技术或许适合
4、以较大块容量设置,写入较大的 HDFS 文件,有助于减少 Map 任务数
Map/Reduce 端调优
通用优化 Hadoop 默认使用 4KB 作为缓冲,这个算是很小的,可以通过 io.file.buffer.size 来调高缓冲池大小。
map 端优化
避免写入多个 spill 文件可能达到 好的性能,一个 spill 文件是最好的。通过估计 map 的输出大小,设置合理的 mapreduce.task.io.sort.*属性,使得 spill 文件数量 小。例如尽可能调大 mapreduce.task.io.sort.mb。
reduce 端优化
如果能够让所有数据都保存在内存中,可以达到 佳的性能。通常情况下,内存都保留给 reduce 函数,但是如果 reduce 函数对内存需求不是很高,将 mapreduce.reduce.merge.inmem.threshold(触发合并的 map 输出文件数)设为 0, mapreduce.reduce.input.buffer.percent(用于保存 map 输出文件的堆内存比例)设为 1.0, 可以达到很好的性能提升。在 TB 级别数据排序性能测试中,Hadoop 就是通过将 reduce 的中间数据都保存在内存中胜利的。
3、修改源代码如果上述两种调优已经无法满足整个集群的要求,那么就需要修改框架的源代码,重新编译,已达到特定的优化需求
问题 9 Hadoop 处理数据时,出现内存溢出的处理方法?
1、Mapper/Reducer 阶段 JVM 内存溢出(一般都是堆)
1)JVM 堆(Heap)内存溢出:堆内存不足时,一般会抛出如下异常:
第一种:“java.lang.OutOfMemoryError:” GC overhead limit exceeded;
第二种:“Error: Java heapspace”异常信息;
第三种:“running beyondphysical memory limits.Current usage: 4.3 GB of 4.3 GBphysical
memory used; 7.4 GB of 13.2 GB virtual memory used. Killing container”。
- 栈内存溢出:抛出异常为:java.lang.StackOverflowError
常会出现在 SQL 中(SQL 语句中条件组合太多,被解析成为不断的递归调用),或 MR 代码中有递归
调用。这种深度的递归调用在栈中方法调用链条太长导致的。出现这种错误一般说明程序写的有问题。
2、 MRAppMaster 内存不足
如果作业的输入的数据很大,导致产生了大量的 Mapper 和 Reducer 数量,致使 MRAppMaster
(当前作业的管理者)的压力很大, 终导致 MRAppMaster 内存不足,作业跑了一般出现了 OOM
信息异常信息为:
Exception: java.lang.OutOfMemoryError thrown from theUncaughtExceptionHandler in
thread "Socket Reader #1 for port 30703
Halting due to Out Of Memory Error…
Halting due to Out Of Memory Error…
Halting due to Out Of Memory Error…
3、 非 JVM 内存溢出
异常信息一般为:java.lang.OutOfMemoryError:Direct buffer memory 自己申请使用操作系统的
内存,没有控制好,出现了内存泄露,导致的内存溢出。
错误解决参数调优
1、Mapper/Reducer 阶段 JVM 堆内存溢出参数调优目前 MapReduce 主要通过两个组参数去控制
内存:(将如下参数调大)
Maper:
mapreduce.map.java.opts=-Xmx2048m(默认参数,表示 jvm 堆内存,注意是 mapreduce 不是
mapred) mapreduce.map.memory.mb=2304(container 的内存) Reducer:
mapreduce.reduce.java.opts=-=-Xmx2048m(默认参数,表示 jvm 堆内存)
mapreduce.reduce.memory.mb=2304(container 的内存)
注意:因为在 yarn container 这种模式下,map/reduce task 是运行在 Container 之中的,所以上
面提到的 mapreduce.map(reduce).memory.mb 大小都大于 mapreduce.map(reduce).java.opts
值的大小。 mapreduce.{map|reduce}.java.opts 能够通过 Xmx 设置 JVM 大的 heap 的使用,一般
设置为 0.75 倍的 memory.mb,因为需要为 java code 等预留些空间 2、MRAppMaster:
yarn.app.mapreduce.am.command-opts=-Xmx1024m(默认参数,表示 jvm 堆内存)
yarn.app.mapreduce.am.resource.mb=1536(container 的内存)
注意在 Hive ETL 里面,按照如下方式设置:
set mapreduce.map.child.java.opts="-Xmx3072m"(注:-Xmx 设置时一定要用引号,不加引号各种
错误)
set mapreduce.map.memory.mb=3288
或
set mapreduce.reduce.child.java.opts=“xxx”
set mapreduce.reduce.memory.mb=xxx
涉及 YARN 参数:
•yarn.scheduler.minimum-allocation-mb (小分配单位 1024M)
•yarn.scheduler.maximum-allocation-mb (8192M)
•yarn.nodemanager.vmem-pmem-ratio (虚拟内存和物理内存之间的比率默认 2.1)
•yarn.nodemanager.resource.memory.mb
Yarn 的 ResourceManger(简称 RM)通过逻辑上的队列分配内存,CPU 等资源给 application,
