



 本文详细介绍如何使用Python爬虫技术抓取直播平台上的短视频,包括分析网页、发送请求、解析JSON数据及保存视频的方法。
本文详细介绍如何使用Python爬虫技术抓取直播平台上的短视频,包括分析网页、发送请求、解析JSON数据及保存视频的方法。
妙哇
又到了一年一度的让人诗兴大发的季节
有不少小伙伴们此时此刻颇想吟诗一首:
啊!大海!全都是水!
啊!夏天!全都是腿!在这样一个适合晒腿的季节里,“老司机”带你用 Python 爬取一个都是小姐姐的视频网站~~~
莫问视频平台哪家强!存在自己硬盘才最香!
目录
1 项目简介
1.1 项目名称
直播平台小视频爬取
1.2 项目介绍
本项目将运用Python爬虫技术,爬取直播间海量小姐姐短视频。
平台播放能力再强也抵不过视频存到自己硬盘中香。
1.3 项目亮点
- 动态数据抓包
- json数据解析方法
- 视频数据保存
1.4 适合人群
- Python零基础、对爬虫感兴趣的
- 对妹子图片、视频感兴趣的
- 晚上睡不着觉的
1.5 环境介绍
- Python环境:3.8.2
- python编译器:JetBrains PyCharm 2018.1.2 x64
