



 本文介绍了PyTorch中的CosineAnnealingLR学习率调度策略,该策略使学习率按照余弦函数衰减,避免了学习率回升。讨论了其在模型优化中的作用,以及如何防止陷入局部最优。同时,对比了SGDR(Stochastic Gradient Descent with Warm Restarts)策略,该策略通过周期性的学习率重启来促进模型跳出不佳的极小值点,提高泛化能力。两种策略各有优势,选择取决于实验需求。
本文介绍了PyTorch中的CosineAnnealingLR学习率调度策略,该策略使学习率按照余弦函数衰减,避免了学习率回升。讨论了其在模型优化中的作用,以及如何防止陷入局部最优。同时,对比了SGDR(Stochastic Gradient Descent with Warm Restarts)策略,该策略通过周期性的学习率重启来促进模型跳出不佳的极小值点,提高泛化能力。两种策略各有优势,选择取决于实验需求。
CosineAnnealingLR
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
作用是让lr随着epoch的变化图类似于cos,公式如下
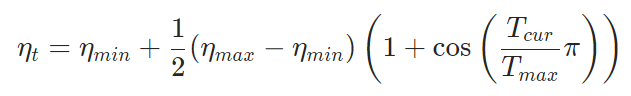
ηt表示新得到的学习率;
ηmin表示学习率最小值(默认为0);
ηmax表示学习率最大值,即初始学习率;
Tcur表示已经记录的epoch数,即当前epoch数减1;
Tmax表示lr从初始预设值降低到最小值的pooch数,即cos周期的1/2(当Tcur=Tmax时,cos为-1,此时ηt=ηmin)。
假设epoch总数为100,Tmax=20,则lr随epoch的变化如下:
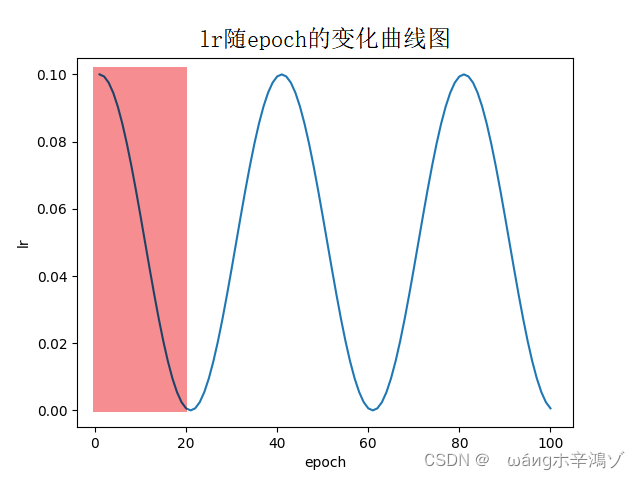
pytorch官方文档中也提到,CosineAnnealingLR学习率更新策略仅实现了 SGDR 的余弦退火部分,而不是重新启动。所以设置Tmax的值为epoch总数能达到这个效果(即仅实现图中红色区域lr衰减部分)。此时公式中的参数也可以理解为第一次(且仅有一次)重启动时的状态参数。
这样做的一个解释是:通过试验发现,若应用的是等间隔的退火策略(如CosineAnnealingLR或Tmult=1的CosineAnnealingWarmRestarts),验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降.所以为了能最终得到一个更好的收敛点,应该逐渐减小学习率,这样到了训练后期,学习率不会再有一个回升的过程,而且一直下降直到训练结束。换句话说,随着学习的进行,模型不断接近极值点,这时如果学习率太大的话会造成模型越过极值点或者发散。(我认为用哪种策略根据具体实验而定吧,因为下文SGDR说明了增大学习率也有好处)
SGDR
【参考】
大致意思是每次重启都重新设置lr再进行逐渐减小。
原因是模型参数空间中存在的大多是鞍点或者表现较差的极小值点,前者会严重影响模型的学习效率,后者会使得模型的最终表现很差。另外,模型应该收敛到参数空间中半径较宽广(broad)区域(吸引盆,basin of attraction)的极值点,这样的点泛化能力较强。研究发现,训练时偶尔增大学习率(不是持续减少),虽然短期内会造成模型性能表现较差,但是最终训练结果在测试集上表现却比传统的逐渐衰减策略更好。因为这样会让模型以更快的(更大的学习率)速度逃离鞍点,从而加速模型收敛。而且,如果模型收敛到了半径较窄的吸引盆区域的极值点区域(泛化能力差),那么突然增大学习率也可以让模型跳出该极值点区域,从到收敛到不易跳出的较宽的(泛化能力强)吸引盆区域的极值点。
说直白点就是防止陷入局部最优。


















 1836
1836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









