





前言
Python程序的核心逻辑离不开“输入→处理→输出”的“黑箱模型”——输入是程序的“养料”,输出是程序的“成果”。
不管是新手入门的键盘交互,还是工作中的文件处理、数据序列化,掌握输入输出(I/O)都是Python开发的必备技能。
本文从基础到高级,结合图解和实战代码,覆盖Python I/O的核心场景(基础交互、文件操作、JSON序列化、高级优化),帮你一站式搞定所有I/O需求,避开常见陷阱!
一、Python I/O核心逻辑:黑箱模型图解
Python的输入输出本质是“数据流动的通道”,所有I/O操作都围绕“数据从外部进入程序,或从程序输出到外部”展开,用流程图可直观展示:
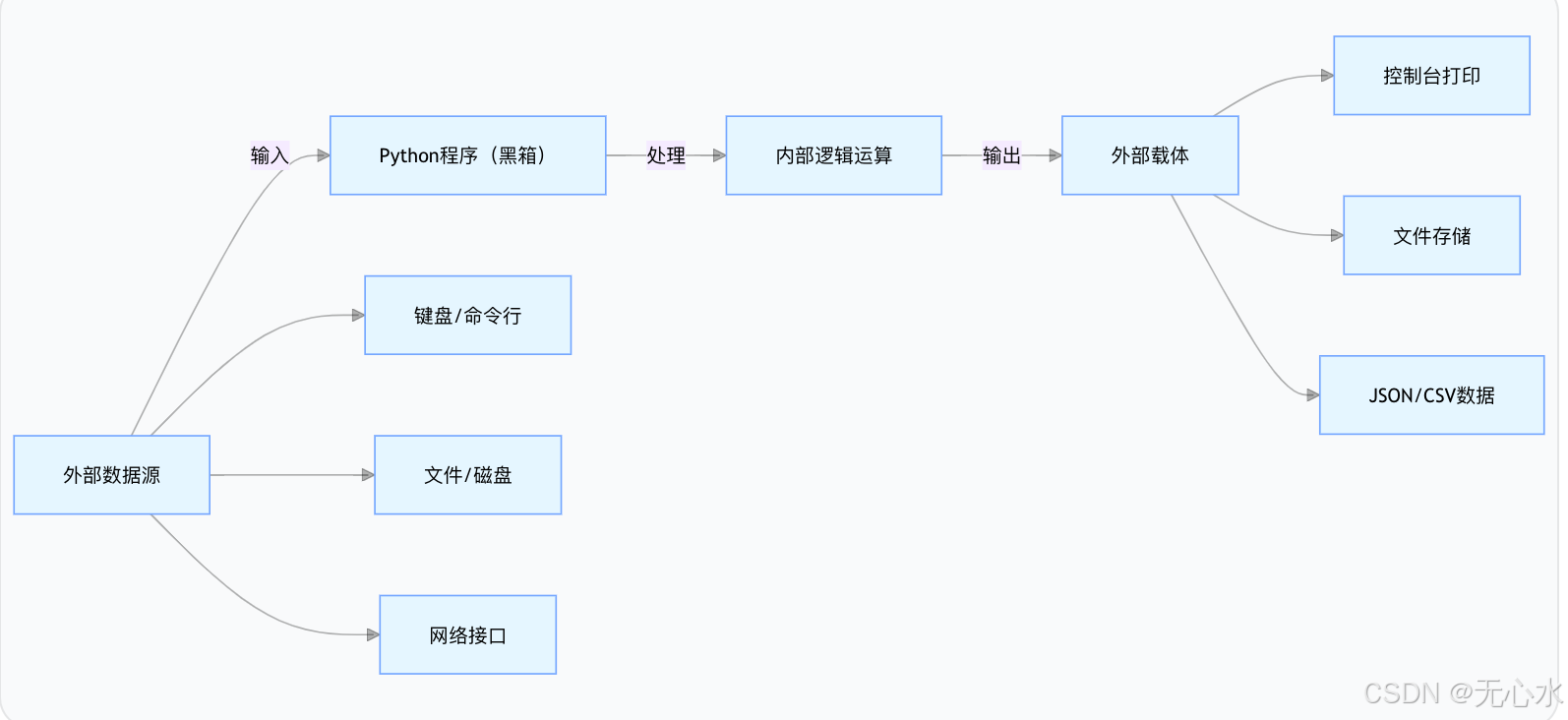
核心说明:外部数据源(键盘、文件等)通过输入通道将数据传入程序,经内部处理后,通过输出通道写入外部载体(控制台、文件等),这就是Python I/O的底层逻辑。
二、基础输入输出:搞定用户交互
1. 输入:input()函数的用法与避坑
input()是Python获取键盘输入的核心函数,默认返回字符串类型,这是新手最容易踩坑的点!
