







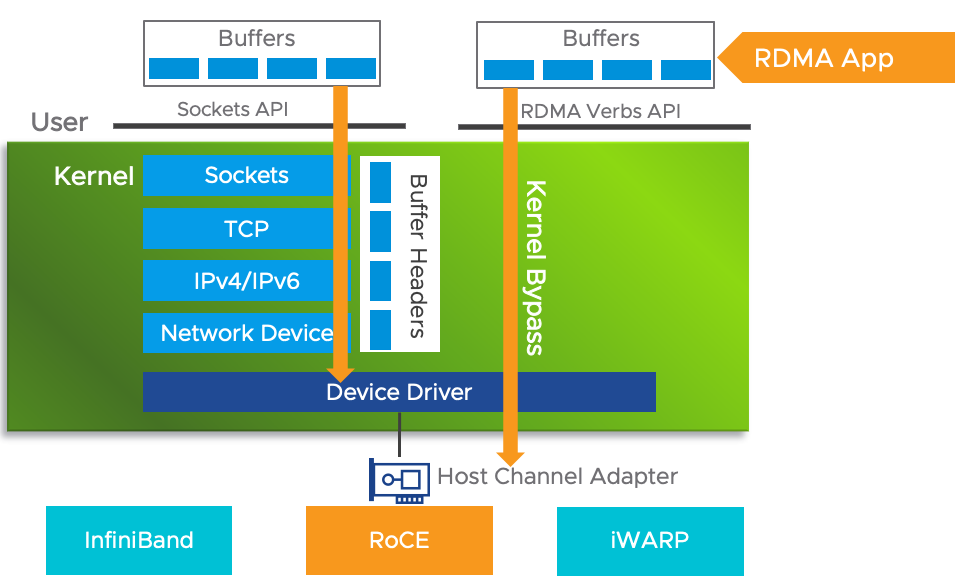
 RDMA(Remote Direct Memory Access)是一种高效的网络通信技术,它通过Kernel Bypass和Zero Copy实现低延迟、高带宽的数据传输,减少了CPU的占用。RDMA技术有InfiniBand、RoCE和iWARP三种实现,其中InfiniBand性能最佳但成本较高,RoCE和iWARP则是在以太网上实现,RoCEv2支持IP路由。RDMA的核心概念包括Memory Registration、Queues和数据传输操作如RDMA Read/Write。该技术广泛应用于HPC、存储和数据中心,以减少网络通信对CPU的负担,提高系统性能。
RDMA(Remote Direct Memory Access)是一种高效的网络通信技术,它通过Kernel Bypass和Zero Copy实现低延迟、高带宽的数据传输,减少了CPU的占用。RDMA技术有InfiniBand、RoCE和iWARP三种实现,其中InfiniBand性能最佳但成本较高,RoCE和iWARP则是在以太网上实现,RoCEv2支持IP路由。RDMA的核心概念包括Memory Registration、Queues和数据传输操作如RDMA Read/Write。该技术广泛应用于HPC、存储和数据中心,以减少网络通信对CPU的负担,提高系统性能。
目录
2.1 TOE (TCP/IP协议处理工作从CPU转移到网卡)
5. 核心概念5.1 Memory Registration(MR) | 内存注册
6.1 RDMA Send | RDMA发送(/接收)操作 (Send/Recv)
6.2 RDMA Read | RDMA读操作 (Pull)
6.3 RDMA Write | RDMA写操作 (Push)
6.4 RDMA Write with Immediate Data | 支持立即数的RDMA写操作
作者:bandaoyu 本文随时更新,地址:https://blog.youkuaiyun.com/bandaoyu/article/details/112859853
0、前言
RDMA 学习资料总目录:https://blog.youkuaiyun.com/bandaoyu/article/details/120485737
转载OR摘抄自:https://blog.youkuaiyun.com/qq_21125183/article/details/86522475
十分推荐文章:《RDMA 架构与实践》 连接:
https://houmin.cc/posts/454a90d3/ 或 http://t.csdn.cn/lOoTT
一、技术背景
(摘自:https://houmin.cc/posts/454a90d3/)
1 传统的 TCP/IP 网络通信的弊端
计算机网络通信中最重要两个衡量指标主要是 带宽 和 延迟。
通信延迟主要是指:
Transmission Delay:
- The time taken to transmit a packet from the host to the transmission medium
- 计算方式:Delayt=L/BandwidthDelayt=L/Bandwidth,其中 L 是要传输的数据包 L bit,Bandwidth 为链路带宽
- 如果两端的带宽高,则传输时间短,传输延迟低
Propagation delay
After the packet is transmitted to the transmission medium, it has to go through the medium to reach the destination. Hence the time taken by the last bit of the packet to reach the destination is called propagation delay.
