



我去面试的时候滔滔不绝,感觉胜利在握,可是面试官忽然到:“什么是 MVCC,MySQL 有了各种锁?为什么还要涉及 MVCC?”
这是个好问题!
MVCC(Multi-Version Concurrency Control)中文叫做多版本并发控制协议,是 MySQL InnoDB 引擎用于控制数据并发访问的协议。
今天我就带你从 MVCC 基本原理说起,并且教你鬼狐一般隔离级别、版本连、Read View 的作用。
为什么需要 MVCC
在 MVCC 出现之前,数据库主要依靠锁机制来解决并发冲突。但锁机制存在明显的瓶颈:
锁的代价:
-
阻塞等待:写锁会阻塞读锁,读锁会阻塞写锁
-
死锁风险:多个事务相互等待对方释放锁
-
并发度低:悲观锁机制限制了系统吞吐量
-- 传统锁机制下的并发问题示例
-- 事务1
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1; -- 获取写锁
-- 事务2(被阻塞)
BEGIN;
SELECT balance FROM accounts WHERE user_id = 1; -- 等待读锁,直到事务1提交
试想一下,如果一个线程准备执行 UPDATE 一行数据,如果这时候阻塞住了所有的 SELECT 语句,那么这个性能你能接受吗?
“余弦:“那肯定不行,所以 MVCC 的核心思想是为每个数据项维护多个版本,读写操作可以并发进行而不相互阻塞?”
聪明,MVCC 的核心思想是为每一行数据维护多个版本(通常是两个),通过某个时间点的“快照”(Snapshot)来读取数据,从而避免加锁带来的性能损耗,实现非阻塞的读操作:
-
非阻塞读:读操作不需要等待写操作完成
-
非阻塞写:写操作不需要等待读操作完成(在合理隔离级别下)。
-
高并发:大幅提升系统吞吐量。
隔离级别
在深入理解 MVCC 之前,我们现在还需要进步一了解和 MVCC 紧密关联的概念,隔离级别。
MySQL 的事务隔离级别有以下四种:
-
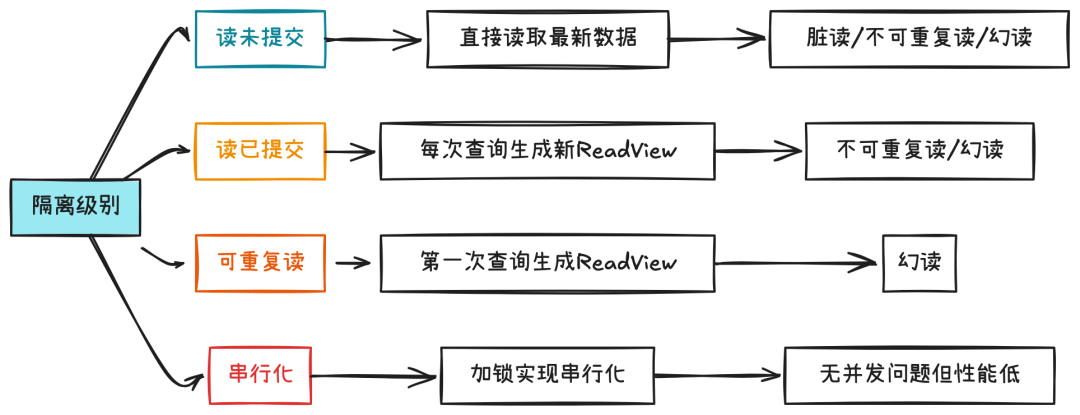