默认情况下 RM 允许 大 AM 申请 Container 资源为 8192MB(“yarn.scheduler.maximum
allocation-mb“),默
认情况下的 小分配资源为 1024M(“yarn.scheduler.minimum-allocation-mb“),AM 只能以增量
(”yarn.scheduler.minimum-allocation-mb“)和不会超过(“yarn.scheduler.maximum
allocationmb“)的值去向 RM 申请资源,AM 负责将(“mapreduce.map.memory.mb“)和
(“mapreduce.reduce.memory.mb“)的值规整到能被(“yarn.scheduler.minimum-allocation
mb“)整除,RM 会拒绝申请内存超过 8192MB 和不能被 1024MB 整除的资源请求。(不同配置会有
不同)
问题 10 hdfs 上传文件的流程
详细步骤解析:
1、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode 检查目标文件是否
已存在,父目录是否存在,返回是否可以上传;
2、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3、 NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的
DataNode 的地址如:A,B,C;
注:Hadoop 在设计时考虑到数据的安全与高效,数据文件默认在 HDFS 上存放三份,存储策略为本
地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。
4、 client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline),A
收到请求会继续调用 B,然后 B 调用 C,将整个 pipeline 建立完成,后逐级返回 client;
5、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单
位 (默认 64K),A 收到一个 packet 就会传给 B,B 传给 C;A 每传一个 packet 会放入一个应答队列
等待应答。
6、 数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在 pipeline 反方向上,逐个发送
ack(命令正确应答), 终由 pipeline 中第一个 DataNode 节点 A 将 pipeline ack 发送给client;
7、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个 block 到服务器。
问题11 YARN的理解.
- YARN通俗介绍
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的
Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和
调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
可以把 yarn 理解为相当于一个分布式的操作系统平台,而 mapreduce 等运算程序则相当于运行于
操作系统之上的应用程序,Yarn 为这些程序提供运算所需的资源(内存、cpu)。
-
yarn 并不清楚用户提交的程序的运行机制
-
yarn 只提供运算资源的调度(用户程序向 yarn 申请资源,yarn 就负责分配资
源) -
yarn 中的主管角色叫 ResourceManager
-
yarn 中具体提供运算资源的角色叫 NodeManager
-
yarn 与运行的用户程序完全解耦,意味着 yarn 上可以运行各种类型的分布式运算程序,比如
mapreduce、storm,spark,tez …… -
spark、storm 等运算框架都可以整合在 yarn 上运行,只要他们各自的框架中有符合 yarn 规范的资
源请求机制即可 -
yarn 成为一个通用的资源调度平台.企业中以前存在的各种运算集群都可以整合在一个物理集群上,
提高资源利用率,方便数据共享
- Yarn基本架构
- YARN是一个资源管理、任务调度的框架,主要包含三大模块:ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)。RM负责所有资源的监控、分配和管理;AM复杂每一个具体应用程序的调度和协调;NM负责每一个节点的维护。对于所有的application,RM拥有绝对的控制权和对资源的分配权。而每个AM则会和RM协商资源,同时和NodeManage通信来执行和监控task。
- Yarn三大组件介绍
-
ResuouceManager
- RM负责整个集群的资源管理和分配,是一个全局的资源管理系统。
- NM以心跳的方式向RM汇报资源使用情况(目前主要是CPU和内存的使用情况)。RM只接受NM的资源回报信息,对于具体的资源处理则交给NM自己处理
- YARN Schedule根据application的请求为其分配资源,不负责application job的监控、追踪、运行状态反馈、启动等工作。
-
NodeManger
-
NM是每一个节点上的资源和任务管理器,它是管理这台机器的代理,负责该节点程序的运行,以及该节点资源的管理和监控。YARN集群每个节点都运行一个NodeManager。
-
NodeManager 定时向 ResourceManager 汇报本节点资源(CPU、内存)的使用情况和Container 的运行状态。当 ResourceManager 宕机时 NodeManager 自动连接 RM 备用节点。
-
NodeManager 接收并处理来自 ApplicationMaster 的 Container 启动、停止等各种请求。
-
-
ApplicationMasterl 用户提交的每个应用程序均包含一个 ApplicationMaster,它可以运行在 ResourceManager 以外的机器上。
- 负责与 RM 调度器协商以获取资源(用 Container 表示)。 l 将得到的任务进一步分配给内部的任务(资源的二次分配)。
- 与 NM 通信以启动/停止任务。
- 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
