



今年11月的时候,脉脉发布了一份「以人为本:互联网职场新人流动趋势2025」的报告,其中有一列是校招生最想去的公司排行榜Top 10。
图源脉脉
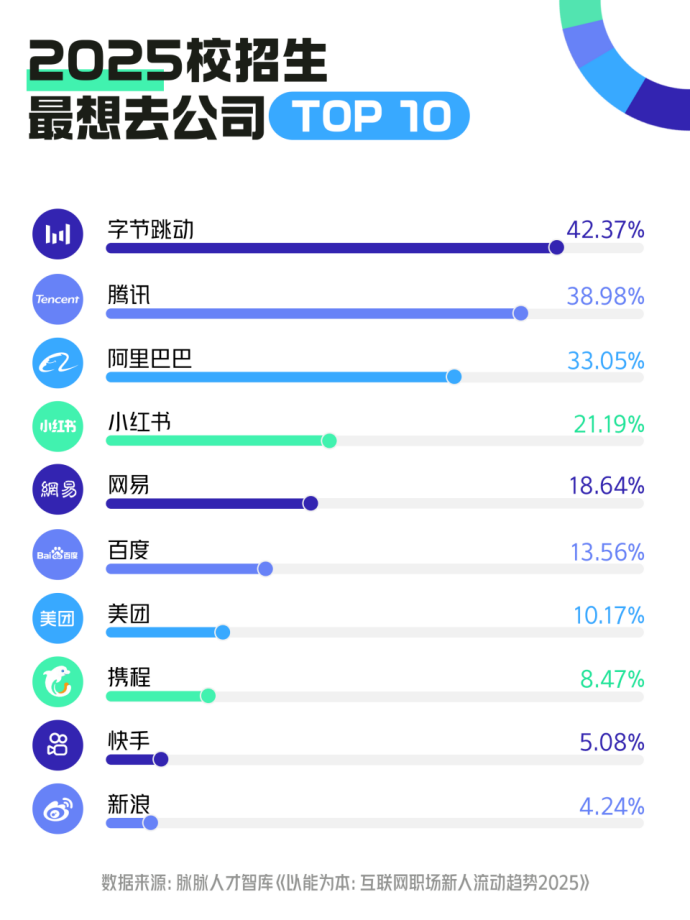
排名依次为:字节跳动、腾讯、阿里巴巴、小红书、网易、百度、美团、携程、快手、新浪,排名分先后。
这个排名可能出乎很多人的意料,比如不是说新人都想去大厂吗?为什么美团还在百度和网易的后面?、前三名无可厚非,是公认的三个一线大厂,但为什么小红书能排在第四名这么靠前的位置上?、新浪为什么能出现在这个榜单上?、京东去哪了?小米去哪了?
前三甲中,"有鹅选鹅"也不灵了,反而是字节排名第一,腾讯排名第二,阿里第三。
有一说一,与腾讯、阿里相比,你在各种社交媒体上能看到字节员工晒"福利"(下午茶、三餐、各种小礼物)的概率绝对大于另外两家公司的员工,尤其是小红书上,这类帖子简直不要太多,这些对于还没出校门的校招生来说确实有很大吸引力。
加之字节一直宣传的"用人看本质,看潜力不看资历"、"培养制度完善"、"新人也能被授权"等,有时候你听得多了看得多了很容易就主观带入了。
咱也不知道脉脉这个榜单是怎么调查的

?感觉有些公司的排名有失偏颇啊。。。。有跟我感觉一样的同学吗?
这里分享一份粉丝的秋招二面面经投稿,这位粉丝投递的正是字节跳动,岗位则是后端开发岗位,主要考察内容包括实习经历、编程语言、计算机网络、数据库、操作系统、情景题以及算法,整体难度中等。
1、自我介绍一下
balabalba
2、介绍一下你在货拉拉的这段实习
这是去年寒假期间找到的一个实习,主要是做页面广告投放的,在实习期间主要跟进了四个版本balabbalba。
看得出来面试官很感兴趣,后来又问了一些广告转化为收益的链路,其实我也不太清楚具体的转化过程,毕竟我只是个实习大头兵,好在提前做了功课,糊弄过去了

。。。
3、介绍一下虚拟技术?
虚拟技术把一个物理实体转换为多个逻辑实体,主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
多进程与多线程:多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。
地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
4、外中断和异常有什么区别?
外中断是指由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
而异常时由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
5、内部碎片与外部碎片有什么区别?
