







 本文介绍了如何使用Python的pandas库进行数据分箱操作,对比了`pd.cut()`函数与`apply()`函数在对 salary 列进行'低'、'中'、'高'类别划分时的使用方法。通过示例展示了`pd.cut()`的简洁性和效率,并扩展讲解了该函数在分数区间划分中的应用,以及如何自定义分箱标签、是否包含边界等参数。此外,还提供了分箱结果在groupby分组中的应用示例。
本文介绍了如何使用Python的pandas库进行数据分箱操作,对比了`pd.cut()`函数与`apply()`函数在对 salary 列进行'低'、'中'、'高'类别划分时的使用方法。通过示例展示了`pd.cut()`的简洁性和效率,并扩展讲解了该函数在分数区间划分中的应用,以及如何自定义分箱标签、是否包含边界等参数。此外,还提供了分箱结果在groupby分组中的应用示例。

import pandas as pd
data = {'name':['Odin','Mark','Bob','Lee','Ruby','Rita'],
'salary':[20500, 5000, 3500, 8000, 15000, 16500]}
df = pd.DataFrame(data)
bins = [0, 5000, 20000, 50000]
group_names = ['低','中','高']
df['categories'] = pd.cut(df['salary'], bins, labels=group_names)源数据df

处理后的数据df
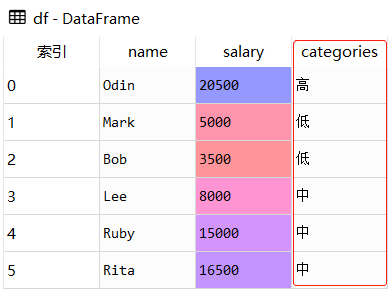
注意:bins和lables它们俩是一一对应的
categories取值判断条件:
0 < salary <= 5000,categories取值为'低'
5000 < salary <= 20000,categories取值为'中'
20000 < salary <= 50000,categories取值为'高'
如果用apply函数替换上述操作,实现上述需求如下所示:
import pandas as pd
data = {'name':['Odin','Mark','Bob','Lee','Ruby','Rita'],
'salary':[20500, 5000, 3500, 8000, 15000, 16500]}
df = pd.DataFrame(data)
def fn(row):
if row['salary'] > 0 and row['salary'] <= 5000:
return '低'
if row['salary'] > 5000 and row['salary'] <= 20000:
return '中'
if row['salary'] > 20000 and row['salary'] <= 50000:
return '高'
df['categories'] = df.apply(lambda row:fn(row), axis=1)从上述可以看出,相对于使用apply函数,使用pd.cut()比较简约
扩展补充:定界分箱pd.cut()
pd.cut()可以指定区间将数字进行划分
以下例子中的0、60、100三个值将数据划分成两个区间,从而将及格或者不及格分数进行划分:
import pandas as pd
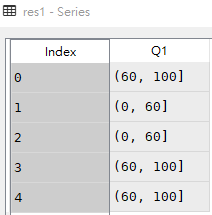
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 将Q1成绩换60分及以上、60分以下进行分类
res1 = pd.cut(df.Q1, bins=[0, 60, 100])df
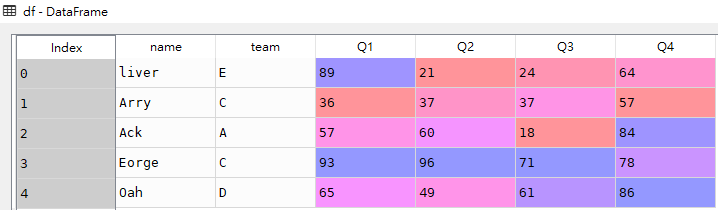
res1
将分箱结果应用到groupby分组中
# Series使用
df.Q1.groupby(pd.cut(df.Q1, bins=[0, 60, 100])).count()
'''
Q1
(0, 60] 2
(60, 100] 3
Name: Q1, dtype: int64
'''
以下显示了每个分组的数据,其他参数示例如下:
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
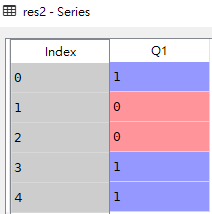
# 不显示区间,使用数字作为每个箱子的标签,形式如0,1,2...n
res2 = pd.cut(df.Q1, bins=[0, 60, 100], labels=False)
# 指定标签名
res3 = pd.cut(df.Q1, bins=[0, 60, 100], labels=['不及格','及格'])
# 包含最低部分
res4 = pd.cut(df.Q1, bins=[0, 60, 100], include_lowest=True)
# 是否为右闭区间,下例为[89,100)
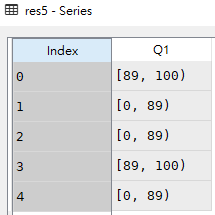
res5 = pd.cut(df.Q1, bins=[0, 89, 100], right=False)
res2
res3

res4

res5

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









