




大数据项目的开发流程是一个系统化、迭代式的过程,它融合了传统软件工程的思想和大数据领域的独特性。一个典型的流程可以概括为以下几个核心阶段,我还会用一个简单的例子来贯穿说明。
大数据项目开发核心流程
整个流程可以可视化为一个循环的、不断迭代优化的闭环,如下图所示:
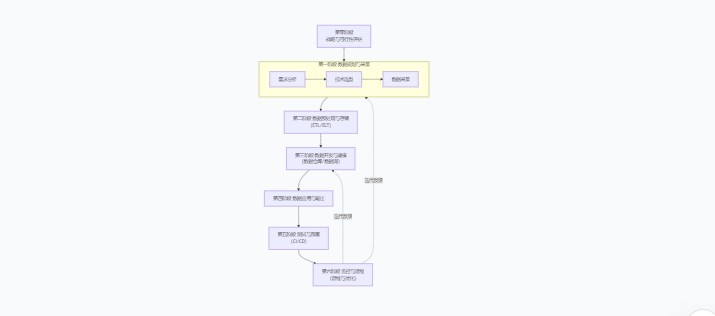
第零阶段:战略与可行性评估(Pre-Project)
在正式启动前,必须明确项目的商业价值,避免为了用大数据而用大数据。
- 核心问题:我们要解决什么业务问题?预期的商业价值是什么?(例如:提升销售额、降低运营成本、预警风险)
- 数据可行性:解决这个问题需要哪些数据?内部是否有这些数据?外部能否获取?数据质量如何?
- 技术资源可行性:现有技术团队能否胜任?是否需要引入新工具或招聘新人才?预算是否充足?
- 产出:项目可行性分析报告、初步的商业目标和成功指标(OKR/KPI)。
第一阶段:数据规划与采集 (Data Planning & Acquisition)
这个阶段关注“数据从哪里来”和“怎么来”。
-
需求分析与技术选型:
- 数据源识别:确定需要的数据源,例如数据库、日志文件、第三方API、物联网传感器等。
- 技术选型:根据数据量、速率、类型(批处理或流处理)选择技术栈。
- 批处理:Sqoop, DataX, 传统ETL工具(如Informatica)
- 流处理:Kafka, Flume, Pulsar
- 云服务:AWS Kinesis, Azure Event Hubs, Google Pub/Sub
-
数据采集:
- 将数据从各种源系统采集到集中的数据存储中(如HDFS、对象存储S3/OSS、Kafka消息队列)。
- 原则:尽量保留原始数据,避免在采集阶段进行大量清洗和转换,因为原始数据可能包含未来才发现的价值。
第二阶段:数据预处理与存储 (Data Processing & Storage)
这个阶段关注“数据如何清洗和存放”,也称为ETL/ELT。
- 数据清洗与转换(ETL/ELT):
- 使用Spark、Flink、Hive、Tez、Presto等计算框架对原始数据进行处理。
- 常见任务:清洗脏数据(缺失值、异常值)、格式标准化、数据脱敏、关联集成、构建宽表。
- 数据存储:
- 将处理后的数据存储到适合的数据平台上,如:
- 数据仓库:Amazon Redshift, Google BigQuery, Snowflake, Apache Hive(适用于结构化数据,支持SQL分析)
- 数据湖:Apache HDFS, AWS S3, Azure Data Lake Storage(ADLS)(存储各种原始格式的数据)
- 湖仓一体:Delta Lake, Apache Hudi, Apache Iceberg(结合数据湖和数据仓库的优势)
- 将处理后的数据存储到适合的数据平台上,如:
第三阶段:数据开发与建模 (Data Development & Modeling)
这个阶段关注“如何组织数据以方便使用”,是数据价值化的核心。
- 数据建模:根据分析需求,构建数据模型(如维度建模),形成易于理解和查询的表结构。
- 常见模型:星型模型、雪花模型。
- 分层设计:通常会将数据仓库分为多层(如ODS原始数据层、DWD明细数据层、DWS汇总数据层、ADS应用数据层),每层有不同作用,简化计算,减少重复开发。
- 工具:Hive SQL, Spark SQL, Flink SQL, dbt (data build tool)。
第四阶段:数据应用与输出 (Data Application & Output)
这个阶段关注“数据如何产生价值”,将数据交付给最终用户。
- 应用形式:
- 数据可视化与BI报表:使用Tableau、Power BI、Superset等工具为业务人员提供自助分析报表和仪表盘。
- 数据API服务:将数据以API(如RESTful API)的形式提供给其他应用程序调用。
- 机器学习/AI应用:将处理好的数据用于训练机器学习模型,进行预测、推荐、分类等(如用户画像、精准营销、风险控制)。
- 即席查询:允许数据分析师直接编写SQL进行探索性分析。
第五阶段:测试与部署 (Testing & Deployment)
大数据项目同样需要严格的测试和自动化部署。
- 测试:
- 数据质量测试:验证数据的准确性、完整性、一致性、时效性。
- 单元测试:测试每个数据处理脚本或SQL的逻辑正确性。
- 性能测试:测试数据处理任务在高负载下的表现。
- 部署与CI/CD:
- 使用Jenkins、GitLab CI/CD、Airflow、DolphinScheduler等工具实现持续集成和持续部署,自动化调度和运行数据流水线(Data Pipeline)。
第六阶段:运维、监控与优化 (Ops, Monitoring & Optimization)
项目上线后进入长期运维阶段。
- 监控:监控数据流水线的健康度、任务成功率、资源利用率(CPU、内存、磁盘IO)、数据延迟等。
- 运维:处理日常告警、故障排除、保证数据按时产出。
- 优化:持续进行性能调优(如优化SQL、调整集群参数)、成本优化(清理无用数据、选择更经济的存储类型)。
- 迭代:根据业务反馈和新需求,回到第一阶段,开始新的迭代循环。
一个简单的例子:电商用户行为分析
- 目标:分析用户购买行为,提升销售额。
- 数据采集:用Flume收集服务器日志(点击、浏览),用Sqoop从MySQL业务数据库同步订单数据到Kafka和HDFS。
- 数据处理:用Spark Streaming清洗Kafka中的实时日志,用Hive SQL批处理订单数据,进行关联和汇总。
- 数据存储与建模:在Hive中构建分层数据仓库,形成“用户宽表”和“商品销售聚合表”。
- 数据应用:用Tableau连接Hive,制作“每日销售仪表盘”和“用户转化率漏斗图”。
- 运维优化:监控Airflow任务流,发现某个Hive查询很慢,对其进行SQL优化和索引添加。
总结特点
- 迭代性:不是一个一次性项目,而是不断演进和迭代的。
- 数据驱动:一切围绕数据的价值展开。
- 跨职能协作:需要数据工程师、数据科学家、数据分析师、业务人员、运维工程师紧密合作。
- 技术复杂性:技术栈丰富,需要根据场景灵活选型。
这个流程是一个通用框架,在实际项目中会根据具体规模和需求进行裁剪和调整。

















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