- 第三方库及模块:requests库、json库、re模块
2 项目实现
2.1 思路详解
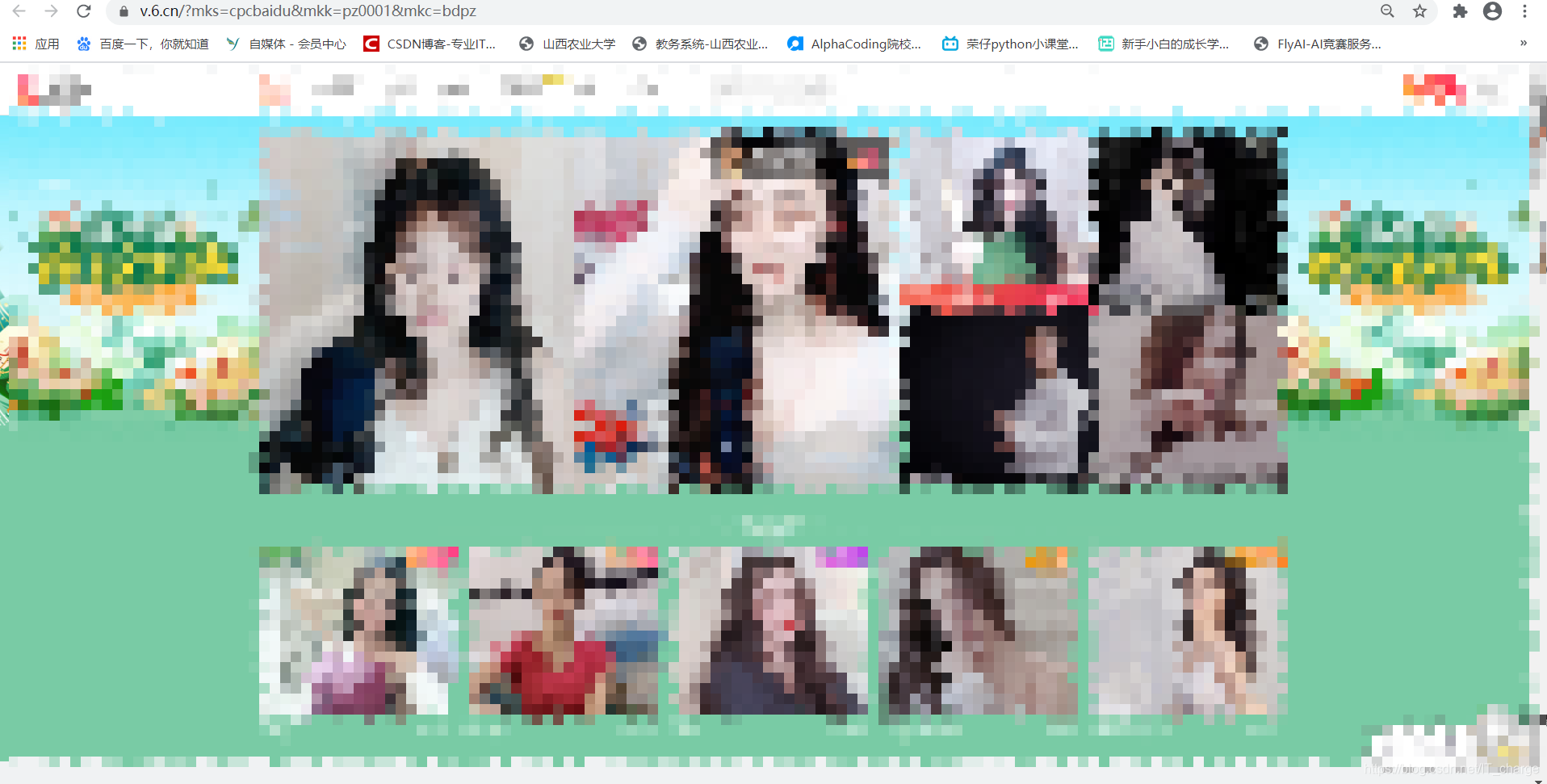
首先,找到目标网站:
爬取以前,有必要先对爬虫大致思路做一介绍:
- 1.分析网页:确定爬取url路径,headers参数
- 2.发送请求:requests库,模拟浏览器发送请求,获取响应数据
- 3.解析数据:json模块,把json字符串转化成python可交互的数据类型
- 4.保存数据:保存在目标文件夹中
按照这一思路,轻轻松松,就不愁小姐姐爬不到啦![]()
值得注意的是,拉倒页面最下方动态加载出下一页的内容的形式叫异步加载
在进行 F12 键“检查”时,异步加载数据包内容具体在 Network 中的 XHR 中
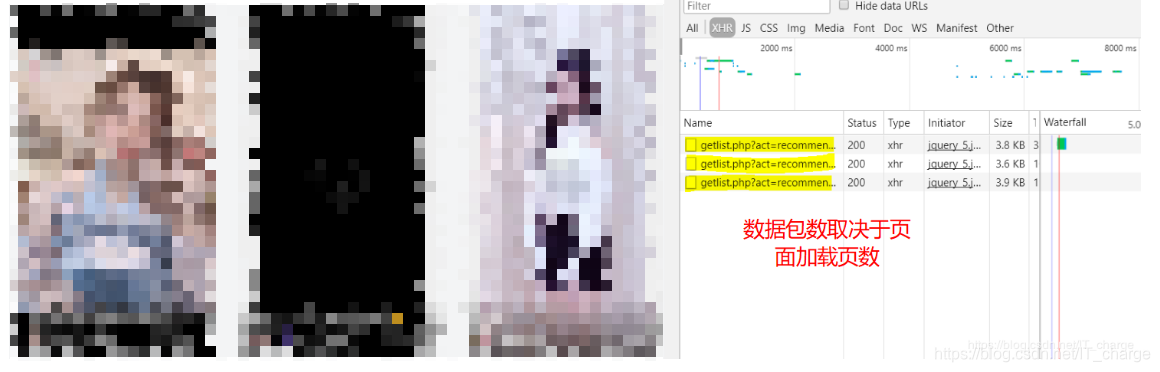
具体每个数据包中是什么内容呢?是否是我们想要的目标呢?与当前页面对应数据是否一致呢?
这些问题只需点击每个数据包,在其中的 Preview 和 Response 中查看即可
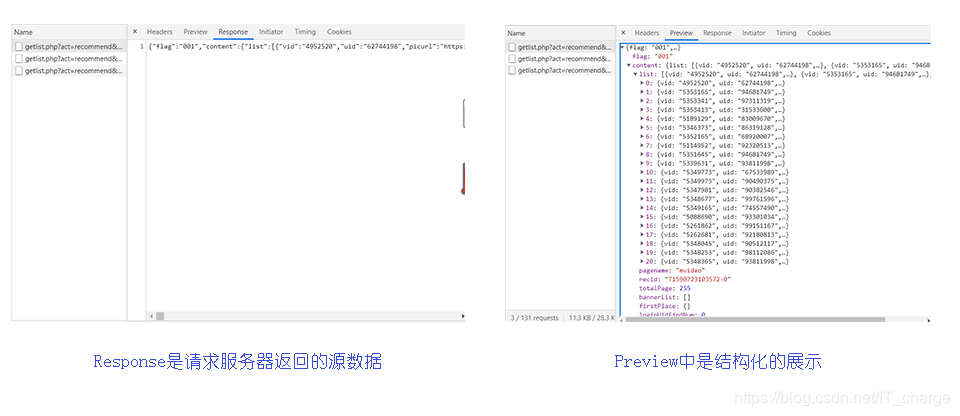