读未提交(Read Uncommitted):
-
是指一个事务可以看到另外一个事务尚未提交的修改。
-
设置:
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -
实现机制:不加任何锁,直接读取最新的数据页,无论其是否已提交。性能最好,但数据一致性最差,生产环境极少使用。
-
-
读已提交(Read Committed,简写 RC):
-
如何避免脏读:因为每次读都取已提交的最新快照,所以不会读到未提交的数据。
-
为何有不可重复读和幻读:因为每次查询的 ReadView 都最新,其他事务的提交会立刻被当前事务看到。
-
是指一个事务只能看到已经提交的事务的修改,如果在事务执行过程中有别的事务提交了,那么事务还是能够看到别的事务最新提交的修改。
-
设置:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;(RC) -
实现机制:基于 MVCC,每次 SELECT 语句都会生成一个独立的、最新的 ReadView。
-
-
可重复读(Repeatable Read,简写 RR):
-
如何避免不可重复读:因为整个事务看到的都是同一个“历史快照”,其他事务的提交对当前事务不可见。
-
InnoDB 如何解决幻读:这是 MySQL InnoDB 的精髓!通过 Next-Key Lock(临键锁) 实现。它结合了记录锁(锁住索引项)和间隙锁(锁住索引项之间的间隙)。当执行范围查询时,InnoDB 会锁住整个范围,防止其他事务在这个范围内插入新数据,从而避免了幻读。
-
是指在这一个事务内部读同一个数据多次,读到的结果都是同一个。这意味着即便在事务执行过程中有别的事务提交,这个事务依旧看不到别的事务提交的修改。这是 MySQL 默认的隔离级别。
-
设置:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;(RR) -
实现机制:基于 MVCC,但一个事务中只有第一次 SELECT 会生成 ReadView,后续所有读操作都复用这个 ReadView。
