




 本文探讨了如何利用RDMA技术提高Spark在云计算环境中的处理速度,特别是针对Shuffle作业。RDMA允许直接内存访问,实现亚微秒延迟,相比传统的TCP Socket通信有显著优势。实验表明,使用RDMA进行Spark Shuffle可以提升2.18倍的效率。要使用SparkRDMA,需要Spark 2.0.0及以上版本、Java 8以及ROCE或Infiniband网络支持。
本文探讨了如何利用RDMA技术提高Spark在云计算环境中的处理速度,特别是针对Shuffle作业。RDMA允许直接内存访问,实现亚微秒延迟,相比传统的TCP Socket通信有显著优势。实验表明,使用RDMA进行Spark Shuffle可以提升2.18倍的效率。要使用SparkRDMA,需要Spark 2.0.0及以上版本、Java 8以及ROCE或Infiniband网络支持。
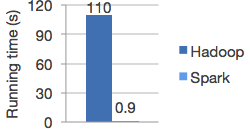
我们知道Spark 在大数据领域处理速度在同等条件下的Hadoop 的100倍
云计算的三种服务模式
Iaas : infrastructure as a Service 基础设置
Paas : platform as a service
saas : sowrware as a service
是否可以把Spark 部署在云计算以达到超大算力???? 偶然的一个机会使我结识一位UCloud 的一位朋友,他向我介绍了他们用的基础设施 RDMA ,我突发奇想是否可以把它用在Spark 上。以下是我的个人初步理解,后续在慢慢的补上
RDMA(Remote Direct Memory Access)技术全称远程直接内存访问,是一种直接内存访问技术,它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。这允许高通量、低延迟的网络通信
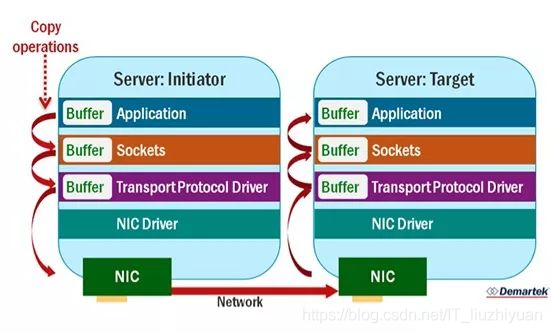
以上是传统 TCP Socket 数据传输
RMDA 技术 将以上的socket 进一步提升
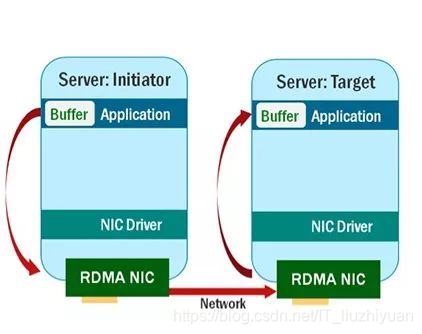
RDMA明显的优势:
- 直接硬件接口(Direct hardware interface),绕过内核和 TCP / IP 的 IO
- 亚微秒延迟
使用RDMA 运用在Spark Shuffle 作业数据的时,比标准的快2.18 倍
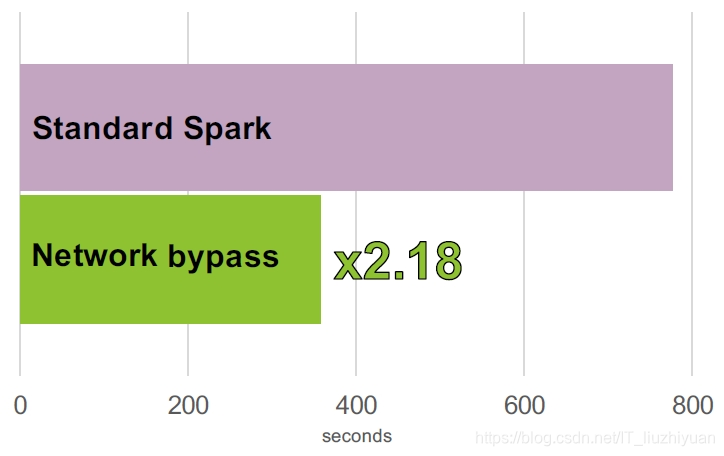
注意:SparkRDMA,我们需要 Apache Spark 2.0.0/2.1.0/2.2.0、Java 8 以及支持 RDMA 技术的网络(比如:RoCE 和 Infiniband)。
运行环境配置:
Spark 版本 2.X 及以上
java 版本 8
RDMA 支持的网络:ROCE 网络 或者是 Infiniband网络
什么是ROCE 网络:RDMA over Converged Ethernet
通过设置参数 spark.shuffle.manager = org.apache.spark.shuffle.sort.SortShuffleManager

















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









