





引⾔
⼤语⾔模型(Large Language Models, LLMs)的横空出世,为传统计算机科学的各个细分领域带来了颠覆性的变⾰。这种变⾰的浪潮同样席卷了⽹络安全领域,引发了⼀系列深刻的变化和影响。GPT-4、Gemini、Llama 2 等⼤模型以其卓越的⾃然语⾔处理能⼒,重新定义了我们对数据安全和⽹络防御的认知,提供了检测和减轻安全威胁的新⽅法。本⽂⼴泛调研 LLMs 在⽹络安全中的多样化应⽤,展⽰它们如何助⼒提升数字世界的安全性和防护能⼒。
LLMs在安全检测中的应⽤
⼤语⾔模型(LLMs)在⾃动化代码⽣成、错误修复和代码修复等任务中的出⾊表现,正在为漏洞检测领域带来前所未有的进步。2023年有将近29,000个CVEs被公开。随着CVEs数量的增加,有效漏洞检测和管理的需求⽇益增⻓。
LLMs越来越多地被⽤于设计增强代码开发和管理的⼯具中。这些⼈⼯智能驱动的⼯具,例如Devin AI、GitHub Copilot、IBM的watsonx、Amazon CodeWhisperer和Codeium等,能够执⾏代码⽣成、代码补全、代码修复和代码重构等复杂任务。
⼀篇关于⼈⼯智能代码辅助⼯具安全性的研究表明,⼈⼯智能代码助⼿引⼊的漏洞⽐⼈类开发者要少。通过将⾃然语⾔描述转换为代码,LLMs有潜⼒彻底改变软件开发领域。这些⼯具不仅降低了新⼿开发⼈员的⼊门门槛,还帮助减少了软件开发过程中的漏洞,展现出LLMs在降低软件开发缺陷⽅⾯的显著优势。
GPTScan通过结合GPT和静态分析⼯具,有效地检测智能合约中的逻辑漏洞,具有⾼精确度、可接受的召回率,并且能够快速且成本效益⾼地发现⼈类审计员可能遗漏的新漏洞。

图1 GPTScan⼯具架构图
LLMs不仅在检测漏洞⽅⾯发挥作⽤,还能⾃动修复漏洞。例如,⾕歌的⼤模型Gemini成功修复了他们通过消毒⼯具发现的⼤量漏洞。此外,像AutoCodeRover这样的解决⽅案在⾃动修复代码漏洞⽅⾯表现出了显著的效率。该系统在不到12分钟的时间内解决了67个GitHub问题,远远超过了⼈类开发者平均所需的时间。
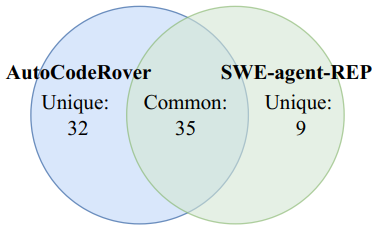
图2 AutoCodeRover与SWE-agent-REP解决任务对⽐
漏洞检测⼯具LLbezpeky在Android端展⽰了在识别和修复漏洞⽅⾯的显著潜⼒,通过精⼼设计的提⽰⼯程(prompt engineering)和检索增强⽣成技术,正确标记了91.67%的Ghera基准测试中的不安全应⽤。
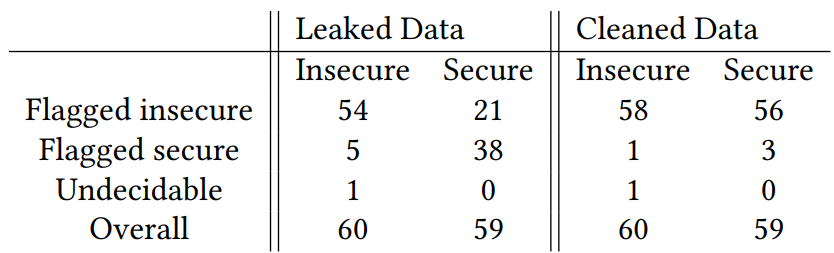
图3 LLbezpeky漏洞检测⼯具测试样本结果
这些应⽤展⽰了LLMs⾼效识别和减轻软件漏洞威胁的能⼒,为未来的⾃动化安全分析⼯具开发提供了有价值的参考和启⽰。通过利⽤LLMs的强⼤的上下⽂分析能⼒,⽹络安全专业⼈员可以提前应对潜在威胁,降低被利⽤的⻛险。
除了代码开发,LLMs也正被⽤来增强或⾃动化多种通⽤的安全分类器。它们在检测有害内容、执⾏政策是否合规以及在线平台的内容审核⽅⾯发挥着重要作⽤。
随着社交平台上有害内容的不断增加
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