-- 事务A BEGIN; SELECT * FROM users WHERE age BETWEEN 20 AND 30 FOR UPDATE; -- 会锁住age=20到30这个区间,甚至包括两边的“间隙” -- 此时事务B的插入会被阻塞 INSERT INTO users (name, age) VALUES ('新用户', 25); -- 阻塞,直到事务A提交
-
-
串行化(Serializable)是指事务对数据的读写都是串行化的。
-
设置:
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; -
实现机制:完全摒弃 MVCC,退化为基于锁的并发控制。所有读操作都会加上共享锁,读写操作会相互阻塞。一致性最好,但并发性能最差,像单线程执行一样。
-
“余弦:为什么要隔离?
在并发环境下,如果不进行任何隔离控制,并发事务会引发哪些问题?隔离级别本质上就是为了解决这些问题而存在的。
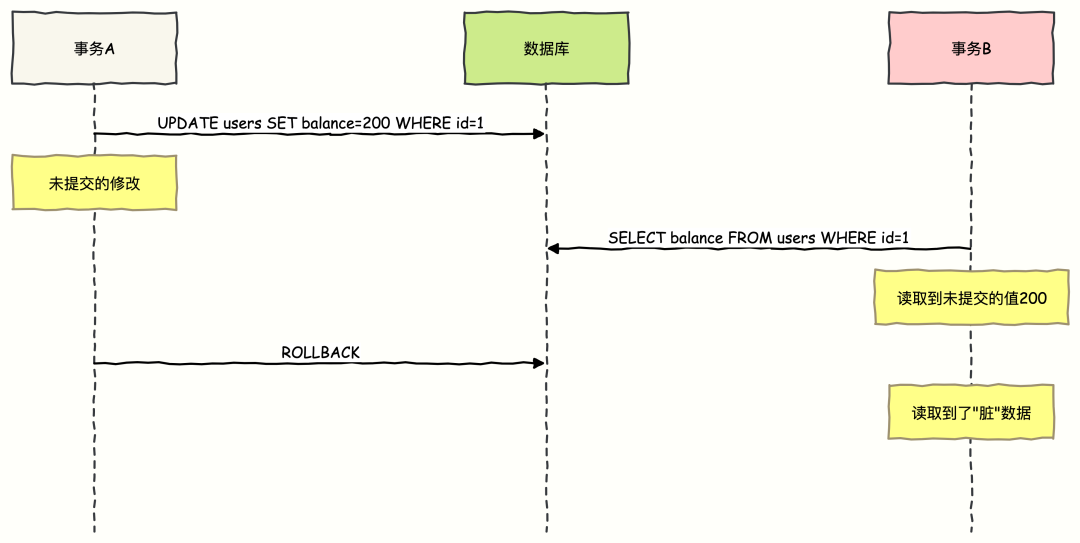
脏读 (Dirty Read)
一个事务读到了另一个未提交事务修改的数据。如果另一个事务中途回滚,那么第一个事务读到的数据就是“脏”的、无效的。
示例:
-
事务 A 将账户余额从 100 元修改为 200 元(但未提交)。
-
此时事务 B 读取余额,得到了 200 元这个结果。
-
事务 A 因某种原因回滚,余额恢复为 100 元。
-
事务 B 之后的操作都是基于错误的“200 元”余额进行的。
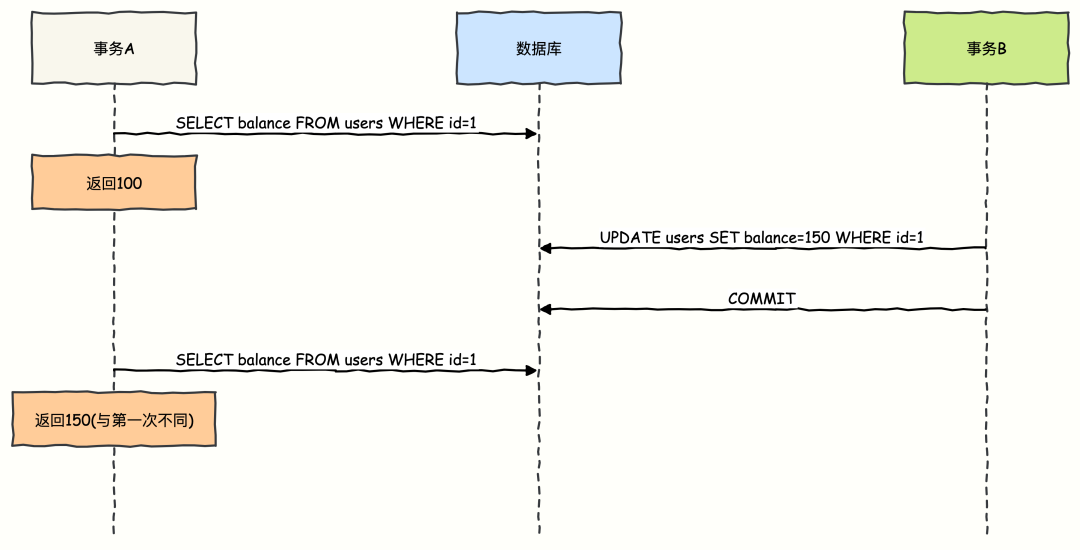
不可重复读 (Non-Repeatable Read)
一个事务内,两次读取同一个数据项,得到了不同的结果。重点在于另一个已提交事务对数据进行了修改(UPDATE)。
示例:
-
事务 A 第一次读取账户余额为 100 元。
-
此时事务 B 提交了修改,将余额更新为 150 元。
-
事务 A 再次读取余额,得到了 150 元。两次读取结果不一致。
