




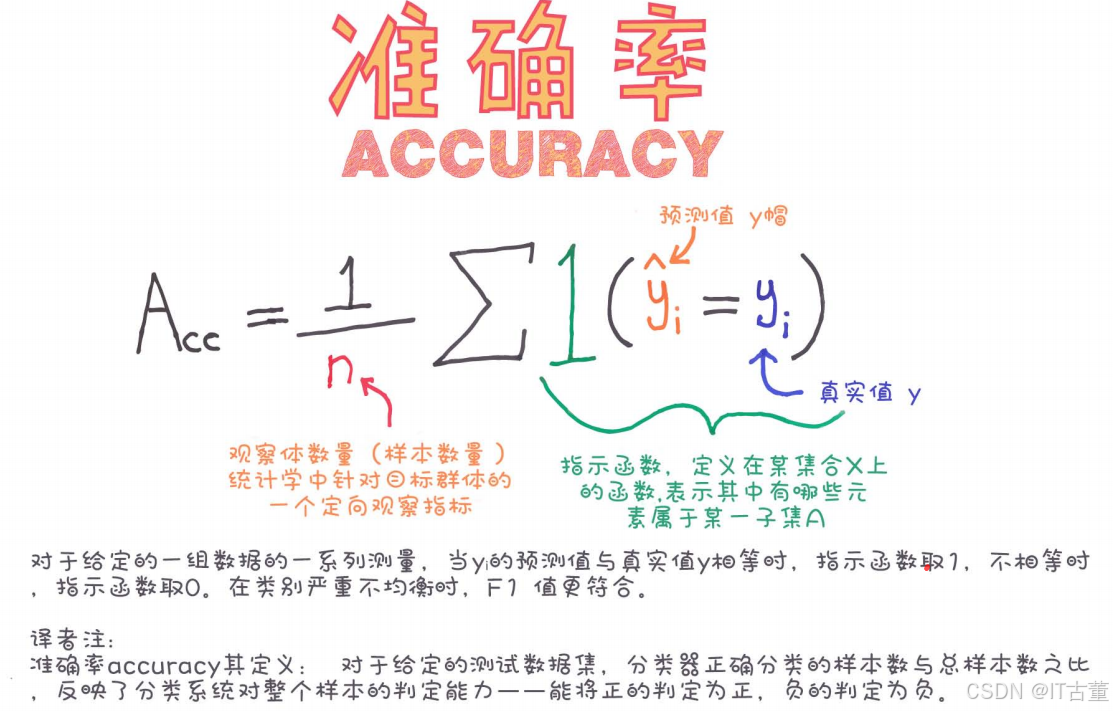
准确率(Accuracy) 是分类问题中最常见的评价指标之一,表示模型预测正确的样本数量占总样本数量的比例。准确率简单易懂,但在数据不平衡的情况下可能无法很好地反映模型的实际表现。
1. 定义
准确率的计算公式如下:
其中:
- TP (True Positive):真正例,模型正确预测为正类的样本数。
- TN (True Negative):真反例,模型正确预测为负类的样本数。
- FP (False Positive):假正例,模型错误地预测为正类的负类样本数。
- FN (False Negative):假反例,模型错误地预测为负类的正类样本数。
2. 应用场景
准确率常用于分类任务中,尤其是在类别分布均衡的情况下。它适用于一些需要评估总体分类表现的场景,比如:
- 简单的二分类任务,如垃圾邮件分类、肿瘤检测等。
- 类别分布均衡的多分类任务。
3. 优点
- 直观简洁:计算公式简单,容易理解。
- 常见使用:几乎所有机器学习框架和工具都提供了准确率的计算。
4. 缺点
- 数据不平衡问题:在类别分布不均衡的情况下,准确率可能无法反映模型的真实性能。例如,在一个类别远大于另一类别的二分类问题中,模型即使始终预测为大类别,也能获得较高的准确率,但实际上这种模型的效果很差。
- 忽视类别间的严重不平衡:在不平衡数据集上,高准确率并不意味着模型有效,可能需要更多的性能度量来辅助评估。
5. 适用性
- 均衡数据集:当正负样本数量差不多时,准确率是一个很好的评估指标。
- 分类不平衡时需结合其他指标:当数据集类别不平衡时,应该考虑同时使用其他指标,如 精确度(Precision)、召回率(Recall)、F1分数、AUC值 等,以全面评估模型的性能。
6. 示例
假设一个二分类模型的混淆矩阵如下:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | 50 (TP) | 10 (FN) |
| 实际为负类 | 5 (FP) | 100 (TN) |
则准确率计算如下:
在这个例子中,模型的准确率是 90.91%,这意味着模型在总体样本中预测正确的比例是约 91%。
7. 总结
准确率是一个直观且简单的评价指标,但在处理类别不平衡数据时需要小心使用。为了更全面地评估模型性能,尤其是在不平衡数据的情境下,通常需要结合其他评价指标,如精确度、召回率、F1分数等。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