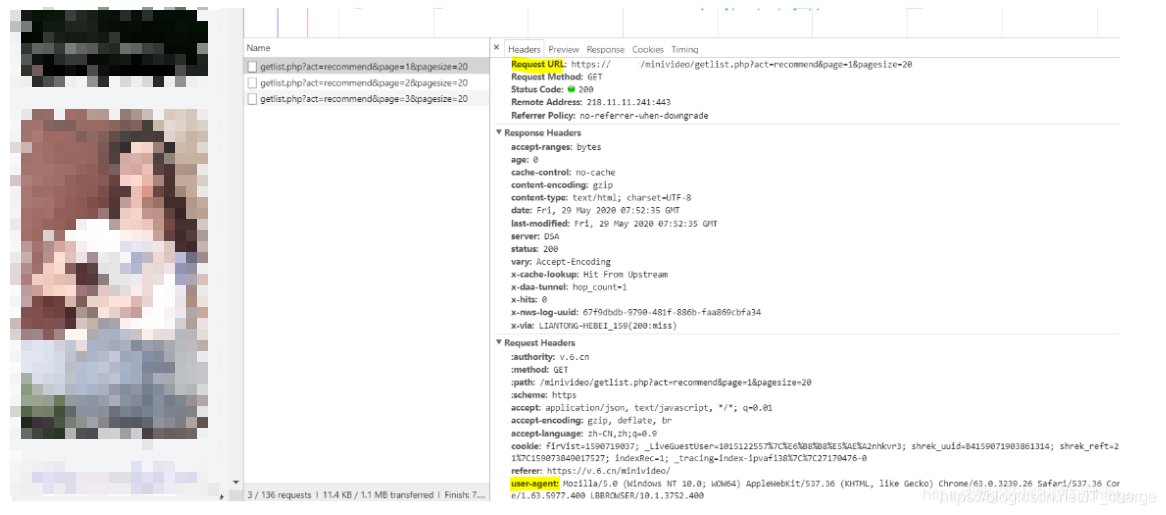
下面从结构化的展示中随便点开一个,可以看到视频题目和作者昵称与页面视频是一致的,所以这个就是我们接下来要处理的包
上面提到,爬虫第一步确定目标的url,前期准备了这么长时间就是一直在反复确定该数据包是不是我们想要的那个,既然前面已经确定了,也就意味着目标的url确定了,具体在这个位置找到目标的url以及其对应的headers参数(浏览器标识):
 OK,准备差不多了,开始撸代码
OK,准备差不多了,开始撸代码
1.分析网页:确定爬取url路径,headers参数(这里注意headers是字典格式【键值对】)
# 获取 URL 地址
url = '这里填上图中的Requests URL'
# headers 参数确定
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}2.发送请求:requests库,模拟浏览器发送请求,获取响应数据
这里用到requests第三方库,先导库
import requests接下来模拟浏览器发送请求并打印检查一下是否获取到了数据