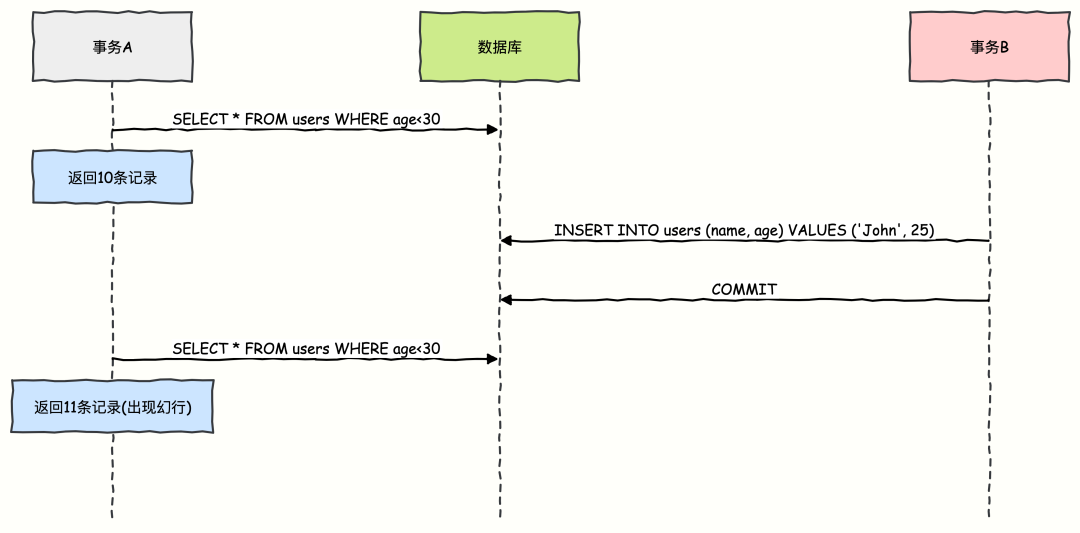
幻读 (Phantom Read)
一个事务内,两次执行同一个查询,返回的结果集行数不同。重点在于另一个已提交事务对数据进行了增删(INSERT/DELETE),像产生了幻觉一样。
示例:
-
事务 A 第一次查询年龄小于 30 岁的员工,返回了 10 条记录。
-
此时事务 B 提交了一个新操作,插入了一名 25 岁的员工记录。
-
事务 A 再次执行相同的查询,返回了 11 条记录。
不可重复读 vs 幻读:
-
不可重复读针对的是某一行数据的值被修改(UPDATE)。
-
幻读针对的是结果集的行数发生变化(INSERT/DELETE)。
SQL 标准下的四种事务隔离级别
为了解决上述问题,SQL 标准定义了四种隔离级别,严格程度从低到高。级别越高,能解决的问题越多,但并发性能通常越低。
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
|---|---|---|---|
| 读未提交 (Read Uncommitted) |
❌ 可能 |
❌ 可能 |
❌ 可能 |
| 读已提交 (Read Committed) |
✅ 避免 |
❌ 可能 |
❌ 可能 |
| 可重复读 (Repeatable Read) |
✅ 避免 |
✅ 避免 |
❌ 可能 |
| 串行化 (Serializable) |
✅ 避免 |
✅ 避免 |
✅ 避免 |
“注意: 在 MySQL 的 InnoDB 引擎中,通过 Next-Key Locking 技术,在可重复读(Repeatable Read) 隔离级别下就已经可以避免绝大部分的幻读现象。
这是 MySQL 对标准隔离级别的增强,也是其默认使用该级别的重要原因。
另外,还有两个概念你需要掌握:
-
快照读:快照读就是在事务开始的时候创建了一个数据的快照,在整个事务过程中都读这个快照;
-
当前读,则是每次都去读最新数据。MySQL 在可重复读这个隔离级别下,查询的执行效果和快照读非常接近。
MVCC 架构