关键代码(含类型转换)
# 基础用法:获取字符串输入
name = input("请输入姓名:")
print(f"你好,{name}!") # 输出:你好,张三!
# 避坑:数字输入必须显式转换
age = input("请输入年龄:")
print(type(age)) # <class 'str'>(即使输入数字,也是字符串)
age = int(input("请输入年龄:")) # 转为整数
print(f"3年后你{age+3}岁") # 正常运算:3年后你25岁
# 进阶:一次输入多个值
data = input("请输入姓名和城市(空格分隔):").split()
name, city = data[0], data[1]
print(f"姓名:{name},城市:{city}")
常见陷阱
- ❌ 直接对input()结果做算术运算(需用
int()/float()转换); - ❌ 输入含空格时未处理(用
split()拆分或strip()去空格)。
2. 输出:print()的实用技巧
print()不止是“打印”,还支持格式化、自定义分隔符/结束符等高级用法:
# 技巧1:一次打印多个值(默认空格分隔)
name = "李四"
score = 92.5
print("姓名:", name, "成绩:", score)
# 技巧2:自定义分隔符和结束符
print("2024", "10", "01", sep="-") # 输出:2024-10-01
print("进度10%", end="→")
print("进度50%", end="→")
print("进度100%") # 输出:进度10%→进度50%→进度100%
# 技巧3:格式化输出(推荐f-string)
print(f"姓名:{name},成绩:{score:.1f}分") # 格式化数字:92.5分
print("姓名:{},成绩:{:.2f}分".format(name, score)) # 兼容旧版本
三、文件I/O:从读写到大文件优化
文件操作是工作中最常用的I/O场景,核心是open()函数和with语句(自动关闭文件,避免资源泄露)。
1. 文件操作核心流程(mermaid图解)
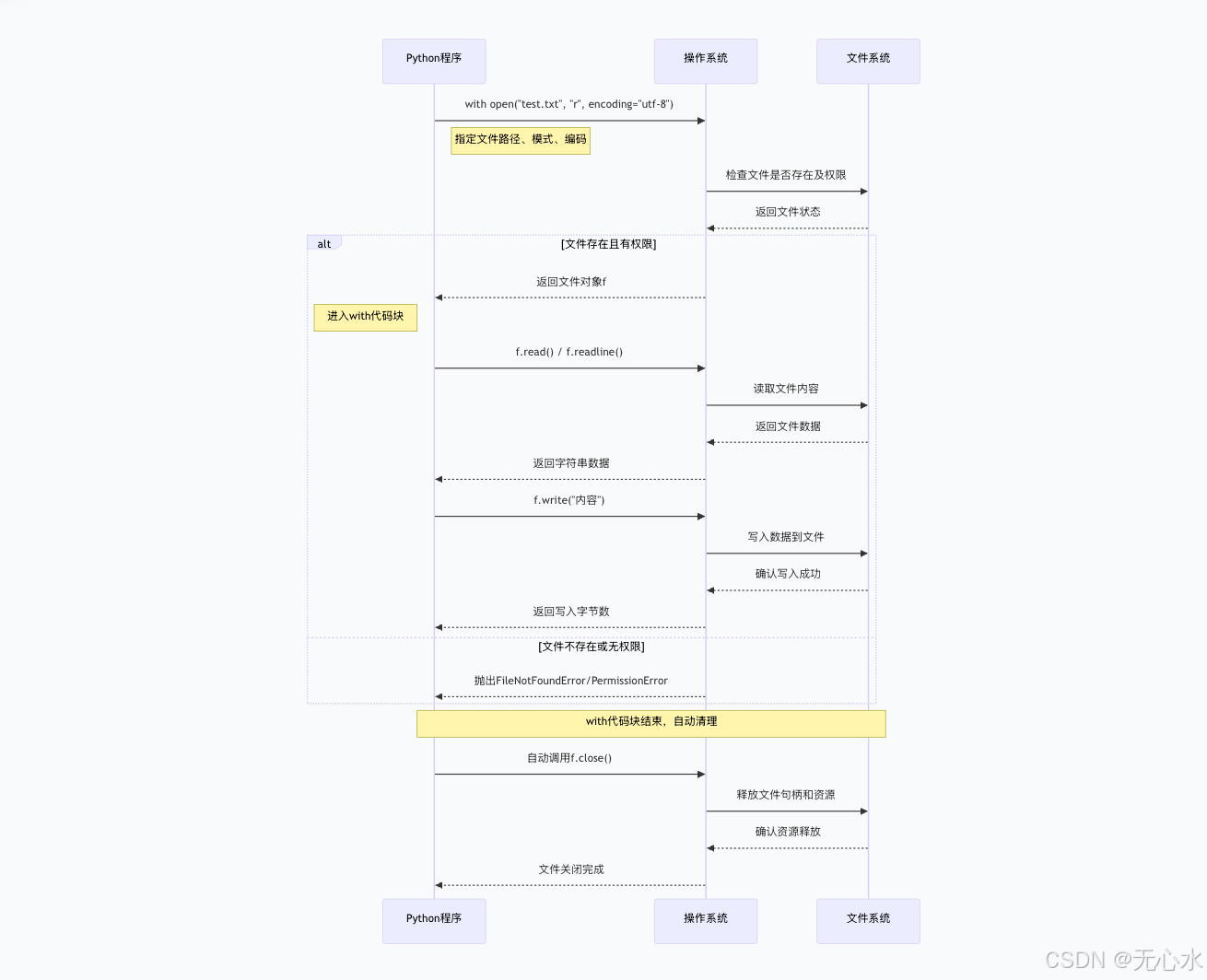
2. 关键代码(文件读写)
(1)基础文件操作(with语句必用)
# 读取文件(小文件)
with open("in.txt", "r", encoding="utf-8") as fin:
content = fin.read() # 读取全部内容
print("文件内容:", content)
# 写入文件(覆盖/追加)
with open("out.txt", "w", encoding="utf-8") as fout: # "w"覆盖,"a"追加
