



1、支持哪几种数据类型
支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
2、为什么读写速度很快
redis完全基于内存
数据结构简单
采用单线程,避免了加锁、释放锁、死锁、线程间切换等消耗
使用多路I/O复用模型,非阻塞IO
3、在你们项目有哪些应用场景
计数器:对 string 进行自增自减运算,从而实现计数器功能。redis 内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。如每日登录次数计数。
热点数据缓存:将热点数据放到内存中。如首页排行榜数据,具有很大访问频次,使用zset可以实现基于score分数排序;。
会话缓存:用redis统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
取数据交集、并集:基于redis set 的特性可以对共同好友进行很方便的查询。
分布式事务锁的使用:基于set lock requestId nx ex time 模式可以很方便编写分布式事务锁
4、基于什么协议
Redis 的通信协议是 Redis Serialization Protocol,翻译为 Redis 序列化协议,简称 RESP
在 TCP 层
是二进制安全的
基于请求 - 响应模式
简单、易懂(人都可以看懂)
5、线程模型是怎样的?
Redis 的线程模型:基于非阻塞的IO多路复用机制的线程模型,单线程
Redis 是基于 reactor 模式开发了网络事件处理器,这个处理器叫做文件事件处理器(file event handler)。由于这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。采用 IO 多路复用机制同时监听多个 Socket,根据 socket 上的事件来选择对应的事件处理器来处理这个事件。模型如下图:
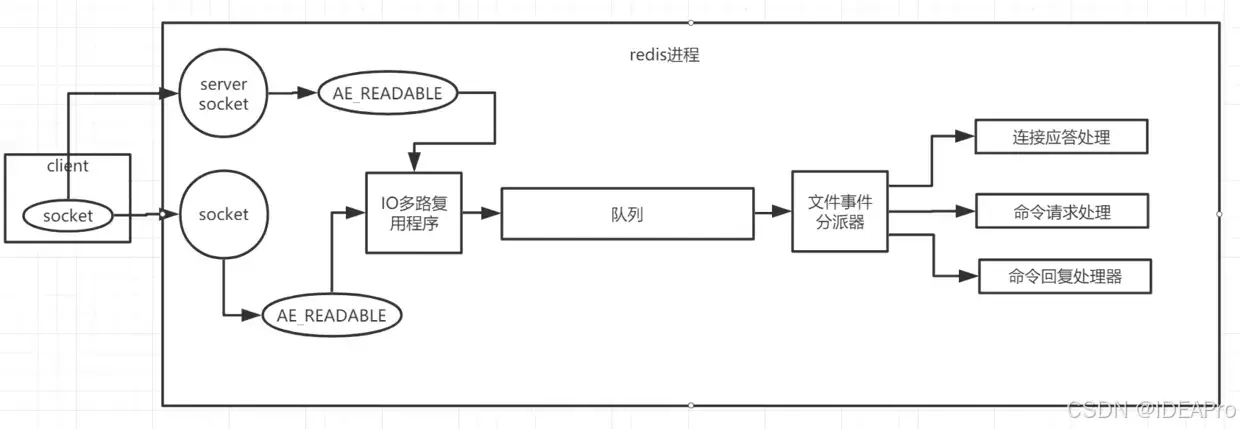
上图得知,文件事件处理器的结构包含了四个部分:
多个 Socket:客户端发起多个 socket,每个socket 会产生不同的事件,不同的事件对应着不同的操作
IO 多路复用程序:IO 多路复用程序监听着这些 Socket,当这些 Socket 产生了事件,IO 多路复用程序会将这些事件放到一个队列中。
文件事件分派器:通过队列,将事件以有序、同步、每次一个事件的方式向文件事件分派器中传送,文件事件分派器将事件按类型分派给不同的事件处理器进行处理。
事件处理器:分为连接应答处理器、命令请求处理器、命令回复处理器,每个处理器对应不同的 socket 事件。
6、持久化机制是怎样的?