MVCC 的实现依赖于三个核心组件:隐藏字段、Undo Log 版本链和ReadView。
让我们通过架构图来理解它们的关系:
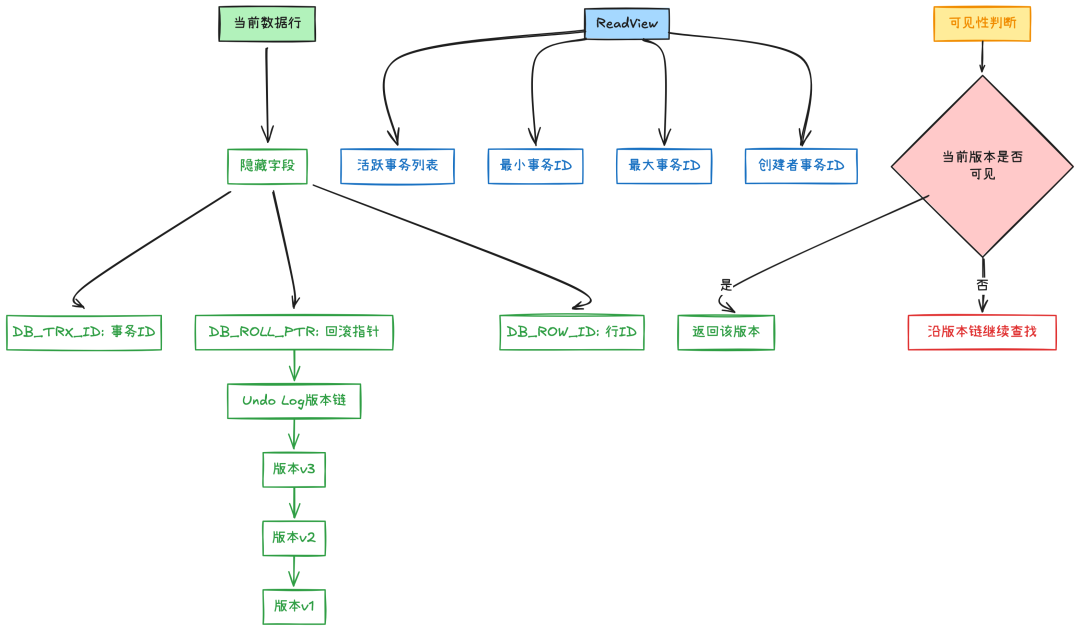
隐藏字段
为了实现 MVCC,InnoDB 引擎给每一行都加了三个额外的字段 trx_id 和 roll_ptr。
-
trx_id:事务 ID,也叫做事务版本号。MVCC 里面的 V 指的就是这个数字。每一个事务在开始的时候就会获得一个 ID,然后这个事务内操作的行的事务 ID,都会被修改为这个事务的 ID。
-
roll_ptr:回滚指针。InnoDB 通过 roll_ptr 把每一行的历史版本串联在一起。
-
row_id:如果你没有设置任何主键,那么这个列就会被当成主键来使用。但是它其实和 MVCC 没太大的关系,所以你不需要关注。
数据行的物理结构:
+------------+-------------+---------------+----------+-----------+
| 字段头信息 | DB_TRX_ID | DB_ROLL_PTR | 列1数据 | 列2数据 |
+------------+-------------+---------------+----------+-----------+
| 5字节 | 6字节 | 7字节 | 变长 | 变长 |
+------------+-------------+---------------+----------+-----------+
Undo Log 版本链
Undo Log 是 MVCC 的基石,它记录了数据变更的历史版本。每次数据修改时,InnoDB 都会在 Undo Log 中保存修改前的数据副本。
Undo Log 的类型:
-
INSERT Undo Log:记录插入操作,事务回滚时直接删除
-
UPDATE Undo Log:记录更新/删除操作,用于回滚和 MVCC。
版本链的构建过程:
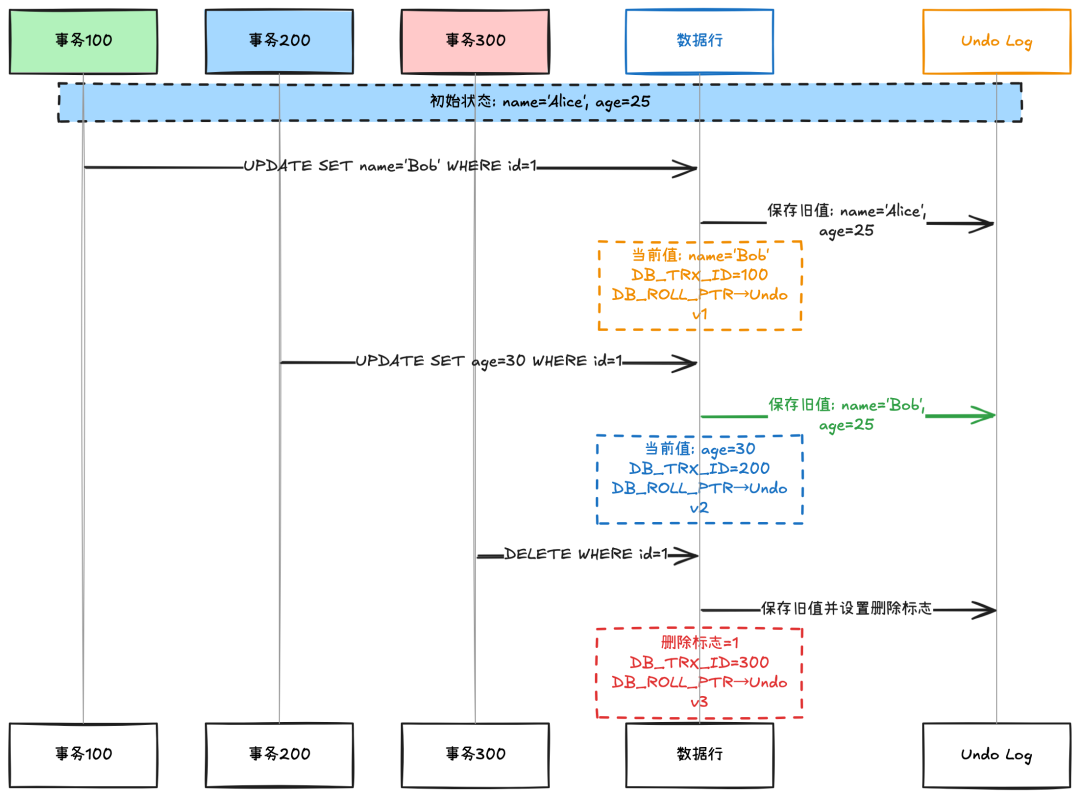
“余弦:现在问题来了,假如这个时候我有一个新的事务 400,那么我该读取 trx_id 为几的数据呢?
