




目录
随着全球数字化进程的加速,非结构化数据量呈现爆炸式增长,从纸质文档到电子文件的转变不仅意味着信息存储方式的革新,更标志着旧数据被赋予了新的生命力。文档智能技术的发展使得大量以传统形式保存的信息资源能够“活化”再利用,这些技术将图像、手写笔记等非结构化数据转化为计算机可处理和理解的结构化格式,从而极大地拓展了数据的应用场景。得益于深度学习算法的进步,文档解析技术在文档数字化、票据自动化处理、笔迹录入等多个领域取得了显著成就。例如,在金融行业,智能文档处理系统可以快速准确地识别并提取票据中的关键信息,大大提高了工作效率;在历史文献保护方面,先进的文档分析工具能够帮助学者们解读古老文本,为文化传承贡献力量。文档智能技术正以其高效便捷的特点,成为推动各行业数字化转型的重要力量。
文档解析的主要研究问题
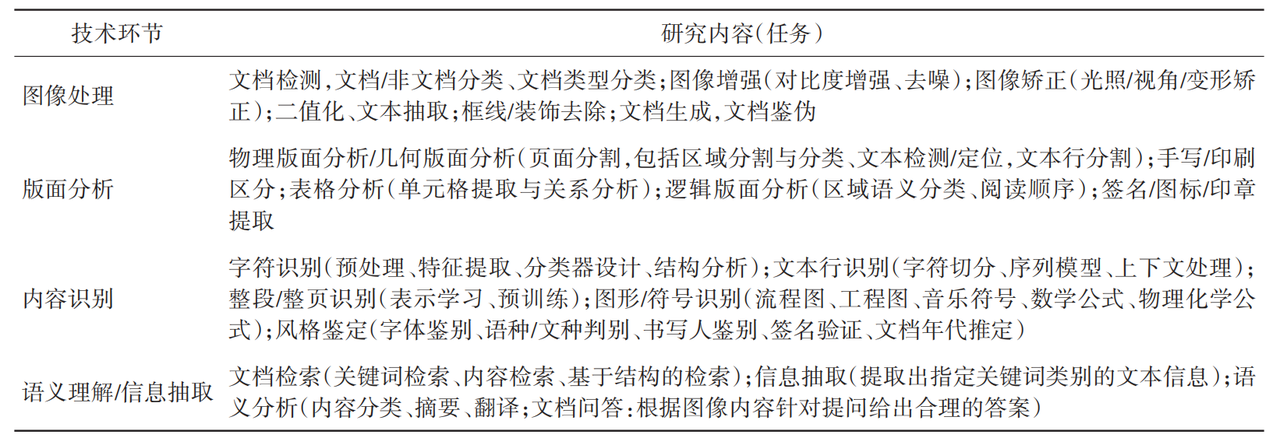
文档解析作为连接非结构化数据与计算机理解的关键桥梁,主要研究的技术问题涵盖了图像预处理、版面分析、内容识别(文本识别、图形符号识别)和语义分析/信息抽取。每一个环节都是实现从图像到结构化数据转换不可或缺的一部分。研究任务如表格所示[1]:
文档解析技术的演进
概念阶段(1920年代):OCR概念萌芽时期,德国科学家Tausheck提出首个基于光学字符识别的专利,成为现代OCR技术的雏形。
第一阶段(1950-1970):在计算机模式识别和人工智能领域刚刚起步时,文档解析集中在探索字符识别的方法。此阶段形成了统计模式识别理论框架,并开发了多种单字识别技术,包括印刷字符和手写字符。商用OCR机器开始出现,推动了早期文字识别的应用实践[2]。
第二阶段(1980-2000):进入80年代后,研究重点转向了包含更多元素的文档,能够处理简单结构文档。手写字符识别成为热点,提出了许多创新算法,如非线性归一化、方向直方图特征等[3]。同时,词识别和字符串识别也开始受到重视,HMM逐渐成为西方语言字符串识别的主流工具。
第三阶段(2001-2013):随着互联网和技术的进步,研究对象扩展到了更复杂的版面结构与文档形式。研究者们尝试解决诸如文本行识别、自由格式表格和手写文档分割等问题,为后来的大规模应用奠定了基础[4][5]。
第四阶段(2014-至今):自2014年起,深度学习方法广泛应用于文档解析领域,带来了前所未有的变革。无论是字符识别、版面分析还是语义信息抽取,性能都得到了质的飞跃。端到端学习方式减少了人工干预,而自监督学习和预训练模型则进一步增强了系统的泛化能力[6]。
前沿技术研究进展
文档图像预处理:当前,文档图像预处理的研究主要集中在形变矫正和图像增强领域。基于深度学习的文档图像形变矫正已成为主流方法,通过预测密集形变场或稀疏控制点进行矫正,以适应实际应用中的复杂场景[7][8]。图像形变矫正技术的综述,详见
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 528
528



 到【灌水乐园】发言
到【灌水乐园】发言