第一种:RDB,即 Redis 的内存快照,默认持久化机制,它是在某一个时间点将 Redis 的内存数据全量写入一个临时文件,当写入完成后,用该临时文件替换上一次持久化生成的文件,这样就完成了一次持久化过程,默认的文件名为dump.rdb。
1)、触发RDB机制:
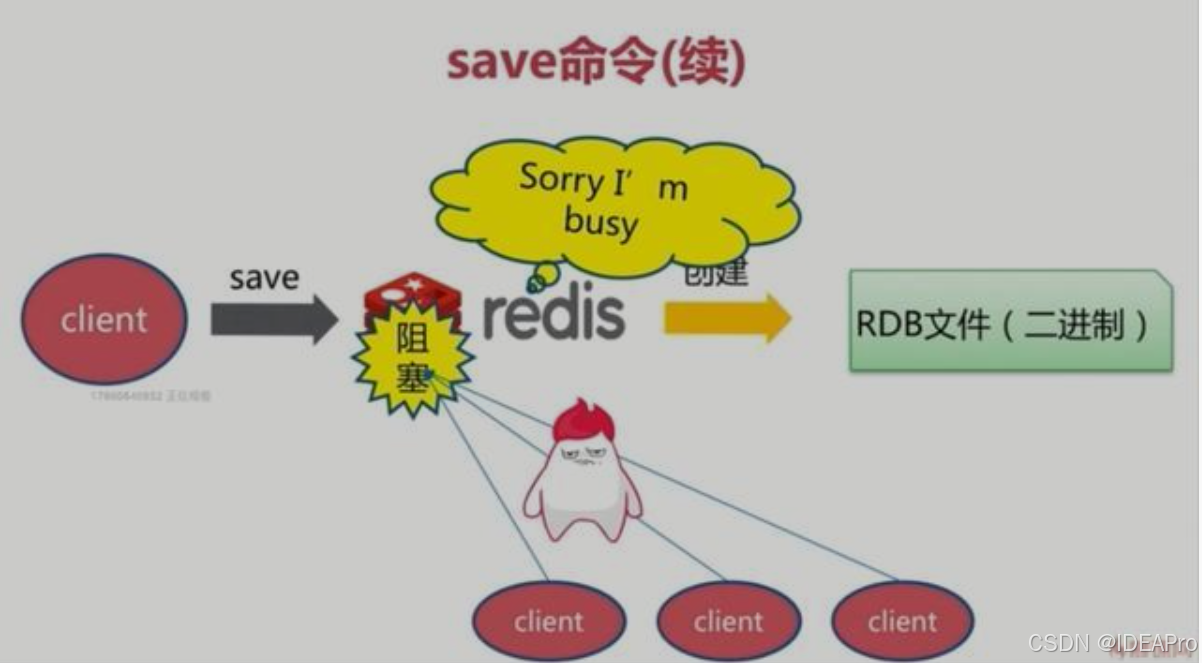
(1)、save触发方式:该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
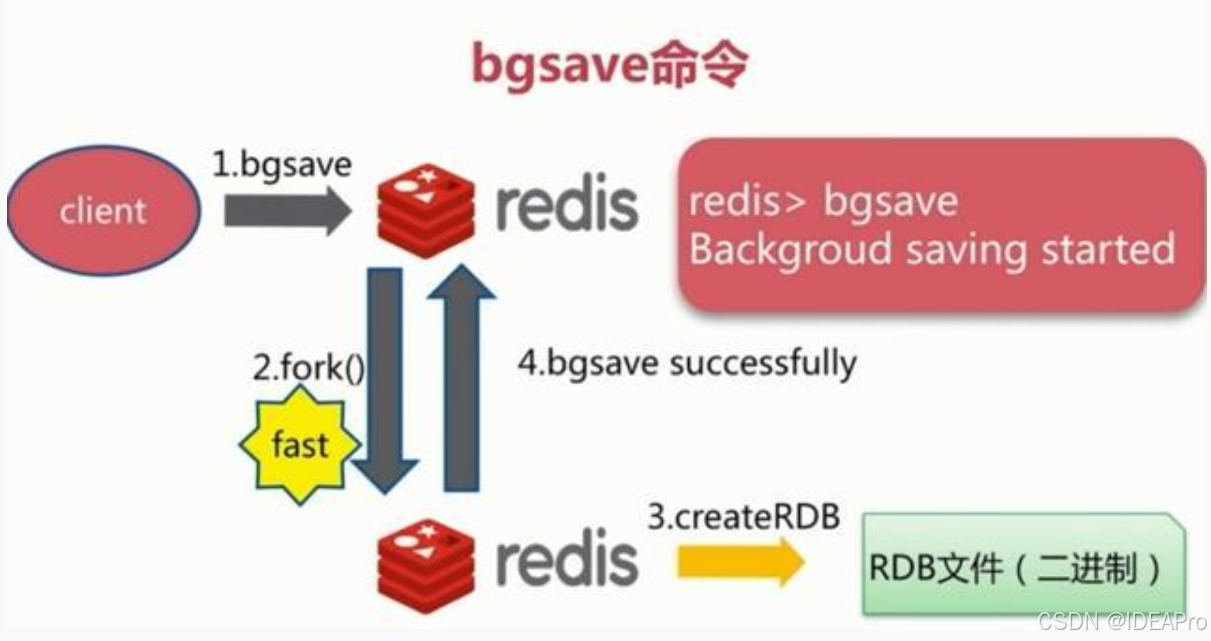
(2)、bgsave触发方式:执行该命令时,Redis会在后台异步fork出一个子进程进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
(3)、自动触发自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
save配置 这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
2)、优点:
>由于 RDB 文件是一个非常紧凑的二进制文件,所以加载的速度会快于 AOF 方式;
>fork 子进程方式,除了fork线程阶段,其他时候不会阻塞;
>RDB 文件代表着 Redis 服务器的某一个时刻的全量数据,所以它非常适合做冷备份和全量复制的场景;
3)、缺点:
>没办法做到实时持久化,会存在丢数据的风险。定时执行持久化过程,如果在这个过程中服务器崩溃了,则会导致这段时间的数据全部丢失。
第二种:AOF,即 append only file,它是将每一行对 Redis 数据进行修改的命令以独立日志的方式存储起来。由于 Redis 是将“操作 + 数据” 以格式化的方式保存在日志文件中,他代表了这段时间所有对 Redis 数据的的操作过程,所以在数据恢复时,我们可以直接 replay 该日志文件,即可还原所有操作过程,达到恢复数据的目的。它的主要目的是解决了数据持久化的实时性。
注意:AOF 默认关闭,需要在配置文件 redis.conf 中开启,appendonly yes。
1)、AOF 总共分为三个流程:
(1)、命令写入:将命令写入缓冲区
(2)、文件同步:命令写入到缓冲区,然后根据不同的策略刷到硬盘中。Redis 提供提供了三种不同的同步策略:

(3)、文件重写:随着命令的不断写入,AOF 文件会越来越庞大,直接的影响就是导致“数据恢复”时间延长,而且有些历史的操作是可以废弃的(比如超时、del等等),为了解决这些问题,Redis 提供了 “文件重写”功能,该功能有手动和自动两种方式触发。
重写AOF主要做了以下事情:
1、已过期的数据不在写入文件。
2、保留最终命令。例如 set key1 value1 、set key1 value2、....set key1 valuen,类似于这样的命令,只需要保留最后一个即可。
3、删除无用的命令。例如 set key1 valuel;del key1,这样的命令也是可以不用写入文件中的。
4、多条命令合并成一条命令。例如 lpush list a、lpush list b、lpush list c,可以转化为 lpush list a b c
2)、优点
> 相比于 RDB,AOF 更加安全,默认同步策略为 everysec 即每秒同步一次,所以顶多我们就失去一秒的数据;
> 根据关注点不同,AOF 提供了不同的同步策略,我们可以根据自己的需求来选择;
> AOF 文件是以 append-only 方式写入,相比如 RDB 全量写入的方式,它没有任何磁盘寻址的开销,写入性能非常高;
3)、缺点
> 由于 AOF 日志文件是命令级别的,所以相比于 RDB 紧致的二进制文件而言它的加载速度会慢些。
> AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低。
第三种:RDB-AOF 混合模式(鱼和熊掌可兼得的方案)
通过上面的介绍我们知道了 RDB 和 AOF 各有自己的优缺点,选择任意其一都需要接受他的缺点:
RDB 能够快速地存储和恢复数据,但是在服务器宕机时会丢失大量的数据,没有保证数据的实时性和安全性;
AOF 能够实时持久化数据并且提高了数据的安全性,但是在存储和恢复数据方面又会消耗大量时间;
Redis 4.0 推出了 RDB-AOF 混合持久化方案,该方案是在 AOF 重写阶段创建一个同时包含 RDB 数据和 AOF 数据的 AOF 文件,其中 RDB 数据位于AOF 文件的开头,他存储了服务器开始执行重写操作时 Redis 服务器的数据状态(RDB 快照方案),重写操作执行之后的 Redis 命令,则会继续 append 在 AOF 文件末尾,一般这部分数据都会比较小。