



HADOOP3.0 框架学习笔记Liunx版
大数据学习路线

概念补充
官网入库 = 中文官网入口
HADOOP由java语言开发,因此他的运行需要JDK环境支持。
其内容主要分两部分:数据存储HDFS、数据计算MapReduce
HDFS部分
对于如何提高读取数据的效率,HADOOP有一套解决方案,基本原理就是将一个数据集存储到多个硬盘里,然后并行读取。比如1TB的数据,我们平均100份存储到100个1TB硬盘上,同时读取,那么读取完整个数据集的时间用不上两分钟。至于硬盘剩下的99的容量,可以用来存储其他的数据集,这样就不会产生浪费。解决读取效率问题的同时,我们也解决了大数据的存储问题。
HDFS集群:
1.namenode
HDFS集群汇总的主节点,其他应用或者程序调用HDFS就是通过调用主节点服务来获取数据文件的
2.datanode
存储数据的工作节点,一般HDFS集群中每一个服务器都会被表示为datanode节点,用来存放数据块
3.secondnamenode
类似于备用主节点的作用
HDFS分布式集群环境搭建
下载(Hadoop版本与Jdk版本的对应关系请自行查明):
- Hadoop3.0系列的软件包下载地址:https://dlcdn.apache.org/hadoop/common/,选择合适的版本进行下载,我这里下载的是3.3.5版本 hadoop-3.3.5.tar.gz
tar -zxvf hadoop-3.3.5.tar.gz -C 安装目录 (/usr/local/data/hadoop)
- JDK下载地址:https://www.oracle.com/cn/java/technologies/downloads/#java8 下载linux版安装包
tar -zxvf hadoop-3.3.5.tar.gz -C 安装目录 (/usr/local/data/jdk)
- 基本环境要求:
- 确保防火墙是关闭状态(或者放通集群相互访问的IP地址,我这里直接关闭防火墙)。
查看防火墙状态: systemctl status firewalld
停止防火墙程序(下次重启会再次启动): systemctl stop firewalld
禁止防火墙自动运行:systemctl disable firewalld
防火墙停止前

防火墙停止后

- 确保NAT模式和静态IP的确定(我这里用的VMware虚拟机所以要设置,可以略过)
可以参考此文章:window设置vmware虚拟机固定IP
找到如下图文件(window版本下的虚拟机网卡配置文件名是 ifcfg-ens33) cd /etc/sysconfig/network-scripts
打开此文件:vim /etc/sysconfig/network-scripts/ifcfg-ens33
配置如下内容( i 修改文件, :wq保存),重新启动网卡以生效 service network restart

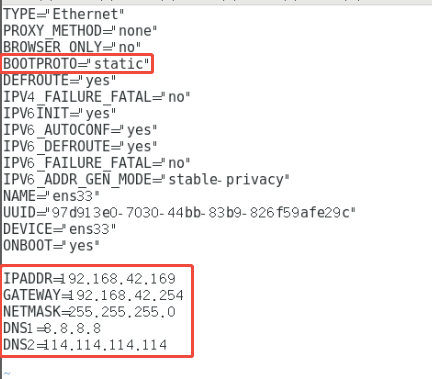
- 确保/etc/hosts文件里,ip和hostname的映射关系
打开hosts文件: vim /etc/hosts
配置 ip和主机的映射关系,确保后面的配置文件中只需要配置 admin 就可以找到IP地址
如果是分布式环境:其他服务器相同的配置,也可以将这个配置文件远程拷贝到其他服务器中
远程拷贝命令:scp -r /etc/hosts root@192.168.42.169: /etc/

- 确保免密登陆localhost有效
- 生成RSA加密算法的秘钥:ssh-keygen -t rsa (一路回车键即可生成)
- 查看生成的文件信息: cd ~/.ssh (如果没有权限,切换为root用户命令:su)
其中 known_hosts 文件为被访问记录文件 id_rsa id_rsa.pub 为免密登录的公钥和私钥文件- 将公钥发送至其他集群服务器:ssh-copy-id admin(目标IP或者hosts配置的主机名)
说明:在正式的分布式中,必须也要设置对本身服务器免密登录,否则启动时会无法启动本机的服务
也就是将 公钥 发送本身服务器一份:ssh-copy-id 自己服务器

- jdk和hadoqp的环境变量配置
打开profile文件进行配置:vim /etc/profile
在文件下方添加如下配置(JAVA_HOME HADOOP_HOME系统变量值要配置成对应的安装路径)
输入:source /etc/profile 命令,重新加载使其生效
如果是分布式环境:其他服务器相同的配置,也可以将这个配置文件远程拷贝到其他服务器中
远程拷贝命令:scp -r /etc/profile root@192.168.42.169: /etc/

配置相关XML文件
位置:hadoop安装路径/etc/hadoop/
主要包括:core-site.xm、hdfs-site.xml、workers、hadoop-env.sh
打开 core-site.xml 文件,配置如下内容
<!--设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://admin:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/data/hadoop/hadoop-3.3.5/tmp</value>
</property>
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
</property>

打开hdfs-site.xml文件,配置如下内容
<!-- 表示文件的备份数量。3表示一个文件备份三份,包括文件本身,一般这个设置与集群数量一致-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>admin:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。也就是网页管理页面-->
<property>
<name>dfs.namenode.http-address</name>
<value>admin:9870</value>
</property>

workers文件用来配置 datanode工作地址
说明:hadoop3.x版本这个文件名是 workers;而之前的2.x之前的版本文件名叫 slavels
(我这里支配了本机,因为我目前只设置了一台HADOOP服务,如果是多个服务集群则需要配置多个地址(映射名也可以,例如我hosts配置的 admin))
配置hadoop-env.sh脚本内容
设置启动集群的角色,后续会用到(项目中调用HADOOP会用到)
JAVA_HOME 不能配置为:JAVA_HOME=$JAVA_HOME(我自己配置之后启动会报找不到其他集群的JAVA_HOME)
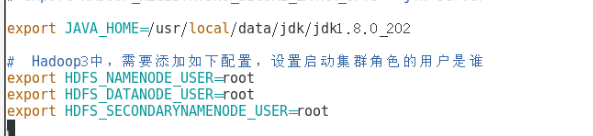
说明:
如果是完全分布式模式,应为所有服务器的hadoop的配置都是相同的,盱眙你可以将hadoop整个文件拷贝到其他服务器中去
远程拷贝命令:scp -r(递归拷贝) 需要拷贝的文件夹 root@ip地址:目标目录
例如:scp -r /usr/local/data/hadoop root@192.168.42.169:/usr/local/data
因为我配置了hosts映射也可以写成 :
scp -r /usr/local/data/hadoop admin:/usr/local/data
初始化HADOOP,启动
配置完以上内容后,即可初始化HDAOOP
初始化命令:hdfs namenode -format
执行启动Hadoop脚本:start-dfs.sh
启动之后: 输入命令 jps 可以查看当前hadoop运行的node信息
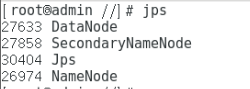
// TODO 持续更新:结合JAVA项目等

















 1745
1745


 到【灌水乐园】发言
到【灌水乐园】发言