- 当前 YARN 自带了两个 ApplicationMaster 实现,一个是用于演示 AM 编写方法的实例程序DistributedShell,它可以申请一定数目的 Container 以并行运行一个 Shell 命令或者 Shell 脚本;另一个是运行 MapReduce 应用程序的 AM—MRAppMaster。注:RM 只负责监控 AM,并在 AM 运行失败时候启动它。RM 不负责 AM 内部任务的容错,任务的容错由 AM 完成。
4. Yarn 运行流程
-
client 向 RM 提交应用程序,其中包括启动该应用的 ApplicationMaster 的必须信息,
例如 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。 -
ResourceManager 启动一个 container 用于运行 ApplicationMaster。
-
启动中的 ApplicationMaster 向 ResourceManager 注册自己,启动成功后与 RM 保持心跳。
-
ApplicationMaster 向 ResourceManager 发送请求,申请相应数目的 container。
-
ResourceManager 返回 ApplicationMaster 的申请的 containers 信息。申请成功的 container,
由 ApplicationMaster 进行初始化。container 的启动信息初始化后,AM 与对应的 NodeManager
通信,要求 NM 启动 container。AM 与 NM 保持心跳,从而对 NM 上运行的任务进行监控和管
理。 -
container 运行期间,ApplicationMaster 对 container 进行监控。container 通过 RPC 协议向对
应的 AM 汇报自己的进度和状态等信息。 l 应用运行期间,client 直接与 AM 通信获取应用的状
态、进度更新等信息。 -
应用运行结束后,ApplicationMaster 向 ResourceManager 注销自己,并允许属于它的
container 被收回。
5. Yarn 调度器 Scheduler
理想情况下,我们应用对 Yarn 资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别
是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在 Yarn
中,负责给应用分配资源的就是 Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略
可以解决所有的应用场景。为此,Yarn 提供了多种调度器和可配置的策略供我们选择。在 Yarn 中有
三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,Fair Scheduler。
5.1. FIFO Scheduler
FIFO Scheduler 把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时
候,先给队列中 头上的应用进行分配资源,待 头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler 是 简单也是 容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大
的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用 Capacity
Scheduler 或 Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资
源。
5.2. Capacity Scheduler
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每
个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个
队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个
成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>mapreduce,spark</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property><name>yarn.scheduler.capacity.root.dev.mapreduce.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.spark.capacity</name>
<value>50</value>
</property>
</configuration>
我们可以看到,dev 队列又被分成了 mapreduce 和 spark 两个相同容量的子队列。dev 的
maximumcapacity 属性被设置成了 75%,所以即使 prod 队列完全空闲 dev 也不会占用全部集群资
源,也就是说, prod 队列仍有 25%的可用资源用来应急。我们注意到,mapreduce 和 spark 两个
队列没有设置 maximum-capacity 属性,也就是说 mapreduce 或 spark 队列中的 job 可能会用到
整个 dev 队列的所有资源( 多为集群的 75%)。而类似的,prod 由于没有设置 maximum-capacity
属性,它有可能会占用集群全部资源。
关于队列的设置,这取决于我们具体的应用。比如,在 MapReduce 中,我们可以通过
mapreduce.job.queuename 属性指定要用的队列。如果队列不存在,我们在提交任务时就会收到
错误。如果我们没有定义任何队列,所有的应用将会放在一个 default 队列中。
注意:对于 Capacity 调度器,我们的队列名必须是队列树中的 后一部分,如果我们使用队列树则不
会被识别。比如,在上面配置中,我们使用 prod 和 mapreduce 作为队列名是可以的,但是如果我
们用 root.dev.mapreduce 或者 dev. mapreduce 是无效的
问题 12 fsimage 和 edit 的区别?