这样在 Redis 重启的时候,则可以先加载 RDB 的内容,然后再加载 AOF 的日志内容,这样重启的效率则会得到很大的提升,而且由于在运行阶段 Redis 命令都会以 append 的方式写入 AOF 文件,保证了数据的实时性和安全性。
7、慢查询如何排查?
Redis 执行命令分为四个步骤:发送命令、命令排队、执行命令、返回结果。慢查询只关注步骤 3执行命令 的时间,所以没有慢查询并不代表客户端没有超时问题。
Redis 慢查询可通过配置两个参数进行:
slowlog-log-slower-than:设置慢查询预设的超时阈值,单位是微秒
slowlog-max-len:表示慢查询日志存储的条数
Redis 中有两种修改配置的方法,一种是修改配置文件,另一种是使用 config set 命令动态修改:
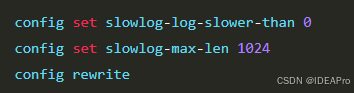
slowlog-log-slower-than:默认是 1000 微秒,QPS太小,实际生产建议把这个参数调的更小一些
它表示的是慢查询预设的超时阈值。它所阐述的意思是如果某条命令(如 keys *) 执行”很慢“,执行时间超过了设置的阈值,那么这条命令将会被记录到慢查询日志中。
若设置 slowlog-log-slower-than = 0,则会记录所有命令
若设置 slowlog-log-slower-than < 0,则不会记录任何命令
slowlog-max-len:实际生产中这个参数可以设置得大一些,如1000以上,可以减缓慢查询被剔除的可能
Redis 会使用一个列表来存储慢查询日志,slowlog-max-len 就是该列表的最大长度。一个命令如果满足慢查询阈值条件则会加入到该列表来,但是如果该列表已经
处于最大长度时,那么会删除最开始的一条记录,然后将最新的命令插入到末尾,所以慢查询日志列表是一个有限的先进先出列表。
通过slowlog get [n]命令获取慢查询日志:
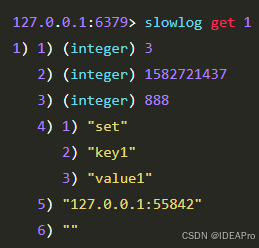
返回的慢查询日志由 4 个属性组成:1、日志的标识 id 2、发生的时间戳 3、命令耗时 4、执行的命令和参数
用户发起请求
redis
mysql -> redis
8、缓存穿透?缓存击穿?缓存雪崩?
