







 本文深入探讨了ElasticSearch的六层架构设计,包括数据存储、Lucene框架、数据处理方式、发现机制、传输模块及API支持。揭示了ElasticSearch如何通过这些层次实现高效的数据检索和管理。
本文深入探讨了ElasticSearch的六层架构设计,包括数据存储、Lucene框架、数据处理方式、发现机制、传输模块及API支持。揭示了ElasticSearch如何通过这些层次实现高效的数据检索和管理。
ElasticSearch 架构设计层次
ElasticSearch的总体结构,如下图
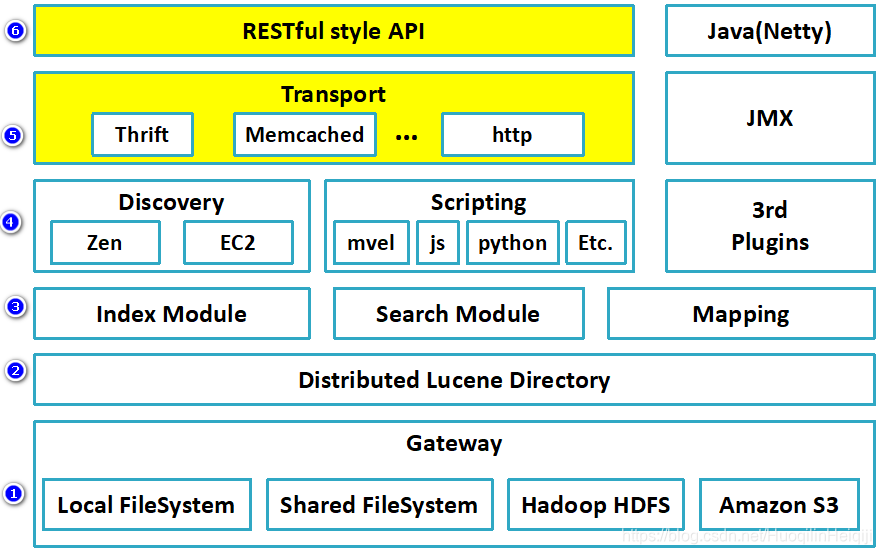
第一层 —— Gateway:即Elasticsearch支持的索引数据的存储格式,当Elasticsearch关闭再启动的时候,它就会从这个gateway里面读取索引数据;支持的格式有:本地的Local FileSystem、分布式的Shared FileSystem、Hadoop的文件系统HDFS等。
第二层 —— Lucene框架: Elasticsearch 的底层 API 是 由 Lucene 提供的,每一个 Elasticsearch 节点上都有一个 Lucene 引擎的支持 。
第三层 —— Elasticsearch数据的加工处理方式:Index Module(创建Index模块)、Search Module(搜索模块)、Mapping(映射)、River(运行在Elasticsearch集群内部的一个插件,主要用来从外部获取获取异构数据,然后在Elasticsearch里创建索引,常见的插件有RabbitMQ River、Twitter River,在2.x之后已经不再使用)。
第四层 —— Elasticsearch发现机制、脚本:Discovery 是Elasticsearch自动发现节点的机制;Zen是用来实现节点自动发现、Master节点选举用;(Elasticsearch是基于P2P的系统,它首先通过广播的机制寻找存在的节点,然后再通过多播协议来进行节点间的通信,同时也支持点对点的交互)。Scripting 是脚本执行功能,有这个功能能很方便对查询出来的数据进行加工处理。3rd Plugins 表示Elasticsearch支持安装很多第三方的插件,例如elasticsearch-ik分词插件、elasticsearch-sql sql插件。
第五层 ——Elasticsearch 的传输模块和 JMX 。 传输模块支持 Thrift, Memcached 、 HTTP,默认使用 HTTP 传输 。 JMX 是 Java 的管理框架,用来管理 Elasticsearch 应用 。
第六层 —— Elasticsearch的API支持模式:通过阻STful API 和 Elasticsearch 集群进行交互

















 2048
2048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