# 模拟浏览器发送 URL 地址请求
response = requests.get(url, headers=headers)
# 去除 response 响应对象中的文本数据
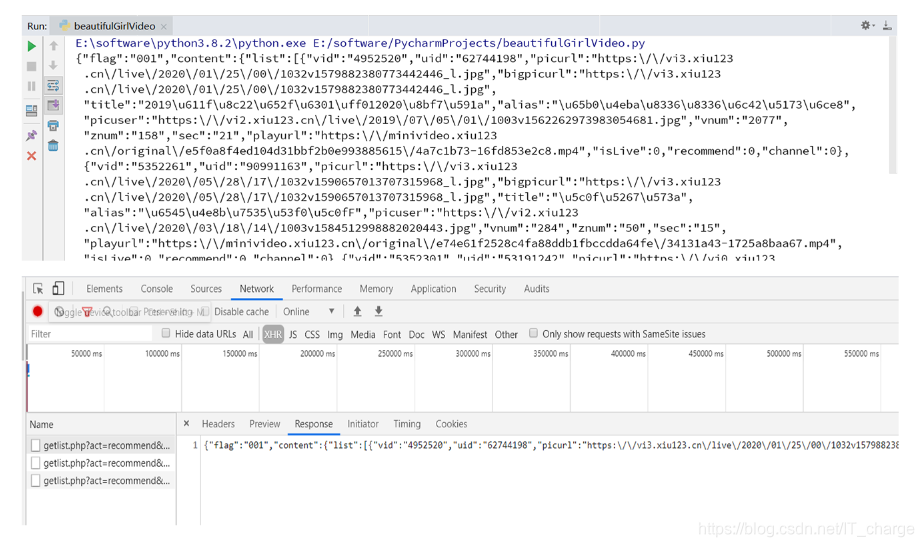
response_data = response.text
print(response_data)我们发现打印运行结果与浏览器中Response结果是一致的
3.解析数据:json模块,把json字符串转化成python可交互的数据类型
因为解析数据要用到json模块,所以先导库
import json解析数据第一步:转换数据类型(字典类型)
# 转换数据类型
dict_data = json.loads(response_data)
print(dict_data)
解析数据第二步:解析数据(所得值为列表形式)
在这一步,需要提前确定json数据中我们想要的信息,这里推荐一个网站:http://json.cn/(可对json格式数据转换)
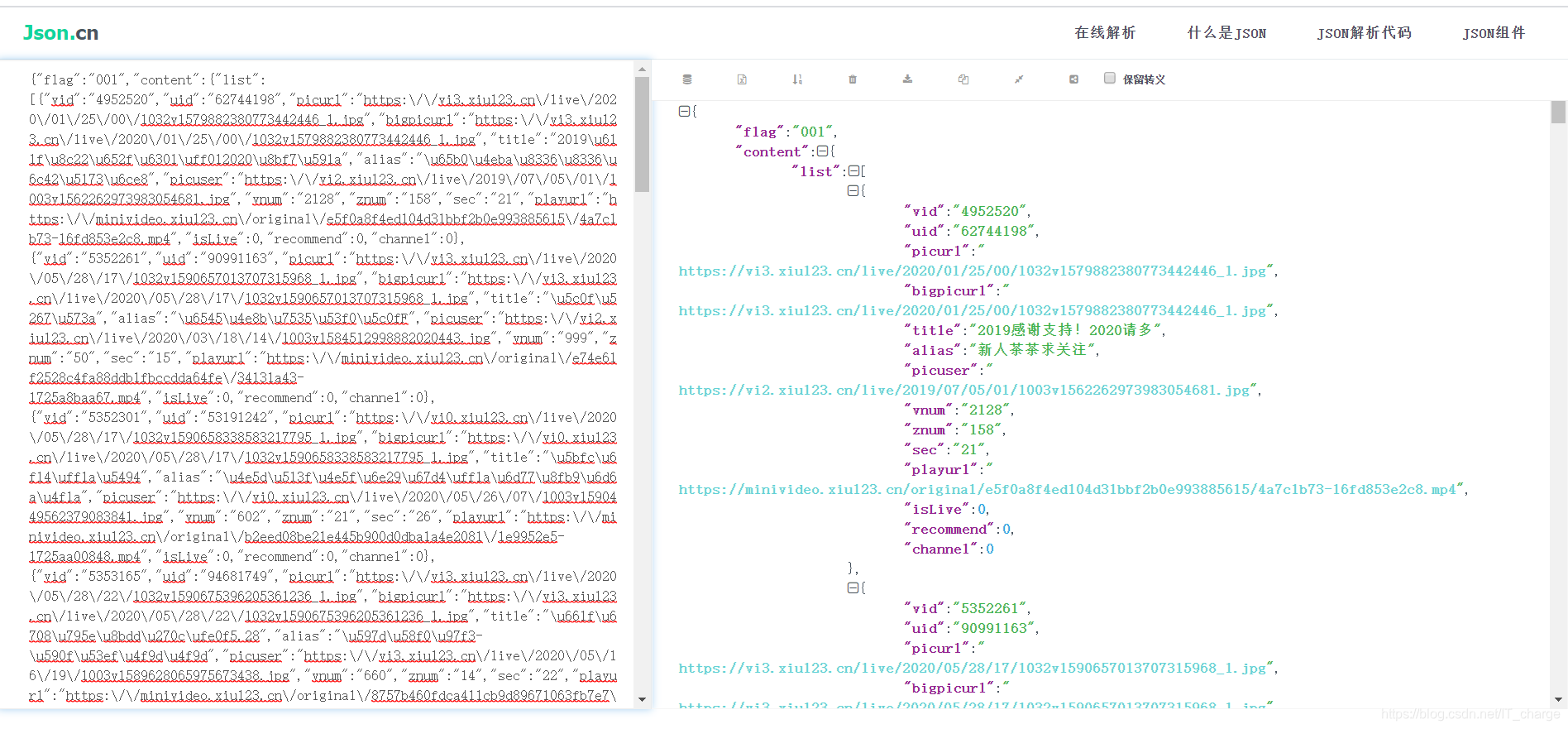
或者干脆从这个位置看也行
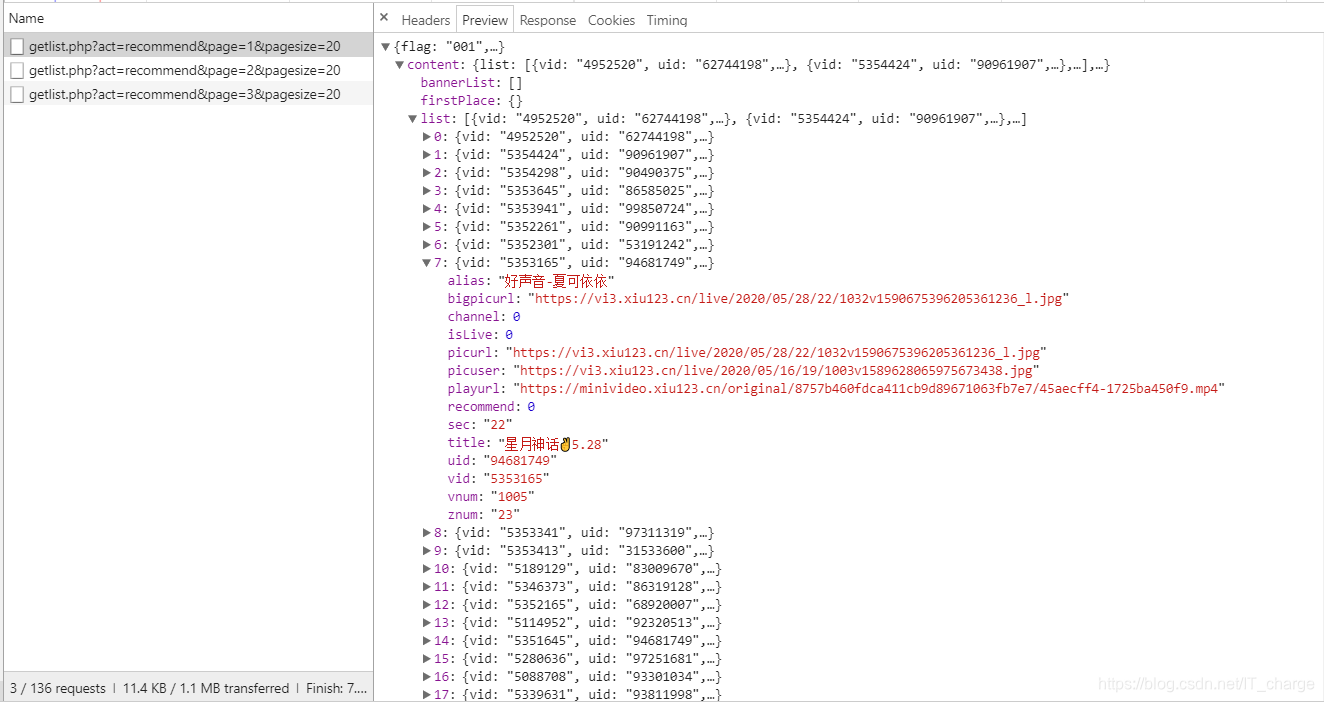