计算方法:Delayp=Distance/VelocityDelayp=Distance/Velocity,其中 Distance 是传输链路的距离,Velocity 是物理介质传输速度
1 2Velocity =3 X 108 m/s (for air) Velocity= 2.1 X 108 m/s (for optical fibre)Queueing delay
- Let the packet is received by the destination, the packet will not be processed by the destination immediately. It has to wait in queue in something called as buffer. So the amount of time it waits in queue before being processed is called queueing delay.
- In general we can’t calculate queueing delay because we don’t have any formula for that.
Processing delay
- message handling time at sending/receive ends
- buffer管理、在不同内存空间中消息复制、以及消息发送完成后的系统中断
现实计算机网络中的通信场景中,主要是以发送小消息为主,因此处理延迟是提升性能的关键。
传统的 TCP/IP 网络通信,数据需要通过用户空间发送到远程机器的用户空间,在这个过程中需要经历若干次内存拷贝:
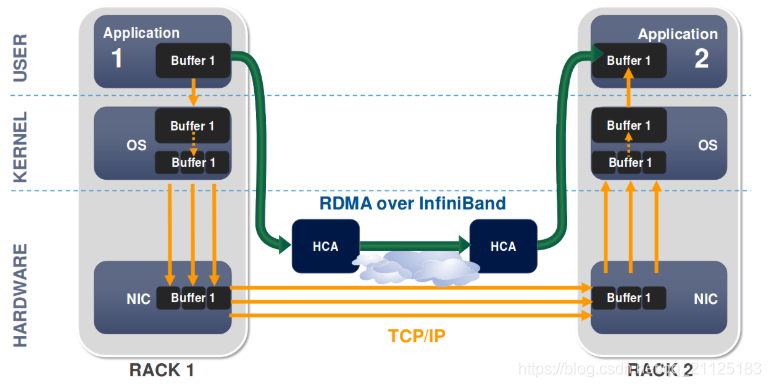
RDMA 架构与实践:https://houmin.cc/posts/454a90d3/
如上图,在传统模式下,两台服务器上的应用之间传输数据,过程是这样的:
- 首先要把数据从应用缓存拷贝到Kernel中的TCP协议栈缓存;
- 然后再拷贝到驱动层;
- 最后拷贝到网卡缓存。
- 数据发送方需要讲数据从用户空间 Buffer 复制到内核空间的 Socket Buffer
- 数据发送方要在内核空间中添加数据包头,进行数据封装
- 数据从内核空间的 Socket Buffer 复制到 NIC Buffer 进行网络传输
- 数据接受方接收到从远程机器发送的数据包后,要将数据包从 NIC Buffer 中复制到内核空间的 Socket Buffer
- 经过一系列的多层网络协议进行数据包的解析工作,解析后的数据从内核空间的 Socket Buffer 被复制到用户空间 Buffer