这就涉及到了另外一个和 MVCC 紧密相关的概念:Read View。
Read View
Read View 你可以理解成是一种可见性规则。前面你已经知道了 undolog 里面存放着历史版本的数据,当事务内部要读取数据的时候,Read View 就被用来控制这个事务应该读取哪个版本的数据。
class ReadView {
private:
trx_id_t m_low_limit_id; // 高水位:大于等于此值的事务不可见
trx_id_t m_up_limit_id; // 低水位:小于此值的事务可见
trx_id_t m_creator_trx_id; // 创建该ReadView的事务ID
ids_t m_ids; // 活跃事务ID列表
trx_id_t m_low_limit_no; // 用于Purge的事务号
};
Read View 最关键的字段叫做 m_ids,它代表的是当前已经开始,但是还没有结束的事务的 ID,也叫做活跃事务 ID。
Read View 只用于已提交读和可重复读两个隔离级别,它用于这两个隔离级别的不同点就在于什么时候生成 Read View。
-
已提交读:事务每次发起查询的时候,都会重新创建一个新的 Read View。
-
可重复读:事务开始的时候,创建出 Read View。
可见性判断是 MVCC 最精妙的部分,它遵循一套严格的算法规则:
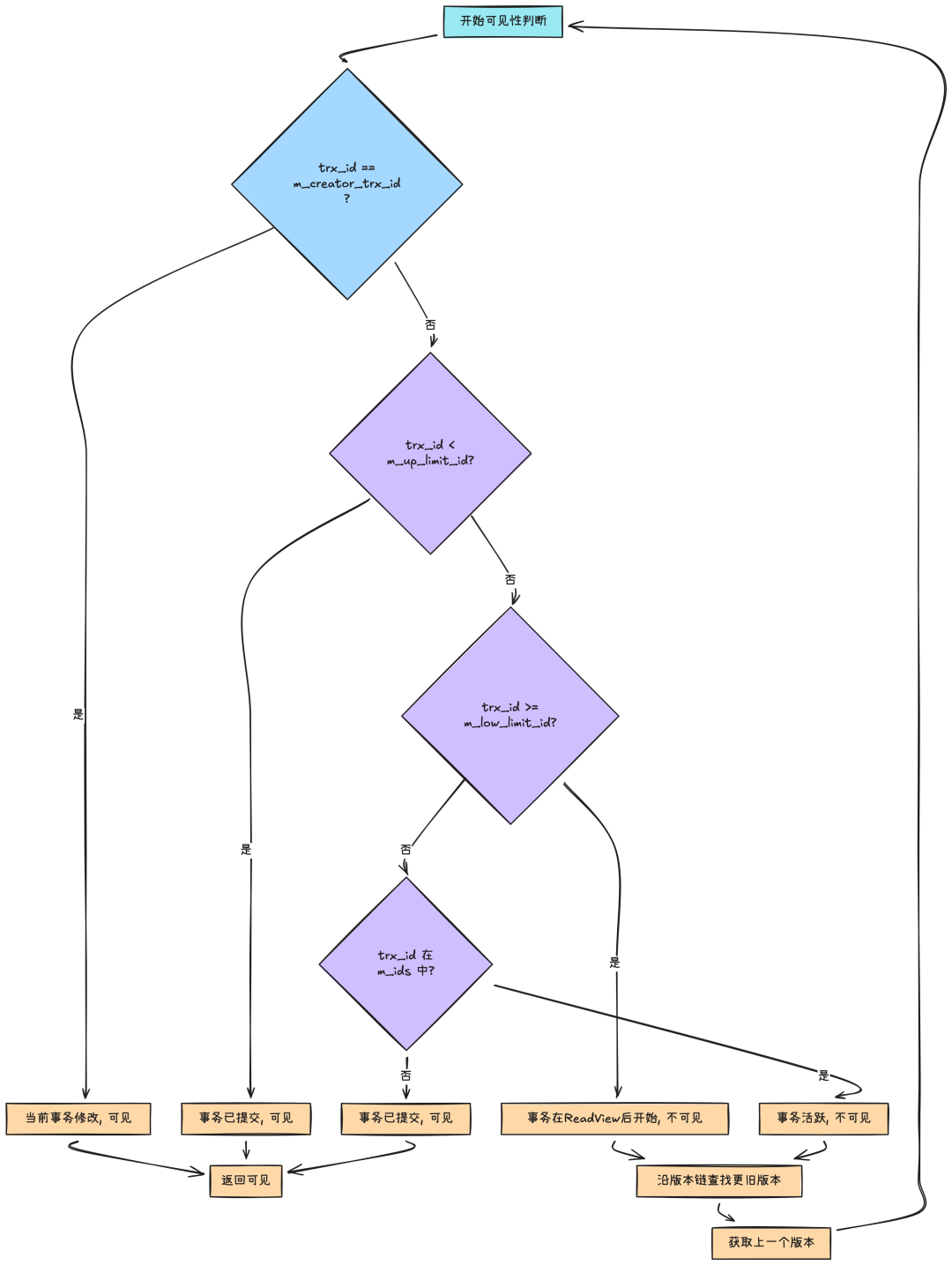
def check_visibility(trx_id, read_view):
# 规则1: 当前事务修改的数据始终可见
if trx_id == read_view.creator_trx_id:
returnTrue
# 规则2: 事务ID小于低水位,说明在ReadView创建前已提交
if trx_id < read_view.up_limit_id:
returnTrue
# 规则3: 事务ID大于等于高水位,在ReadView之后开始
if trx_id >= read_view.low_limit_id:
