




 本文对比了人类反馈强化学习(RLHF)与来自人工智能反馈的强化学习(RLAIF)在总结任务中的表现。研究发现,RLAIF能达到与RLHF相当的性能,是RLHF可行的替代方案。此外,还研究了生成人工智能标签的技术及相关缩放实验。
本文对比了人类反馈强化学习(RLHF)与来自人工智能反馈的强化学习(RLAIF)在总结任务中的表现。研究发现,RLAIF能达到与RLHF相当的性能,是RLHF可行的替代方案。此外,还研究了生成人工智能标签的技术及相关缩放实验。
一、简要介绍

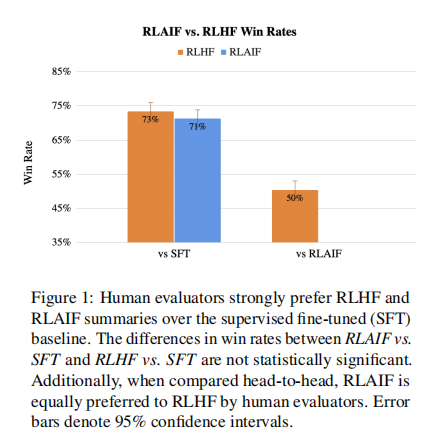
人类反馈强化学习(RLHF)可以有效地将大型语言模型(LLM)与人类偏好对齐,但收集高质量的人类偏好标签是一个关键瓶颈。论文进行了一场RLHF与来自人工智能反馈的RL的比较(RLAIF) -一种由现成的LLM代替人类标记偏好的技术,论文发现它们能带来相似的改善。在总结任务中,人类评估者在70%的情况下更喜欢来自RLAIF和RLHF的生成,而不是基线监督微调模型。此外,当被要求对RLAIF和RLHF总结进行评分时,人们倾向于两者评分相等。这些结果表明,RLAIF可以产生人类水平的性能,为RLHF的可扩展性限制提供了一个潜在的解决方案。
二、研究背景
从人类反馈中强化学习(RLHF)是一种使语言模型适应人类偏好的有效技术,并被认为是现代会话语言模型如ChatGPT和Bard成功的关键驱动力之一。通过强化学习(RL)的训练,语言模型可以在复杂的序列级目标上进行优化,这些目标不易用传统的监督微调进行区分。
对高质量的人类标签的需求是扩大RLHF规模的一个障碍,一个很自然的问题是,人工生成的标签能否达到类似的结果。一些研究表明,大型语言模型(LLM)表现出与人类判断的高度一致——甚至在某些任务上优于人类。Bai等人(2022b)是第一个探索使用人工智能偏好来训练一种用于RL微调的反馈模型——一种被称为“来自人工智能反馈的强化学习”(RLAIF)的技术。虽然他们表明,将人类和人工智能偏好的混合结合“Constitutional AI”自我视觉技术优于监督的精细基线,但他们的工作并没有直接比较人类和人工智能反馈的效率,RLAIF能否成为RLHF合适的替代品仍是一个保留问题。
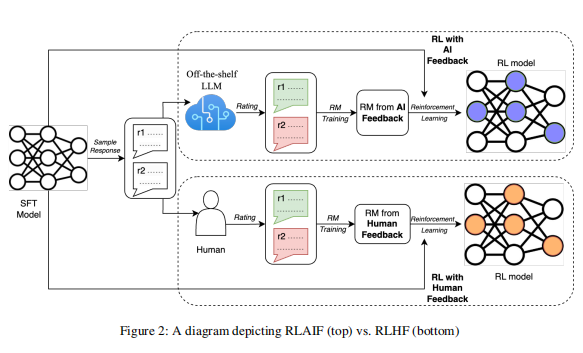
在这项工作中,论文直接比较了RLAIF和RLHF的总结任务。给定一个文本和两个候选响应,论文使用现成的LLM分配一个偏好标签。然后,论文训练了一个关于LLM偏好的反馈模型(RM)。最后,论文使用强化学习来微调一个策略模型,使用RM来提供反馈。
论文的结果表明,RLAIF达到了与RLHF相当的性能,以两种方式测量。首先,论文观察到,RLAIF和RLHF策略分别有71%和73%的时间比监督微调(SFT)基线更受到人类的青睐,但这两种获胜率在统计学上没有显著差异。第二,当被要求直接比较来自RLAIF和RLHF的生成时,人类对两种方案同样喜欢(即50%的win rate)。这些结果表明,RLAIF是RLHF可行的替代方案,不依赖人类注释,提供吸引人的缩放属性。
此外,论文还研究了最大限度地将人工智能产生的偏好与人类偏好对齐的技术。论文发现,用详细的提示驱动论文的LLM和使用思维链推理可以改善对齐。令人惊讶的是,论文观察到少量的情境学习和自洽性——在这个过程中,论文对多个思维链的基本原理进行抽样并对最终偏好进行平均——都没有提高准确性,甚至降低准确性。最后,论文进行了缩放实验,以量化LLM标签器的大小和在训练中使用的偏好示例的数量与与人类偏好对齐之间的权衡。
论文的主要贡献如下:
1.论文证明了RLAIF在总结任务上取得了与RLHF相当的性能
2.论文比较了各种生成人工智能标签的技术,并为RLAIF从业者确定最佳设置
三、准备工作(Preliminaries)
论文首先回顾了现有工作引入的RLHF pipeline,包括3个阶段:监督微调、反馈模型训练和基于强化学习的微调。
监督微调(Supervised Fine-tuning)

反馈建模(Reward Modeling)

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