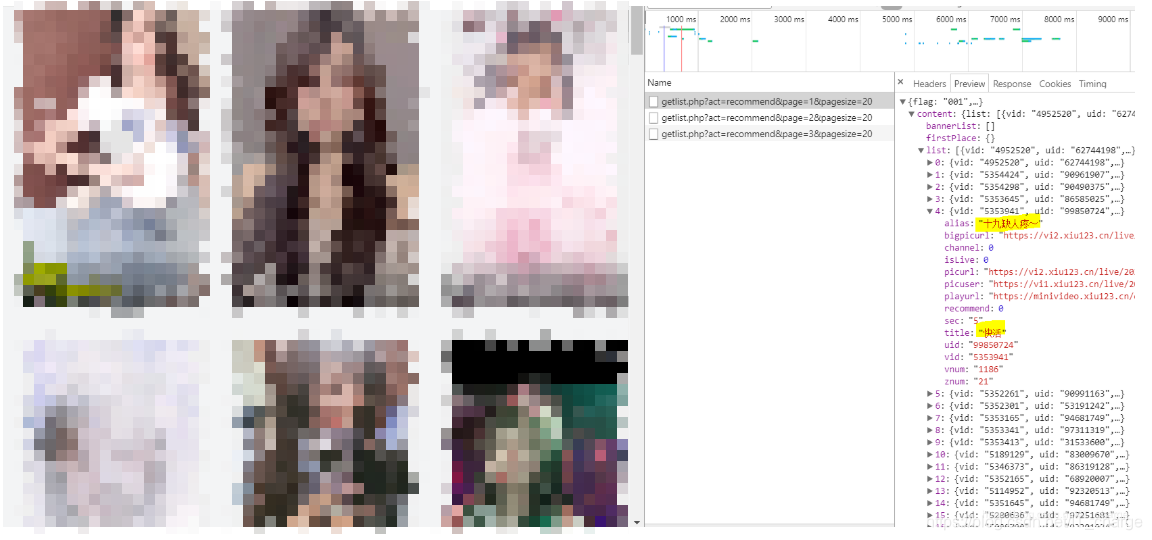
通过上图转换我们发现,我们想要的信息在content的list中
具体而言,视频名称:content中的list中的title;作者名称:content中的list中的alias。
# 数据解析
data_list = dict_data['content']['list']
print(data_list)
在这里我们发现有好多字典类型的数据,都在列表中,那么怎么取出呢?遍历它
# 遍历
for data in data_list:
print(data)
进行到这里,始终不要忘了我们的目的,爬取视频
这时分析字典中的数据,我们发现,“键”playurl的“值”就是视频的url链接地址
当然这里也可以给每个爬取到的视频添加其原本的视频名称及作者昵称等信息(在title和alias中)
# 遍历
for data in data_list:
# print(data)
video_title = data['title'] # 视频文件名
video_alias = data['alias'] # 视频作者名