returnFalse
# 规则4: 检查事务是否活跃
if trx_id in read_view.ids: # 活跃事务列表
returnFalse
else:
returnTrue# 已提交事务
# 对版本链进行判断
def find_visible_version(version_chain, read_view):
for version in version_chain:
if check_visibility(version.trx_id, read_view):
return version
returnNone# 没有可见版本
MVCC 在不同隔离级别下的行为有显著差异,这主要通过 ReadView 的生成时机来控制
读已提交
特点: 每次 SELECT 都会生成新的 ReadView。
-- 事务1
BEGIN;
SELECTnameFROMusersWHEREid = 1; -- 生成ReadView1,看到事务100的版本
-- 事务2修改并提交
UPDATEusersSETname = 'Charlie'WHEREid = 1;
COMMIT;
-- 事务1再次查询
SELECTnameFROMusersWHEREid = 1; -- 生成ReadView2,看到事务200的新版本
可重复读
只在第一次 SELECT 时生成 ReadView,后续查询复用。
-- 事务1
BEGIN;
SELECTnameFROMusersWHEREid = 1; -- 生成ReadView,看到事务100的版本
-- 事务2修改并提交
UPDATEusersSETname = 'Charlie'WHEREid = 1;
COMMIT;
-- 事务1再次查询(可重复读)
SELECTnameFROMusersWHEREid = 1; -- 使用相同的ReadView,仍看到事务100的版本
总结
面试官在问 MVCC 的时候,都是直接问你这几个问题。
-
你是否了解 MVCC?
-
MVCC 是什么?
-