HDFS 磁盘上元数据文件分为两类,用于持久化存储:
fsimage 镜像文件:是元数据的一个持久化的检查点,包含 Hadoop 文件系统中的所有目录和文件
元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode 加入集
群的时候,namenode 询问 datanode 得到的,并且间断的更新。
Edits 编辑日志:存放的是 Hadoop 文件系统的所有更改操作(文件创建,删除或修改)的日志,文
件系统客户端执行的更改操作首先会被记录到 edits 文件中。
fsimage 和 edits 文件都是经过序列化的,在 NameNode 启动的时候,它会将 fsimage 文件中的内
容加载到内存中,之后再执行 edits 文件中的各项操作,使得内存中的元数据和实际的同步,存在内
存中的元数据支持客户端的读操作,也是 完整的元数据。
当客户端对 HDFS 中的文件进行新增或者修改操作,操作记录首先被记入 edits 日志文件中,当客户
端操作成功后,相应的元数据会更新到内存元数据中。因为 fsimage 文件一般都很大(GB 级别的很
常见),如果所有的更新操作都往 fsimage 文件中添加,这样会导致系统运行的十分缓慢。
HDFS 这种设计实现着手于:一是内存中数据更新、查询快,极大缩短了操作响应时间;二是内存中
元数据丢失风险颇高(断电等),因此辅佐元数据镜像文件(fsimage)+编辑日志文件(edits)的
备份机制进行确保元数据的安全。
问题 13 datanode 首次加入 cluster 的时候,如果 log 报告不兼容文件版本,那需要 namenode 执行格式化 操作,这样处理的原因是?
这样处理是不合理的,因为那么 namenode 格式化操作,是对文件系统进行格式
化,namenode 格式化时清空 dfs/name 下空两个目录下的所有文件,之后,会在目
录 dfs.name.dir 下创建文件。文本不兼容,有可能 namenode 与 datanode 的 数据里的
namespaceID、clusterID 不一致,找到两个 ID 位置,修改为一样即可解决。
问题 14 列出 hadoop 集群中的都分别需要启动哪些进程 它们分别是作用是什么?
YARN 相关进程:
ResourceManager ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系
统。 NodeManager 以心跳的方式向 ResourceManager 汇报资源使用情况(目前主要是 CPU 和内
存的使用情况)。RM 只接受 NM 的资源回报信息,对于具体的资源处理则交给 NM 自己处理。
YARN Scheduler 根据 application 的请求为其分配资源,不负责 application job 的监控、追踪、运行状
态反 馈、启动等工作。
NodeManager
NodeManager 是每个节点上的资源和任务管理器,它是管理这
台机器的代理,负责该节点程序的运行,以及该节点资源的管理和监控。YARN 集群每个节点都运行
一个 NodeManager。
NodeManager 定时向 ResourceManager 汇报本节点资源(CPU、内存)
的使用情况和 Container 的运行状态。当 ResourceManager 宕机时 NodeManager 自动连接 RM
备用节点。
NodeManager 接收并处理来自 ApplicationMaster 的 Container 启动、停止等各种请求。
HDFS 主要进程
namenode:管理元数据、接收 client 请求、定期接收 datanode 的心 跳
datanode:管理数据块、定期向 namenode 发送心跳
journalnode:hdfs HA 模式下存储元数据
ZKFC:管理 namenode 主从的进程
问题 15 mapreduce 中的 combiner 和 partition 的区别
combiner 其实属于优化方案,由于带宽限制,应该尽量 map 和 reduce 之间的数据传输数量。它在
Map 端把同一个 key 的键值对合并在一起并计算,计算规则与 reduce 一致,所以 combiner 也可
以看作特殊的 Reducer。
partition 的作用就是把这些数据归类。每个 map 任务会针对输出进行分区,及对每一个 reduce 任
务建立一个分区。划分分区由用户定义的 partition 函数控制,默认使用哈希函数来划分分区。
问题16 讲一讲checkpoint
- 非HA的checkpoint过程:
secondary namenode请求主Namenode停止使用edits文件,暂时将新的写操作记录到一个新文件中,如edits.new。
secondary namenode节点从主Namenode节点获取fsimage和edits文件(采用HTTP GET)
secondary namenode将fsimage文件载入到内存,逐一执行edits文件中的操作,创建新的fsimage文件
secondary namenode将新的fsimage文件发送回主Namenode(使用HTTP POST)
主Namenode节点将从secondary namenode节点接收的fsimage文件替换旧的fsimage文件,用步骤1产生的edits.new文件替换旧的edits文件(即改名)。同时更新fstime文件来记录检查点执行的时间