video_playurl = data['playurl'] # 视频 url
print('视频:', video_title, '作者:', video_alias, 'url地址:', video_playurl) 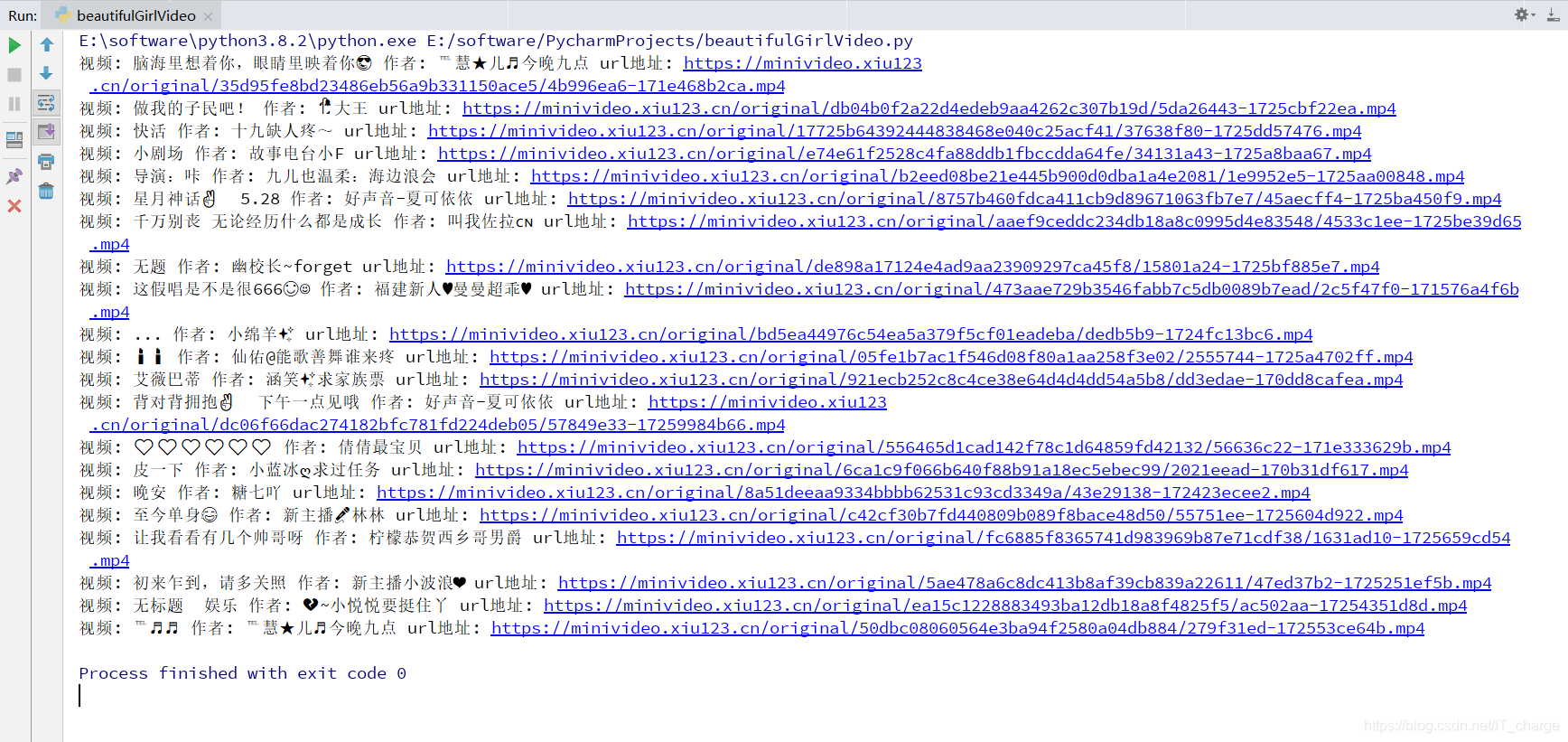
与前面类似,接下来再模拟浏览器发送视频的 URL 请求
# 发送视频 URL 请求
video = requests.get(video_playurl, headers=headers).content4.保存数据:保存在目标文件夹中
保存文件这里用 with open 方法
# 保存数据
with open(r'F:\Beautiful Girl Video\\' + video_title + '_' + video_alias + '.mp4', 'wb') as video_file:
video_file.write(video)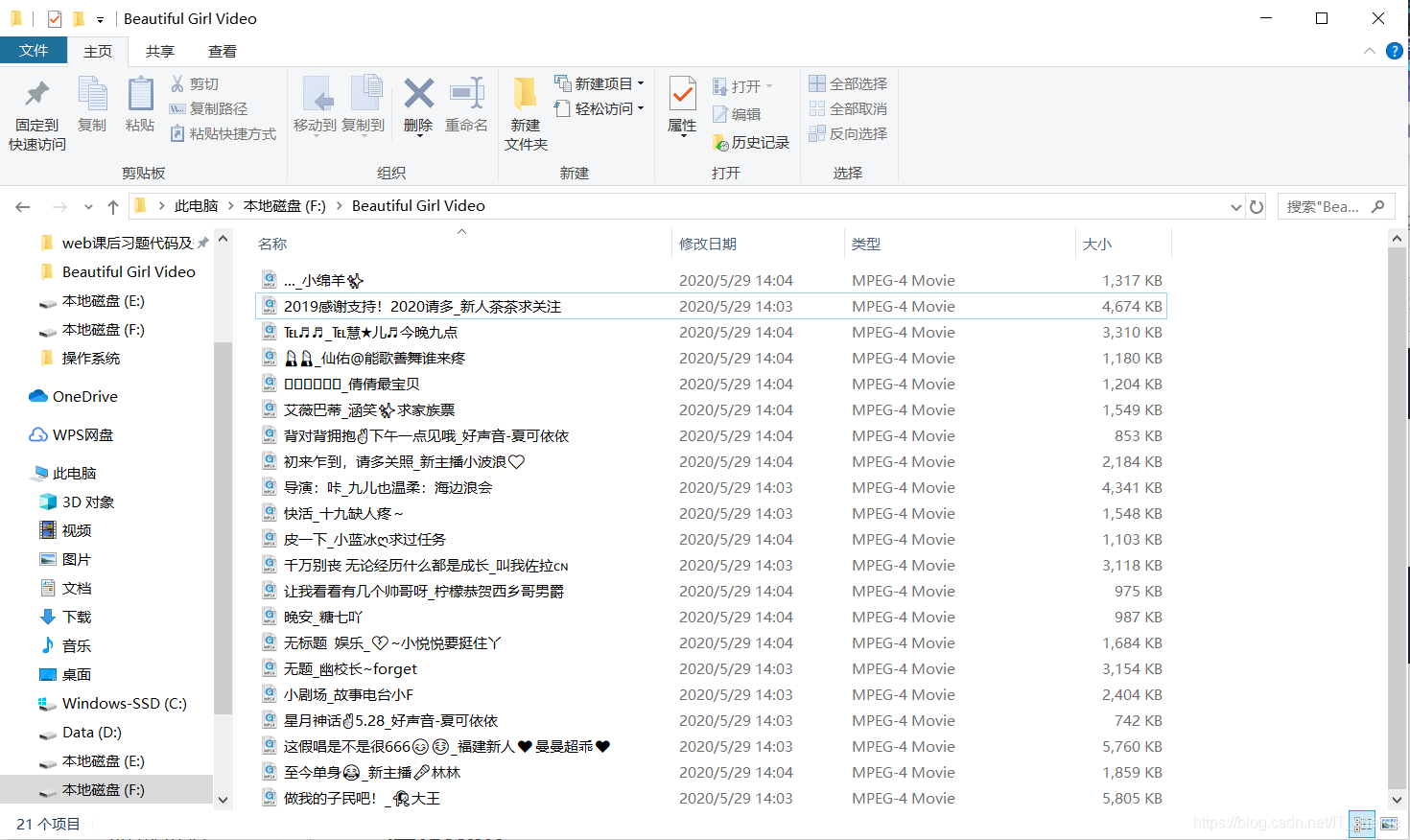
嘶~~啊~~真香![]()
那么上面是爬取了一页的小姐姐视频,那么2页,3页……怎样把辣么多小姐姐全部获取到呢?