MySQL 的 InnoDB 引擎是怎么控制数据并发访问的?
-
当一个线程在修改数据的时候,另外一个线程还能不能读到数据?
-
为什么要调整为已提交读?主要原因有两个:一是因为业务用不上,二是为了提升性能。
这时候你就要简明扼要地把原理解释清楚。按照基本定义、实现机制、隔离级别的逻辑顺序来回答。
“MVCC 是 MySQL InnoDB 引擎用于控制数据并发访问的协议。
MVCC 主要是借助于版本链来实现的。在 InnoDB 引擎里面,每一行都有两个额外的列,一个是 trx_id,代表的是修改这一行数据的事务 ID。
另外一个是 roll_ptr,代表的是回滚指针。
InnoDB 引擎通过回滚指针,将数据的不同版本串联在一起,也就是版本链。
这些串联起来的历史版本,被放到了 undolog 里面。
当某一个事务发起查询的时候,MVCC 会根据事务的隔离级别来生成不同的 Read View,从而控制事务查询最终得到的结果。
余弦:MySQL 的默认隔离级别是可重复读,实际上互联网的很多应用都调整过这个隔离级别,降低为已提交读。
可重复读比已提交读更加容易引起死锁的问题,比如说我们之前就出现过一个因为临键锁引发的死锁问题。
而且已提交读的性能要比可重复读更好。
所以综合之下,我就推动公司去调整隔离级别,将数据库的默认隔离级别降低为已提交读。
“在调整了事务级别之后,万一需要可重复读的特性了,你怎么办?”
首先你要分析使用可重复读的场景:
-
需要在事务中发起两次同样的查询,并且你希望两次得到的结果是一样的。
-
需要避开幻读,也就是事务开始之后,即便有别的事务插入了数据并且提交了,你也不希望读到这个新数据。
实际上这种场景真的存在吗?大多数可重复读的需求都是代码没写好!!
比如想要两次查询是同样的数据,那我们可以在第一次读取后的数据缓存。
此外,幻读一般不会认为是一个问题。事务提交往往意味着业务已经结束,所以读到一个已经提交的事务的数据,不会损害业务的正确性。

















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