- 配置了HA的HDFS中,有active和standby namenode两个namenode节点。他们的内存中保存了一样的集群元数据信息,这个后续我会详细用一篇文章介绍HA,所以这里就不多说了。因为standby namenode已经将集群状态存储在内存中了,所以创建检查点checkpoint的过程只需要从内存中生成新的fsimage。
详细过程如下: (standby namenode=SbNN, activenamenode=ANN)
- SBNN查看是否满足创建检查点的条件:
(1) 距离上次checkpoint的时间间隔 >=
d
f
s
.
n
a
m
e
n
o
d
e
.
c
h
e
c
k
p
o
i
n
t
.
p
e
r
i
o
d
(
2
)
E
d
i
t
s
中
的
事
务
条
数
达
到
{dfs.namenode.checkpoint.period} (2) Edits中的事务条数达到
dfs.namenode.checkpoint.period(2)Edits中的事务条数达到{dfs.namenode.checkpoint.txns}限制
这两个条件任何一个被满足了,就触发一次检查点创建。
-
SbNN将内存中当前的状态保存成一个新的文件,命名为fsimage.ckpt_txid。其中txid是最后一个edit中的最后一条事务的ID(transaction ID)。然后为该fsimage文件创建一个MD5文件,并将fsimage文件重命名为fsimage_txid。
-
SbNN向active namenode发送一条HTTP GET请求。请求中包含了SbNN的域名,端口以及新fsimage的txid。
-
ANN收到请求后,用获取到的信息反过来向SbNN再发送一条HTTP GET请求,获取新的fsimage文件。这个新的fsimage文件传输到ANN上后,也是先命名为fsimage.ckpt_txid,并为它创建一个MD5文件。然后再改名为fsimage_txid。fsimage过程完成。
参考链接:https://blog.youkuaiyun.com/Amber_amber/article/details/47003589
问题 17 MapReduce 的 Shuffle 过程
map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中 关键的一个流程,这个流程
就叫 shuffle。
shuffle: 洗牌、发牌—— (核心机制:数据分区,排序,规约,分组)。
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。一般把从 Map 产生输出
开始到 Reduce 取得数据作为输入之前的过程称作 shuffle。
1).Collect 阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是
key/value, Partition 分区信息等。
2).Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入
磁盘之前需要对数据进行一次排序的操作,如果配置了 combiner,还会将有相同分区号和 key 的数
据进行排序。
3).Merge 阶段:把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask 终只产生一个中间
数据文件。
4).Copy 阶段: ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的
数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据
写到磁盘之上。
5).Merge 阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的数据
文件进行合并操作。
6).Sort 阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数据进行了局
部的排序,ReduceTask 只需保证 Copy 的数据的 终整体有效性即可。
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的
次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认 100M
问题 18 如果 Reduce 个数和分区数不一致时,会发生什么
1、 首先,由于 partition 中的 partition 数量和 reducer 的数量是一致的,getpartition 函数中的
numpartitions 也是由 job 设定的 reducer 值传入。
2、 如果自定义了 Partitioner,并设置了 setNumReduceTasks,那么就会出现 partition 数量和
reduce 个数不一致的情况
3、 由于数据是根据分区写进 reduce 终端产生结果的,也就是如果 reduce 个数设置为 2,那么假
设 key.hashcode%numReduceTasks=0 数据就会进入 part-r-00000,
