




DataX中识别Hive分隔符^A(001)的配置方法
在DataX中处理Hive使用的^A(ASCII码001)分隔符,需要在HDFS Reader中正确配置字段分隔符。
基本配置方法
1. 使用Unicode转义序列
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/your/hive/path",
"defaultFS": "hdfs://namenode:port",
"column": [
{"index": 0, "type": "string"},
{"index": 1, "type": "long"},
{"index": 2, "type": "date"}
],
"fileType": "text",
"encoding": "UTF-8",
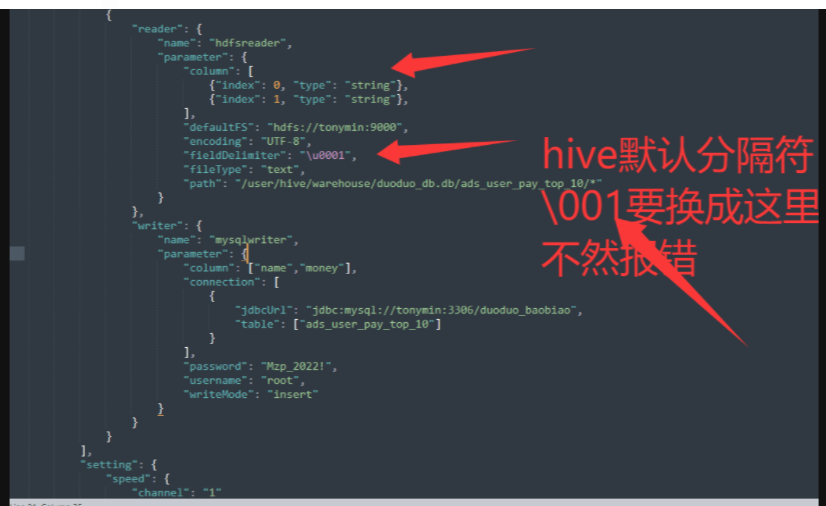
"fieldDelimiter": "\\u0001",
"nullFormat": "\\N"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
// MySQL写入配置
}
}
}
]
}
}
2. 使用八进制转义序列
{
"reader": {
"name": "hdfsreader",
"parameter": {
// 其他配置...
"fieldDelimiter": "\\001",
// 其他配置...
}
}
}
完整配置示例
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/test_table/*",
"defaultFS": "hdfs://hadoop-cluster:8020",
"column": [
{"index": 0, "type": "bigint", "value": "id"},
{"index": 1, "type": "string", "value": "name"},
{"index": 2, "type": "string", "value": "email"},
{"index": 3, "type": "date", "value": "create_time", "format": "yyyy-MM-dd"}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\\u0001",
"nullFormat": "\\N",
"compress": "none",
"hadoopConfig": {
"dfs.nameservices": "hadoop-cluster",
"dfs.ha.namenodes.hadoop-cluster": "nn1,nn2",
"dfs.namenode.rpc-address.hadoop-cluster.nn1": "namenode1:8020",
"dfs.namenode.rpc-address.hadoop-cluster.nn2": "namenode2:8020",
"dfs.client.failover.proxy.provider.hadoop-cluster": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "hive_user",
"password": "your_password",
"column": ["id", "name", "email", "create_time"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://mysql-server:3306/data_warehouse?useUnicode=true&characterEncoding=utf8&useSSL=false",
"table": ["test_table"]
}
],
"batchSize": 1024,
"preSql": [
"DELETE FROM test_table WHERE dt = '${bizdate}'"
]
}
}
}
],
"setting": {
"speed": {
"channel": 5,
"byte": 10485760
},
"errorLimit": {
"record": 1000,
"percentage": 0.1
}
}
}
}
处理Hive中其他特殊分隔符
Hive中可能使用的其他分隔符配置:
| 分隔符类型 | ASCII码 | DataX配置值 |
|---|---|---|
| ^A (SOH) | 001 | \\u0001 或 \\001 |
| ^B (STX) | 002 | \\u0002 或 \\002 |
| ^C (ETX) | 003 | \\u0003 或 \\003 |
| 制表符 | 009 | \\t 或 \\u0009 |
| 换行符 | 010 | \\n 或 \\u000a |
注意事项
- 转义字符格式:必须使用双反斜杠
\\进行转义,而不是单反斜杠 - 列映射:确保HDFS文件中的列顺序与DataX配置中的
column索引顺序一致 - 空值处理:Hive中常用
\N表示空值,需配置"nullFormat": "\\N" - 复杂数据类型:如果Hive表包含数组、映射等复杂类型,需要先将其转换为字符串或在DataX中进行特殊处理
- 分区处理:如果Hive表有分区,确保路径指向具体分区或正确处理分区字段
调试技巧
如果遇到分隔符识别问题,可以:
- 先用一个小的样本文件测试
- 检查实际文件中的分隔符:
hadoop fs -cat /path/to/hive/table/part-00000 | head -n 1 | hexdump -C - 调整
fieldDelimiter值,尝试不同的转义格式
通过正确配置分隔符转义序列,DataX可以顺利处理Hive中使用特殊分隔符存储的数据。
注意点:

















 5327
5327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