缓存穿透:是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
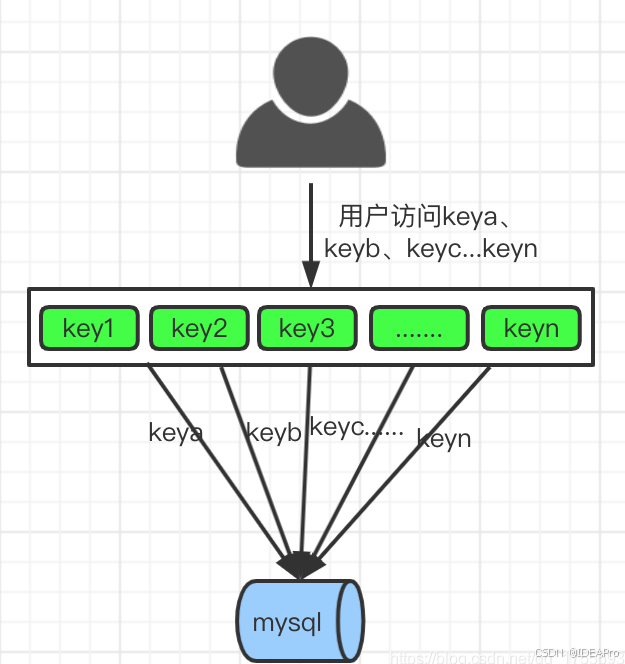
解决方案:
1)、从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击;
2)、引入布隆过滤器,过滤一些异常的请求。
3)、接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
缓存击穿:是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
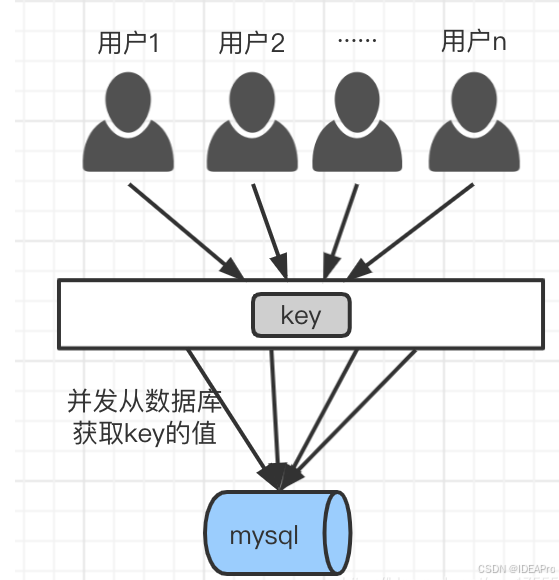
解决方案:
1)、设置热点数据不过期;
2)、第一时间去数据库获取数据填充到redis中,但是这个过程需要加锁,防止所有线程都去读取数据库,一旦有一个线程去数据库获取数据了,其他线程取锁失败后可设置一个合理睡眠时间之后再去尝试去redis中获取数据;
public class SingnObjectUtil{
private Student s;public Student getStudent1(){
if(s != null){
return s;
}
return getStudent2();
}private synchronized Student getStudent2(){
if(s != null){
return s;
}
s = new Student;
return s;
}
缓存雪崩:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是大批量数据都过期了,大量数据都从redis中查不到,从而查数据库。
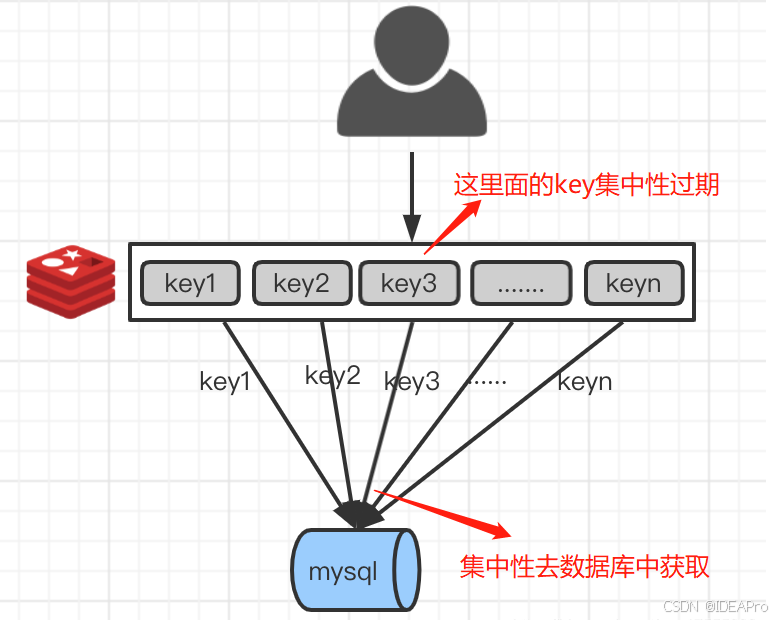
解决方案:
1)、缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2)、如果缓存数据库是分布式部署,将热点数据均匀分布在不同的数据库中。
3)、允许的话,设置热点数据永远不过期。
4)、要保证redis的高可用,可以使用主从+哨兵或redis cluster,避免服务器不可用;
5)、使用redis的持久化RDB+AOF组合策略,防止缓存丢失并且可以快速恢复数据;
9、相比memcached有哪些区别?