接下来就分析小姐姐视频数据包的url地址有什么规律了
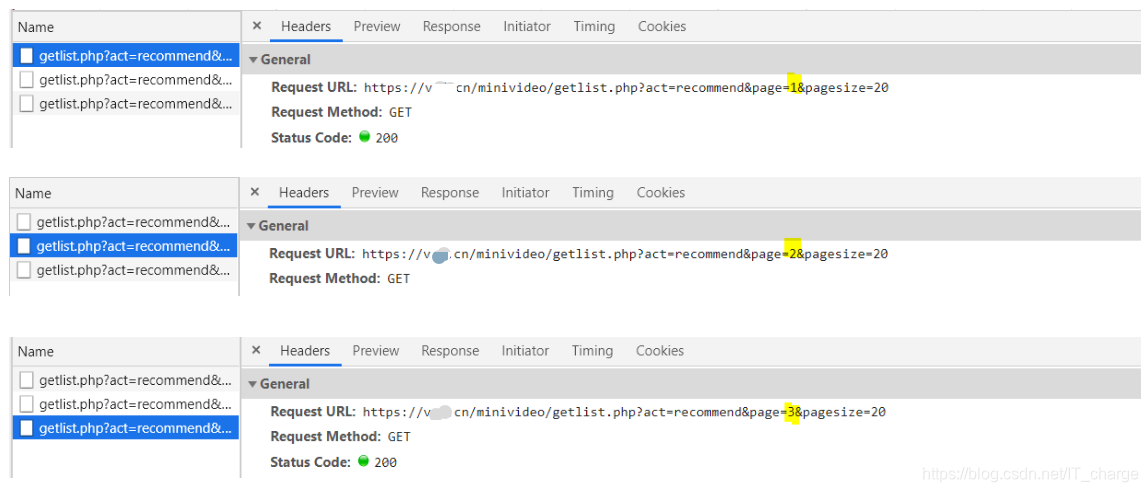
……
很容易发现,所有的url地址就一处地方不同,1代表第一页,2代表第二页……
这里直接用for循环即可
for page in range(1, 5):这里还有一个问题,若视频名称有“[”、“]”、“_”等出现会报错,那么在这里需要另外设计一下替换非法字符
def change_title(title):
# 替换非法字符
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]")
new_title = re.sub(pattern, "_", title)
return new_title2.2 总观代码
import requests
import json
import re
def change_title(title):
# 替换非法字符
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]")
new_title = re.sub(pattern, "_", title)
return new_title
# 示例爬取5页数据
for page in range(1, 5):
print('---------------正在爬取第{}页小姐姐视频-------------------'.format(page))
# 获取 URL 地址
url = 'https://******/minivideo/getlist.php?act=recommend&page={}&pagesize=20'.format(page)
# headers 参数确定
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
# 模拟浏览器发送 URL 地址请求
response = requests.get(url, headers=headers)
# 去除 response 响应对象中的文本数据
response_data = response.text
# print(response_data)
# 转换数据类型
dict_data = json.loads(response_data) # 字典