内碎片
分配给某些进程的内存区域中有些部分没用上,常见于固定分配方式。假如内存总量相同即100M:
固定分配:将100M分割成10块,每块10M,一个程序需要45M,那么需要分配5块,第五块只用了5M,剩下的5M就是内部碎片;
分段式分配:按需分配,一个程序需要45M,就给分片45MB,剩下的55M供其它程序使用,不存在内部碎片。
外碎片
内存中某些空闲区因为比较小,而难以利用上,一般出现在内存动态分配方式。
分段式分配:内存总量相同(100M),比如内存分配依次5M、15M、50M、25M。程序运行一段时间之后,5M、15M的程序运行完毕,释放内存,其他程序还在运行。再次分配一个10M的内存供其它程序使用,只能从头开始分片,这样就会存在10M+5M的外部碎片。
6、OSI 的七层模型的主要功能?
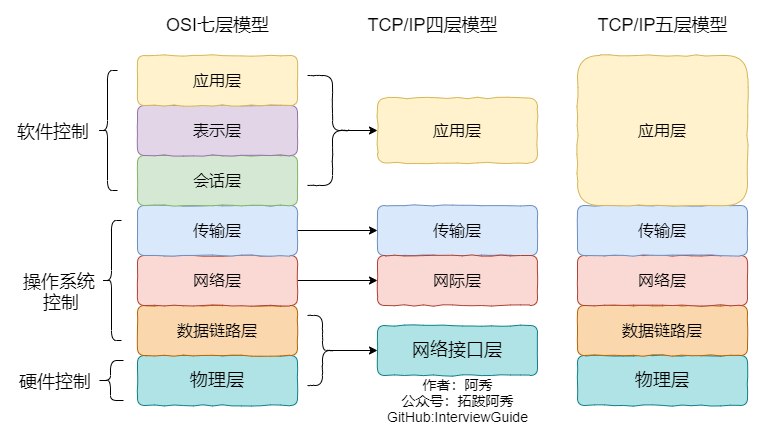
物理层:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
数据链路层:接收来自物理层的位流形式的数据,并封装成帧,传送到上一层
网络层:将网络地址翻译成对应的物理地址,并通过路由选择算法为分组通过通信子网选择最适当的路径。
传输层:在源端与目的端之间提供可靠的透明数据传输。
会话层:负责在网络中的两节点之间建立、维持和终止通信。
表示层:处理用户信息的表示问题,数据的编码,压缩和解压缩,数据的加密和解密。
应用层:为用户的应用进程提供网络通信服务
7、Go协程的的通讯有哪些方式?
共享内存:协程通过共享内存来交换数据,这种方式简单直接,但需要考虑同步和互斥问题,否则会出现数据竞争等问题。 消息传递:协程通过消息队列等方式来传递数据,这种方式可以避免数据竞争等问题,但需要考虑消息的发送和接收顺序等问题。 信号量:协程通过信号量等方式来实现同步和互斥,这种方式需要考虑好信号量的数量和使用顺序,否则会出现死锁等问题。
8、go接口有什么特性,应用场景是怎样的?
接口是一种类型,它是由一组方法签名组成的抽象集合。接口定义了对象应该具有的行为,而不关心对象的具体实现。
特性:实现接口需要提供一组方法签名,这些方法签名必须与接口中定义的方法签名完全相同。如果一个对象实现了某个接口,那么这个对象就必须提供该接口中所有方法的实现 。
场景
它被广泛应用于各种领域,比如网络编程、并发编程、测试等。比如:
-
网络编程中,接口可以用于定义各种网络协议的通信方式。
-
并发编程中,接口可以用于定义各种并发模式的接口。
-
测试中,接口可以用于定义各种测试框架的接口。
9、谈一下你理解的binlog?
binlog是二进制日志文件。他主要用来做主从同步,有statement格式和row格式。
statement记录了执行的SQL语句,Row 格式保存哪条记录被修改。binlog事务提交的时候才写入的,也可以用来做归档。
补充
binlog日志是MySQL数据库的一种日志记录机制,用于记录数据库的修改操作(如插入、更新、删除等),以便在需要时进行数据恢复、数据复制和数据同步等操作。
binlog日志的实现以下功能:
-
数据恢复:binlog日志可以用于回滚到之前的某个时间点,从而恢复数据。
-
数据复制:binlog日志可以用于在主从数据库之间复制数据,从而实现数据的高可用和负载均衡等功能。 MySQL的binlog日志有三种格式,分别是Statement格式、Row格式和Mixed格式。它们之间的区别如下:
-
STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致;
-
ROW:记录行数据最终被修改成什么样了(这种格式的日志,就不能称为逻辑日志了),不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已;
-
MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式;
10、Redis 为什么是单线程的而不采用多线程方案?
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)
11、Redis设置过期时间的两种方案是什么?
