 CSV文件编码问题解析
CSV文件编码问题解析





 本文详细解析了在使用pandas读取CSV文件时遇到的UnicodeDecodeError错误,并提供了修改文件编码方式的解决方案,避免因Excel编辑导致的编码问题。
本文详细解析了在使用pandas读取CSV文件时遇到的UnicodeDecodeError错误,并提供了修改文件编码方式的解决方案,避免因Excel编辑导致的编码问题。
写在前面:
由于优快云的审查机制的原因,更多博客内容请访问我的个人博客或GitHub:
- 个人博客地址:个人博客
- GitHub地址:GitHub
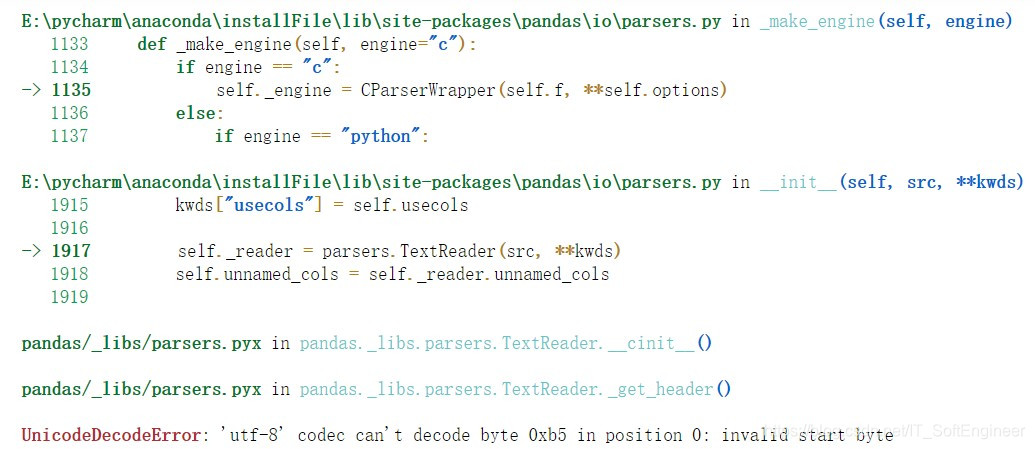
你是否有过之前用pd.read打开csv文件都正常,但突然有一天运行以前的代码就突然报错:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb5 in position 0: invalid start byte,然后再谷歌中搜索答案发现普遍的解决方案就是修改编码方式:类似于encoding="gbk"这类的,然后运行后仍然报错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xae in position 8: illegal multibyte sequence,如果你遇到的是这种情况请读下去
错误说明:这里通过这两次报错很明显发现就是文件的编码方式不对,换句话说就是utf-8(默认pd打开csv的方式)或者gbk这两种编码方式都打不开csv文件,所以解决的办法非常简单,就是修改csv文件的编码方式为uft-8或者gbk,这里用修改为utf-8为例
不指定编码方式,用默认编码方式读取csv文件
path = "./tmp_domestic/"
files = os.listdir(path)
usa_date2 = []
usa_new2 = []
for i in files:
usa_data = pd.read_csv("./tmp_domestic/{}".format(i), index_col=0) # 默认用utf-8编码方式打开
date = i[-9:-4]
usa_new_tmp = usa_data.loc["香港"]["现有确诊"]
usa_new2.append(int(usa_new_tmp))
usa_date2.append(date)
报错:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb5 in position 0: invalid start byte,意思就是utf-8编码方式不能解码你要读取的文件