# print(dict_data)
# 数据解析
data_list = dict_data['content']['list'] # 列表
# print(data_list)
# 遍历
for data in data_list:
# print(data)
video_title = data['title'] # 视频文件名
video_alias = data['alias'] # 视频作者名
video_playurl = data['playurl'] # 视频 url
# print('视频:', video_title, '作者:', video_alias, 'url地址:', video_playurl)
print('正在下载视频:', video_title)
new_title = change_title(video_title)
# 发送视频 URL 请求
video = requests.get(video_playurl, headers=headers).content
# 保存数据
with open(r'F:\Beautiful Girl Video\\' + new_title + '_' + video_alias + '.mp4', 'wb') as video_file:
video_file.write(video)
print('视频下载成功…… \n')
print('---------------第{}页小姐姐视频爬取完毕-------------------'.format(page))2.3 运行效果
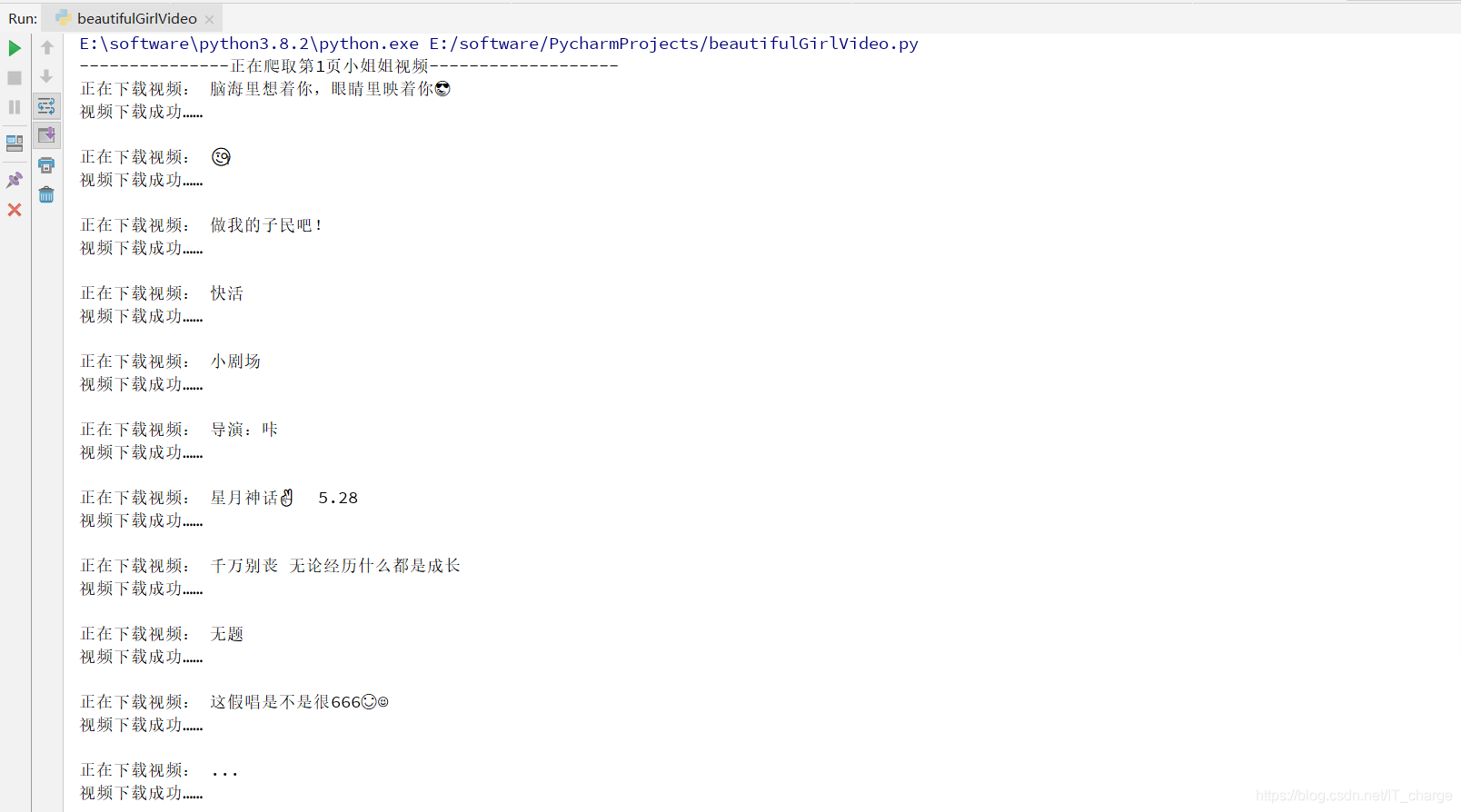
……
再看一下文件夹
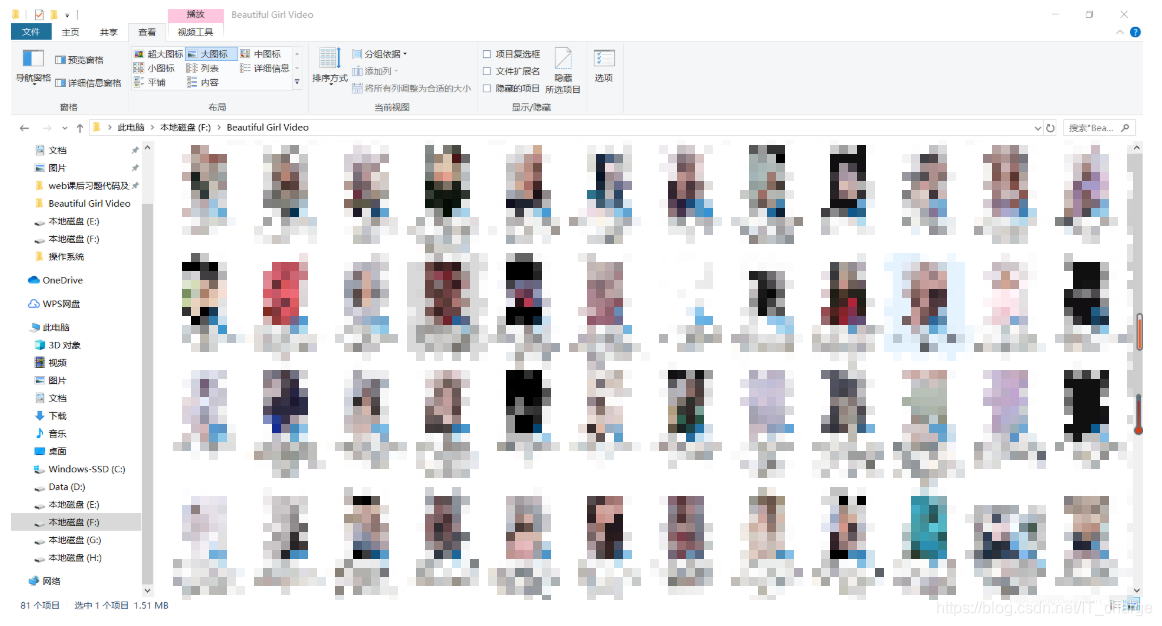
哈哈,骚年们!你们要的小姐姐至此爬取完毕啦啦啦啦~~~![]()
3 项目声明
版权声明:本专栏全部为优快云博主「IT_change」的原创文章,遵循 CC 4.0 BY-SA 版权协议。
转载请附上原文出处链接及本声明。
感谢阅读!感谢支持!感谢关注!
更多原创文章请点击我的→主页
END


















 392
392




 到【灌水乐园】发言
到【灌水乐园】发言