Redis中有个设置时间过期的功能,即对存储在 Redis 数据库中的值可以设置一个过期时间。
作为一个缓存数据库, 这是非常实用的,比如一些 token 或者登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间,主要可采用定期删除和惰性删除两种方案。
定期删除
Redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删 除。注意这里是随机抽取的。
为什么要随机呢?你想一想假如 Redis 存了几十万个 key ,每隔100ms就遍历所 有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
惰性删除
定期删除可能会导致很多过期 key 到了时间并没有被删除掉,所以就有了惰性删除。
它是指某个键值过期后,此键值不会马上被删除,而是等到下次被使用的时候,才会被检查到过期,此时才能得到删除,惰性删除的缺点很明显是浪费内存。
除非你的系统去查一下那个 key,才会被Redis给删除掉,这就是所谓的惰性删除!
12、数据库索引采用B+树而不是B树,主要原因是什么?
主要原因:B+树只要遍历叶子节点就可以实现整棵树的遍历,而且在数据库中基于范围的查询是非常频繁的,而B树只能中序遍历所有节点,效率太低。
13、假设你是一名服务端开发人员,现在出现了高并发,你有哪些解决方案?
应用数据与静态资源分离:将静态资源(图片,视频,js,css等)单独保存到专门的静态资源服务器中,在客户端访问的时候从静态资源服务器中返回静态资源,从主服务器中返回应用数据。
客户端缓存:因为效率最高、消耗资源最小的就是纯静态的html页面,所以可以把网站上的页面尽可能用静态的来实现,在页面过期或者有数据更新之后再将页面重新缓存。或者先生成静态页面,然后用ajax异步请求获取动态数据。
反向代理:在访问服务器的时候,服务器通过别的服务器获取资源或结果返回给客户端。
集群和分布式
集群是所有的服务器都有相同的功能,请求哪台都可以,主要起分流作用。
分布式是将不同的业务放到不同的服务器中,处理一个请求可能需要使用到多台服务器,起到加快请求处理的速度。 可以使用服务器集群和分布式架构,使得原本属于一个服务器的计算压力分散到多个服务器上。同时加快请求处理的速度。
14、情景题:找出前500的数
有 20 个数组,每个数组有 500 个元素,并且有序排列。如何在这 20*500 个数中找出前 500 的数?
解答思路
对于 TopK 问题,最常用的方法是使用堆排序。对本题而言,假设数组降序排列,可以采用以下方法:
首先建立大顶堆,堆的大小为数组的个数,即为 20,把每个数组最大的值存到堆中。
接着删除堆顶元素,保存到另一个大小为 500 的数组中,然后向大顶堆插入删除的元素所在数组的下一个元素。
重复上面的步骤,直到删除完第 500 个元素,也即找出了最大的前 500 个数。
为了在堆中取出一个数据后,能知道它是从哪个数组中取出的,从而可以从这个数组中取下一个值,可以把数组的指针存放到堆中,对这个指针提供比较大小的方法。
算法参考
import lombok.Data;
import java.util.Arrays;
import java.util.PriorityQueue;
publicclass DataWithSource implements Comparable<DataWithSource> {
/**
* 数值
*/
privateint value;
/**
* 记录数值来源的数组
*/
privateint source;
/**
* 记录数值在数组中的索引
*/
privateint index;
public DataWithSource(int value, int source, int index) {
this.value = value;
this.source = source;
this.index = index;
}
/**
*
* 由于 PriorityQueue 使用小顶堆来实现,这里通过修改
* 两个整数的比较逻辑来让 PriorityQueue 变成大顶堆
*/
@Override
public int compareTo(DataWithSource o) {
return Integer.compare(o.getValue(), this.value);
}
}
class Test {
publicstaticint[] getTop(int[][] data) {
int rowSize = data.length;
int columnSize = data[0].length;
// 创建一个columnSize大小的数组,存放结果
int[] result = newint[columnSize];
PriorityQueue<DataWithSource> maxHeap = new PriorityQueue<>();
for (int i = 0; i < rowSize; ++i) {
// 将每个数组的最大一个元素放入堆中
DataWithSource d = new DataWithSource(data[i][0], i, 0);
maxHeap.add(d);
}
int num = 0;
while (num < columnSize) {
// 删除堆顶元素
DataWithSource d = maxHeap.poll();
result[num++] = d.getValue();
if (num >= columnSize) {
break;
}
d.setValue(data[d.getSource()][d.getIndex() + 1]);
d.setIndex(d.getIndex() + 1);
maxHeap.add(d);
}
return result;
}
public static void main(String[] args) {
int[][] data = {
{29, 17, 14, 2, 1},
{19, 17, 16, 15, 6},
{30, 25, 20, 14, 5},
};
int[] top = getTop(data);
System.out.println(Arrays.toString(top)); // [30, 29, 25, 20, 19]
}
}
15、算法题
盛最多水的容器:力扣原题,接雨水的变形题 https://leetcode.cn/problems/container-with-most-water/

















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