key.hashcode%numReduceTasks=1 数据就会进入 part-r-00001,同理类推
4、 如果 partition 分区数>reduce 的个数,那么就会出现返回 2 的情况,可是没有 part-r-00002
这个文件,那么这部分数据就丢失了
5、 如果 partition 分区数<reduce 的个数,那么只会返回 0 或者 1,就会造成数据倾斜,也就是
只有 partr-00000 或者 part-r-00001 中的一个文件中有数据。
总结:不一致,会发生数据丢失或者数据倾斜。
问题 19 Shuffle 过程中排序用的什么算法
排序贯穿于 Map 任务和 Reduce 任务,是 MapReduce 非常重要的一环,排序操作属于
MapReduce 计算框架的默认行为,不管流程是否需要,都会进行排序。
在 MapReduce 计算框架中,主要用到了两种排序方法:快速排序和归并排序
快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据比另外
一部分的所有数据都小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可
以递归进行,以此使整个数据成为有序序列。
归并排序:归并排序在分布式计算里面用的非常多,归并排序本身就是一个采用分治法的典型
应用。归并排序是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为
若干个有序的子序列,再把有序的子序列合并为整体有序序列。
在 map 任务和 reduce 任务的过程中,一共发生 3 次排序操作。
1、 当 map 函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阈值,在刷写磁
盘之前,后台线程会将缓冲区的数据划分成相应的分区。在每个分区中,后台线程按键进行内
排序。
2、 在 Map 任务完成之前,磁盘上存在多个已经分好区,并排好序的、大小和缓冲区一样的
溢写文件,这时溢写文件将被合并成一个已分区且已排序的输出文件。由于溢写文件已经经过
第一次排序,所以合并文件时只需要再做一次排序就可使输出文件整体有序。 3、在 shuffle 阶
段,需要将多个 Map 任务的输出文件合并,由于经过第二次排序,所以合并文件时只需要再做
一次排序就可使输出文件整体有序 。在这 3 次排序中第一次是在内从缓冲区做的排序,使用的算法
务,是 MapReduce 非常重要的一环,排序操作属于
MapReduce 计算框架的默认行为,不管流程是否需要,都会进行排序。
问题20、哪个程序通常与 NameNode 在一个节点启动?
问题21、你所知道的hadoop调度器,并简要说明其工作方法?
问题22、使用的是什么版本的hadoop,了解过CDH或者TDH么
问题23、如何监控Hadoop集群,hadoop的管理工具是什么
问题24、Mapreduce的工作机制
问题25、yarn的基本组成结构和资源分配流程
问题26、HDFS的读写流程
问题27、Combiner, partition作用,如何设置Compression
问题28、Hadoop参数调优,性能优化
问题29、hadoop三种原先模式的适用场景
问题30、Hadoop中的Sequence File(序列化文件)是什么?
问题31、你觉得MR引擎, 在调参方面, 调整哪些参数可以优化
mapreduce.map.memory.mb: 一个MapTask可使用的资源上限,默认为1024
mapreduce.reduce.memory.mb: 一个ReduceTask可使用的资源上限,默认为1024
mapreduce.map.java.opts: Map Task的JVM参数
mapreduce.reduce.java.opts: Reduce Task的JVM参数
mapreduce.map.cpu.vcores: 每个Maptask可使用的最多cpucore数目, 默认值:1
mapreduce.reduce.cpu.vcores: 每个Reducetask可使用的最多cpucore数目, 默认值:1
mapreduce.task.io.sort.mb 100 //shuffle的环形缓冲区大小,默认100m
mapreduce.map.sort.spill.percent 0.8 //环形缓冲区溢出的阈值,默认80%
mapreduce.map.speculative: 是否为MapTask打开推测执行机制,默认为false
mapreduce.reduce.speculative: 是否为ReduceTask打开推测执行机制,默认为false
问题32、小表关联大表, 大表关联大表, 怎么优化
1小表放前,大表放后,这样hive会把前边的表数据放进缓存,再和大表关键,速度会加快。
2在map端join, 避免数据倾斜
3开启中间结果压缩
1将B大表过滤掉不需要的字段,生成一个临时B表, 然后再进行mapjoin
2动态一分为二,即对倾斜的键值和不倾斜的键值分开处理,不倾斜的正常join即可,
倾斜的把他们找出来做mapjoin,最后union all其结果即可。
3把所需要搜索的字段建组合索引

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