redis支持丰富数据类型,支持字符串、链表、哈希、集合和有序集合,Memcache对数据类型支持相对简单,只支持字符串
Redis将数据存在内存和硬盘上,这样能保证数据的持久性,Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
10、键过期删除如何实现的?
redis中可以设置键的过期时间,到期后自动进行删除,那么redis中是怎么实现过期删除的?
定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
11、分布式事务锁怎么实现的?会有什么问题?
通过setnx上锁方式实现,但是不注意写法很可能会出现很多问题;
错误用法:先通过setnx上锁,再通过expire设置过期时间,最后执行完任务后手动del释放锁;
场景一问题(死锁):通过setnx上锁后出现异常,导致无法去expire设置锁的过期时间,更无法最后去手动释放锁,造成死锁!
解决:使用上锁最新写法,保证上锁、设置过期时间一步完成的原子性: set(lockKey,value,nx,ex,exporeTime);
场景二问题(误删锁):A机器中上锁并设置过期时间完成以后后,系统出现了阻塞,导致锁到了过期时间并自动删除了,这时还没有执行手动释放锁的操作,这个时候B机器上锁成功,并去执行任务,任务还未执行完,A机器反应过来了,继续执行了手动释放锁的操作,把B机器上的锁给误删了。
解决:上锁同时加上一个锁id,如当前线程ID,将锁id存入value值并记录在变量中,手动释放锁的时候比较一下value中的锁id跟变量中id是否一致,也就是判断一下是否自己还在持有锁,如果不是,就不执行删除操作了。
场景三问题(误删锁):这种误删锁是基于场景2判断锁id和释放锁操作这两步没有保证原子性所导致的。
具体为:A机器带锁id方式取锁、设置过期时间并执行完任务后,希望通过判断比较锁id之后去释放锁,判断通过后系统出现阻塞,阻塞到锁也到了过期时间自动释放了锁,这时还未进行手动释放锁操作,这个时候B机器上锁成功,并去执行任务,任务还未执行完,A机器反应过来了,继续执行了手动释放锁的操作,把B机器上的锁给误删了。
解决:保证判断锁和释放锁的原子性:使用redis执行LUA脚本,保证一步执行判断锁和释放锁。
String luaScript = 'if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end';
redisClient.eval(luaScript , Collections.singletonList(key),Collections.singletonList(threadId));
场景四问题(锁续命):这种场景是指线程中任务还没执行完,锁就已经到过期时间,这种情况可以给任务执行线程添加守护线程,守护线程负责对锁的expire时间进行监控,每当到过期前一秒就对过期进行判断,如果任务还在进行且锁马上过期,则对过期时间重新进行设置。
综上:正确使用redis分布式事务锁需要保证两个原子性:
1、上锁和设置过期时间需要保证原子性;
2、 判断锁ID是否为自己所有和解锁需要保证原子性;
补充:其实关于上述四个场景的问题,使用redis客户端Redisson都能够得到很好的解决,redisson内部已经实现了上述几点问题的解决机制,原理同上。

















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