- 这个时候再进行系统上下文切换,用户应用程序才被调用
多次内存拷贝需要CPU多次介入,导致处理延时大,达到数十微秒。同时整个过程中CPU过多参与,大量消耗CPU性能,影响正常的数据计算。
在高速网络条件下,传统的 TPC/IP 网络在主机侧数据移动和复制操作带来的高开销限制了可以在机器之间发送的带宽。为了提高数据传输带宽,人们提出了多种解决方案,这里主要介绍下面两种:
- TCP Offloading Engine (TOE :http://t.csdn.cn/8LgFl)
- Remote Direct Memroy Access (RDMA)
2 新的网络通信技术(TOE and RDMA)
2.1 TOE (TCP/IP协议处理工作从CPU转移到网卡)
TOE (TCP Offloading Engine),在主机通过网络进行通信的过程中,CPU 需要耗费大量资源进行多层网络协议的数据包处理工作,包括数据复制、协议处理和中断处理。当主机收到网络数据包时,会引发大量的网络 I/O 中断,CPU 需要对 I/O 中断信号进行响应和确认。为了将 CPU 从这些操作中解放出来,人们发明了TOE(TCP/IP Offloading Engine)技术,将上述主机处理器的工作转移到网卡上。TOE 技术需要特定支持 Offloading 的网卡,这种特定网卡能够支持封装多层网络协议的数据包。
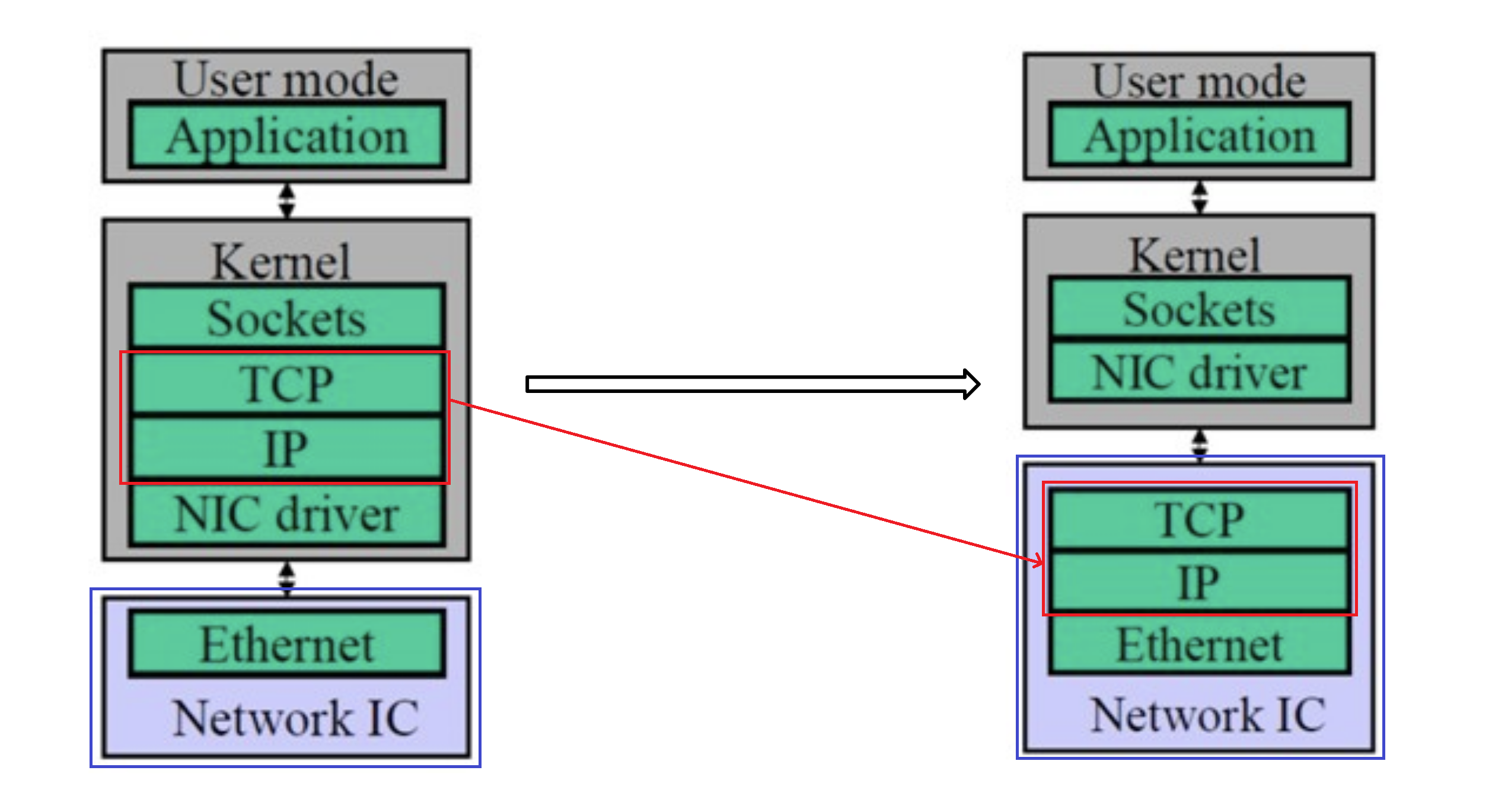
- TOE 技术将原来在协议栈中进行的IP分片、TCP分段、重组、checksum校验等操作,转移到网卡硬件中进行,降低系统CPU的消耗,提高服务器处理性能。
- 普通网卡处理每个数据包都要触发一次中断,TOE 网卡则让每个应用程序完成一次完整的数据处理进程后才触发一次中断,显著减轻服务器对中断的响应负担。
- TOE 网卡在接收数据时,在网卡内进行协议处理,因此,它不必将数据复制到内核空间缓冲区,而是直接复制到用户空间的缓冲区,这种“零拷贝”方式避免了网卡和服务器间的不必要的数据往复拷贝。
2.2 RDMA (绕过CPU,数据直接‘传’到对端内存)
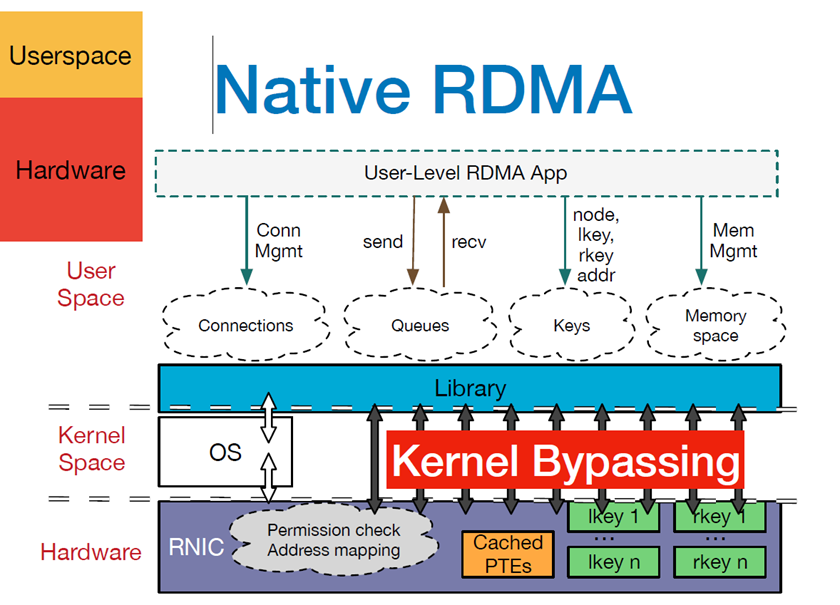
RDMA (Remote Direct Memroy Access )为了消除传统网络通信带给计算任务的瓶颈,我们希望更快和更轻量级的网络通信,由此提出了RDMA技术。RDMA利用 Kernel Bypass 和 Zero Copy技术提供了低延迟的特性,同时减少了CPU占用,减少了内存带宽瓶颈,提供了很高的带宽利用率。RDMA提供了给基于 IO 的通道,这种通道允许一个应用程序通过RDMA设备对远程的虚拟内存进行直接的读写。