修改编码方式为gbk进行调试
path = "./tmp_domestic/"
files = os.listdir(path)
usa_date = []
usa_new = []
for i in files:
usa_data = pd.read_csv("./tmp_domestic/{}".format(i), index_col=0,encoding="gbk") # 修改编码方式为gbk进行调试
date = i[-9:-4]
usa_new_tmp = usa_data.loc["江苏"]["现有确诊"]
usa_new2.append(int(usa_new_tmp))
usa_date2.append(date)
报错:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xae in position 8: illegal multibyte sequence,意思是gbk也无法解码改文件
解决方案:找到你要读取的文件,然后用记事本打开,然后点击另存为,出现如下界面
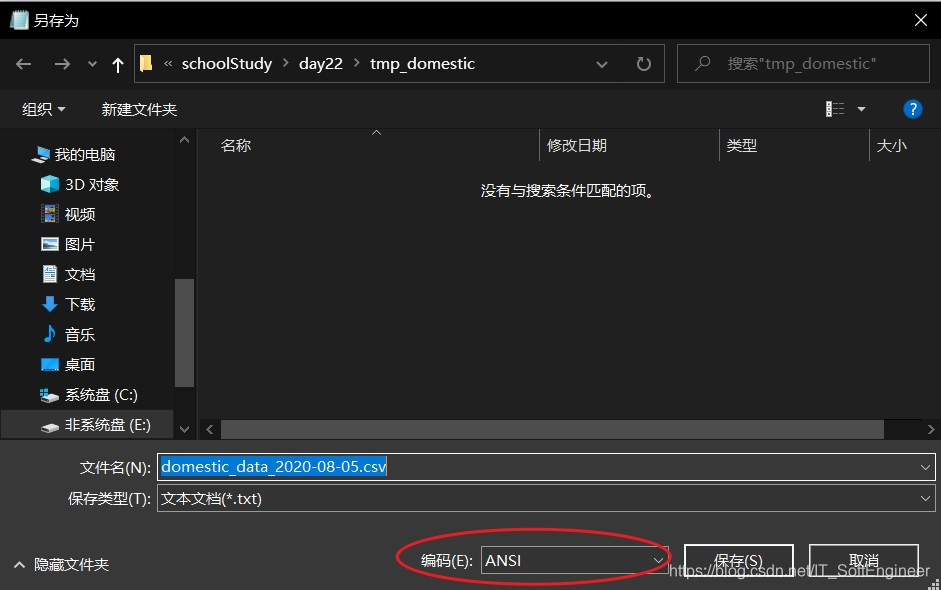
你会发现你要读取的文件既不是utf-8也不是gbk,而是另外一种编码方式,这也就是你为什么读取不了的原因,所以你需要把编码方式改为utf-8然后覆盖原文件保存,然后运行之前的代码即可正常运行
path = "./tmp_domestic/"
files = os.listdir(path)
usa_date = []
usa_new = []
for i in files:
usa_data = pd.read_csv("./tmp_domestic/{}".format(i), index_col=0)
date = i[-9:-4]
usa_new_tmp = usa_data.loc["香港"]["现有确诊"]
usa_new.append(int(usa_new_tmp))
usa_date.append(date)
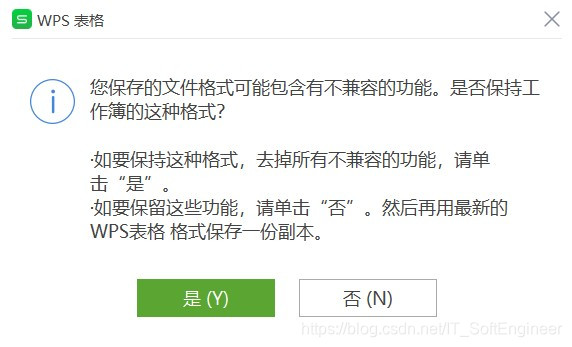
说到文件编码方式被改变的原因,最大的可能就是你通过excell文件打开了csv文件,然后修改了里面的内容导致编码方式改变,在你修改并要保存的时候回出现这样的提示,就是在告诉你文件的相关内容被修改了,所以以后如果要修改csv文件的内容不要直接在excell中修改保存要用记事本打开并保存,否则就会出现编码方式改变导致无法读取的情况

















 3247
3247






 到【灌水乐园】发言
到【灌水乐园】发言