fout.write("姓名,年龄,城市\n")
fout.write("张三,22,北京\n")
# 逐行读取(大文件推荐,内存友好)
with open("large.txt", "r", encoding="utf-8") as fin:
for line in fin:
print("行内容:", line.strip()) # strip()去除换行符
(2)大文件处理优化(分块读取)
# 分块读取大文件(避免内存溢出)
CHUNK_SIZE = 8192 # 每次读取8KB
with open("huge.log", "rb") as fin: # 二进制模式更快
while chunk := fin.read(CHUNK_SIZE):
process(chunk) # 自定义处理逻辑(如解析日志)
(3)open()模式汇总(关键)
| 模式 | 功能 | 文本/二进制 |
|---|---|---|
r | 只读(默认) | 文本 |
w | 覆盖写入 | 文本 |
a | 追加写入 | 文本 |
r+ | 读写 | 文本 |
rb | 二进制只读 | 二进制 |
wb | 二进制写入 | 二进制 |
3. 避坑点
- ✅ 读写中文文件必须加
encoding="utf-8"(Windows需注意GBK编码场景); - ✅ 优先用
with语句,避免忘记close()导致文件句柄泄漏; - ✅ 大文件用逐行/分块读取,切勿直接
read()加载全部内容。
四、JSON序列化:跨语言数据交换
JSON是轻量级数据交换格式,Python通过json模块实现对象与JSON字符串的转换,适用于数据存储和网络传输。
1. JSON序列化流程(mermaid图解)
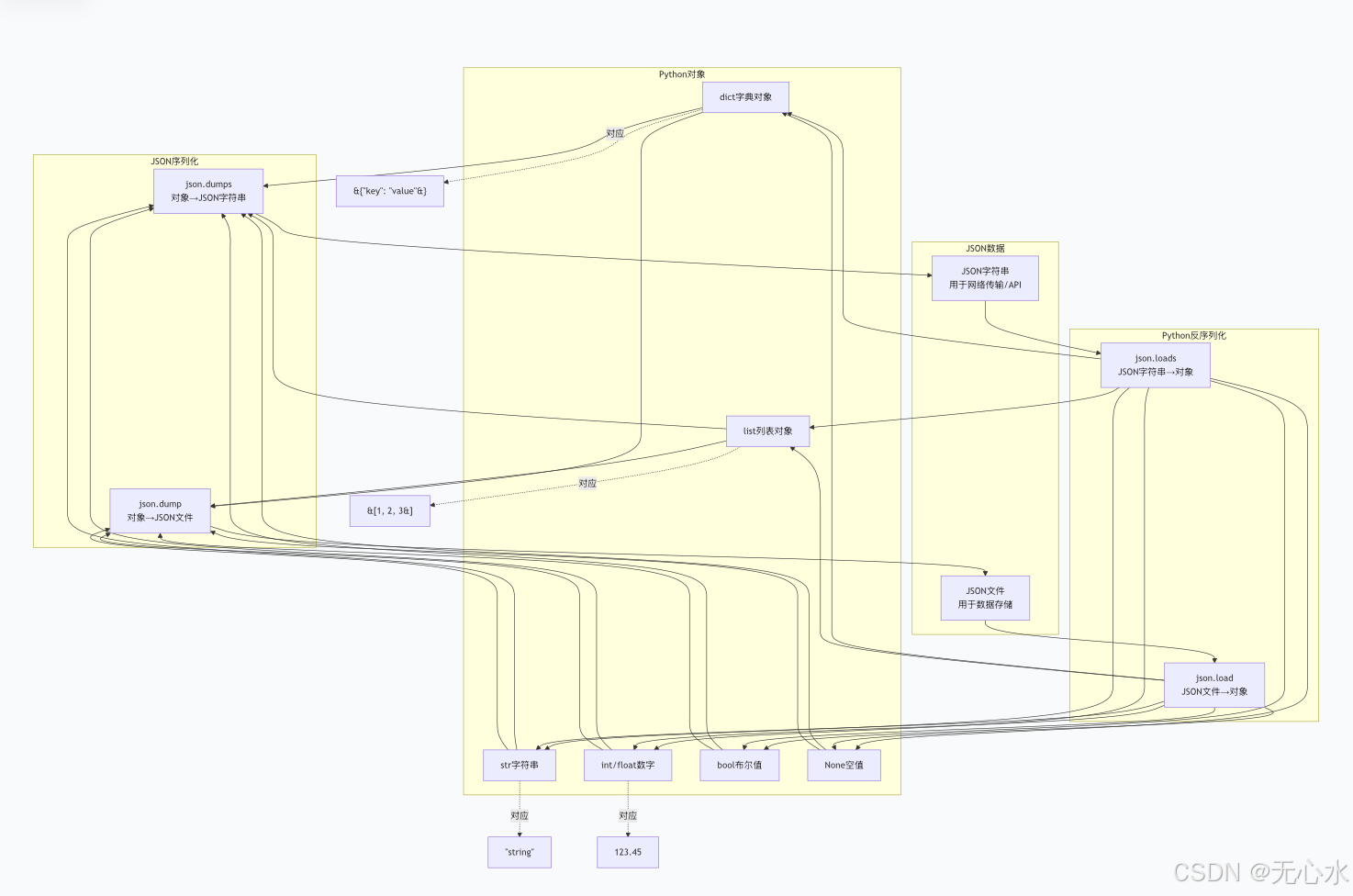
2. 关键代码
(1)基础序列化/反序列化
import json
# Python对象 → JSON字符串
params = {
"name": "张三",
"age": 25,
"scores": [95, 88],
"is_student": True
}
json_str = json.dumps(params, ensure_ascii=False, indent=2) # ensure_ascii=False显示中文
print("JSON字符串:", json_str)
# JSON字符串 → Python对象
original_params = json.loads(json_str)
print("反序列化后:", original_params["name"]) # 输出:张三
# Python对象 → JSON文件
with open("data.json", "w", encoding="utf-8") as fout:
json.dump(params, fout, ensure_ascii=False, indent=2)
# JSON文件 → Python对象
with open("data.json", "r", encoding="utf-8") as fin:
loaded_params = json.load(fin)
print("从文件读取:", loaded_params["scores"]) # 输出:[95, 88]
(2)核心注意事项
ensure_ascii=False:避免中文被编码为Unicode转义符;indent=2:格式化JSON字符串,便于阅读;- 支持的Python类型:
dict、list、str、int、float、bool、None。
五、高级I/O技巧:性能优化与安全
1. 缓冲机制(提升I/O性能)
文件操作默认启用缓冲(4KB/8KB),批量写入比频繁小写入快3-5倍,关键代码:
import time
# 低效:频繁小写入
start = time.time()
with open("slow.txt", "w") as f:
for i in range(100000):
f.write(f"Line {i}\n")
print(f"频繁写入耗时:{time.time()-start:.2f}s")
# 高效:累积后批量写入
start = time.time()
lines = [f"Line {i}\n" for i in range(100000)]
with open("fast.txt", "w") as f:
f.write("".join(lines))
print(f"批量写入耗时:{time.time()-start:.2f}s")
2. pathlib:现代路径处理(替代os.path)
from pathlib import Path
# 创建路径对象(跨平台兼容)
file_path = Path("data/subdir/test.txt")
file_path.parent.mkdir(parents=True, exist_ok=True) # 递归创建目录
# 写入/读取文件
file_path.write_text("Hello Pathlib", encoding="utf-8")
content = file_path.read_text(encoding="utf-8")
print("Pathlib读取:", content)
# glob匹配文件
py_files = list(Path("src").glob("**/*.py")) # 递归查找所有.py文件
print("找到的Python文件:", py_files)
3. 上下文管理器原理
with语句的底层是实现了__enter__和__exit__方法的上下文协议,自定义示例:
class ManagedFile:
def __enter__(self):
self.file = open("test.txt", "w")
return self.file # as关键字接收的值
def __exit__(self, exc_type, exc_val, exc_tb):
self.file.close() # 自动关闭文件
# 使用自定义上下文管理器
with ManagedFile() as f:
f.write("自定义上下文管理器")
六、实战案例:学生成绩统计系统
整合前面的I/O知识,实现“输入成绩→计算平均分→保存结果到文件”的完整流程:
import datetime
def score_statistics():
# 1. 输入:获取3个学生成绩(含输入验证)
scores = []
for i in range(3):
while True:
try:
score = float(input(f"请输入第{i+1}个学生的成绩:"))
scores.append(score)
break
except ValueError:
print("输入错误,请输入数字!")
# 2. 处理:计算平均分
average = sum(scores) / len(scores)
result = f"学生成绩:{scores}\n平均分:{average:.2f}分"
# 3. 输出:打印+保存到文件
print("="*20)
print(result)
with open("score_stat.txt", "w", encoding="utf-8") as f:
f.write(f"统计时间:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M')}\n")
f.write(result)
if __name__ == "__main__":
score_statistics()
七、Python I/O最佳实践总结
- 优先用
with语句:自动管理文件/资源,避免泄漏; - 显式指定编码:读写文本文件必加
encoding="utf-8"; - 按需选择I/O方式:小文件一次性读取,大文件逐行/分块处理;
- 序列化选JSON:跨语言兼容,
pickle仅限Python内部使用; - 输入必做验证:用
try-except处理类型转换错误。
结尾
Python的输入输出看似基础,却贯穿开发全流程。
掌握本文的基础用法、高级技巧和实战案例,能帮你高效处理键盘交互、文件操作、数据序列化等场景。
如果遇到I/O性能瓶颈或编码问题,欢迎在评论区交流!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