RDMA 技术有以下几个特点:
- CPU Offload:无需CPU干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充
- Kernel Bypass:RDMA 提供一个专有的 Verbs interface 而不是传统的TCP/IP Socket interface。应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换
- Zero Copy:每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
下面是 RDMA 整体框架架构图,从图中可以看出,RDMA 提供了一系列 Verbs 接口,可在应用程序用户空间,操作RDMA硬件。RDMA绕过内核直接从用户空间访问RDMA 网卡。RNIC(RDMA 网卡,RNIC(NIC=Network Interface Card ,网络接口卡、网卡,RNIC即 RDMA Network Interface Card)中包括 Cached Page Table Entry,用来将虚拟页面映射到相应的物理页面。
扩展知识:TOE 和 RDMA的区别、TOE、RDMA、smartNIC 、DPU是什么和区别:
相同点:
都具有给cpu减负的功能
不同点:
1、工作原理不同,见上面的简介。
2、RDMA的网卡使用需要两端都支持RDMA技术的网卡才能发挥,TOE只需要单端即可。
3、TOE网卡和RDMA网卡,都属于SmartNIC。
更多和更新的内容见: http://t.csdn.cn/mLK6h
连接:https://blog.youkuaiyun.com/bandaoyu/article/details/122868925
二、RDMA 详解(发展历程和3种技术实现)
1. DMA和RDMA概念
RDMA = Remote DMA
1.1 DMA
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。
DMA(直接内存访问)是一种能力,允许在计算机主板上的设备通过DMA直接把数据发送到目标内存中去,数据搬运不需要CPU的参与。
DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3837
3837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









