







文章目录
pandas
fillna和dropna
这个讲得比较详细
print(doc)作用
作用
输出文件开头注释的内容
推广
1)momodule.py
"""This is the module docstring."""
def f(x):
"""This is the function docstring."""
return 2 * x
执行
>>> import mymodule
>>> mymodule.__doc__
'This is the module docstring.'
>>> mymodule.f.__doc__
'This is the function docstring.'
对象传递是传值还是传引用
http://winterttr.me/2015/10/24/python-passing-arguments-as-value-or-reference/
要看传入的是什么参数
由于python的东西存储的都是地址,所以正常情况下传递参数实际上是传递参数的地址进去,但是有些数据类型是immutable的( like int ,str ),有些是mutable的( like list ),所以我们可以利用这点
numpy
获取非零元素
np.nonzeros( np.array ) --> index
判断对称矩阵
np.allclose ( a,a.T )
加号 操作符
- 对于list和tuple
(1,2)+(1,2)
>>> (1,2,1,2)
[1,2]+[1,2]
>>> [1,2,1,2]
- 对于string
py里面的string都是一旦声明就固定长度了的,如果用加号,就会重新开辟一段固定大小的内存然后分别拷贝进去,比较浪费时间,所以尽量用join (没有细究,网上看到的
Anaconda, conda, pyenv, virtualenv的区别
https://www.cnblogs.com/lypniuyou/p/9518751.html
装饰器
def hesy(func):
def hesyDec(*args,**kwargs):
print("come into hesyDesc")
return func(*args,**kwargs)
return hesyDec
#%% decrator test
@hesy
def nihao():
print("nihao")
nihao()
>>> come into hesyDesc
>>> nihao
画图
不规则多子图
refer @ movan
import matplotlib
import matplotlib.pyplot as plt
plt.subplot(211)
plt.plot([0,1],[0,2])
plt.subplot(234)
plt.plot([0,1],[0,3])
plt.subplot(235)
plt.plot([0,1],[0,4])
类似效果

rcParams
rc就是running config的意思
plt.rcParams['figure.figsize'] = figsize
还有很多参数 也可以直接设置matplotlib的rcParams,which自然也include了plt的参数

参数中的单星号和双星号
单星号
- 单星号(*):*agrs
将所以参数以元组(tuple)的形式导入:
例如:
>>> def foo(param1, *param2):
print param1
print param2
>>> foo(1,2,3,4,5)
1
(2, 3, 4, 5)
- 另一个用法是解压参数列表
>>> def foo(bar, lee):
print bar, lee
>>> l = [1, 2]
>>> foo(*l)
1 2
双星号
双星号(**):**kwargs
将参数以字典的形式导入
>>> def bar(param1, **param2):
print param1
print param2
>>> bar(1,a=2,b=3)
1
{'a': 2, 'b': 3}
collections模块
ref 廖雪峰
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
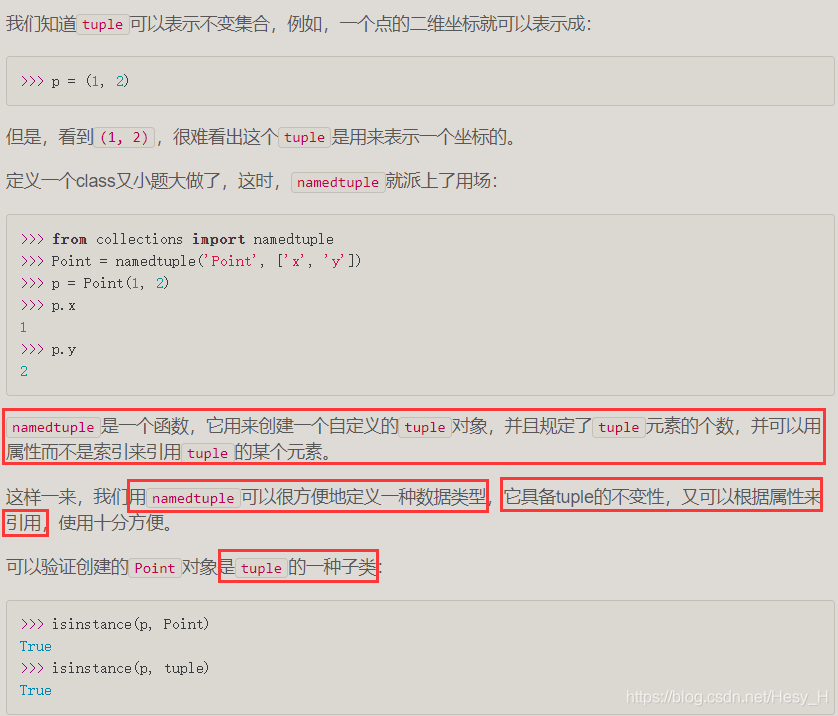
OrderedDict
-
在对dict做迭代时,我们无法确定Key的顺序。
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序 -
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
【装饰者模式】
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value)
生成器 迭代器 可迭代对象
ref @ https://foofish.net/iterators-vs-generators.html
-
容器( list ,set dict )一般来说是可迭代的,但并不是因为他们是容器,而是因为他们是可迭代对象,可以返回迭代器
-
迭代器iterator需要实现三个类
- __ init__ () [废话]
cur = 0, next =1
self.iterObject = xxxx是一个可迭代对象iterable
- __ next __() [获取下一个元素 , 还要维护cur ]
cur =next
next =next +1
return cur- __ iter__() [ 返回迭代器 ]
return self
-
生成器generator是一个特殊的迭代器,但是只需要里利用yiel的关键字。生成器一定是迭代器(反之不成立),但是由于其延迟加载的特性,使得内存消耗比较小
- 使用yield 重构代码:
def something(): result = [] for ... in ...: result.append(x) return result一律可以重写成
def iter_something(): for ... in ...: yield x这样传输消耗会小很多
-
生成器表达式
这个生成的是个列表 【列表表达式】
a = [x*x for x in range(10)]
print(type(a))
print((a))
>>> <class 'list'>
>>> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
这个生成的是个生成器
b = (x*x for x in range(10))
print(type(b))
print((b))
>>> <class 'generator'>
>>> <generator object <genexpr> at 0x000002521B422990>
- 注意,generator是不可以通过index索引的,但是list是可以的
x=[ x for x in range(3) ][1]
print(x)
>>> 1
y=( x for x in range(3) )[1]
print(y)
>>> TypeError xx.py in
----> 1 y=( x for x in range(3) )[1]
2 print(y
TypeError: 'generator' object is not subscriptable
反汇编模块dis
-
Python 代码先被编译为字节码后,再由Python虚拟机来执行字节码, Python的字节码是一种类似汇编指令的中间语言, 一个Python语句会对应若干字节码指令,虚拟机一条一条执行字节码指令, 从而完成程序执行。
-
dis — Disassembler for Python bytecode,即把python代码反汇编为字节码指令.
-
注意,一个python字节码指令并不是对应一个机器指令(二进制指令),而是对应一段C代码,而不同的指令的性能不同,所以不能单独通过指令数量来判断代码的性能,而是要通过查看调用比较频繁的指令的代码来确认一段程序的性能。
使用方法一 python -m dis xxx.py
使用超级简单:python -m dis xxx.py
这里以分析while 1 和while true的性能为例:
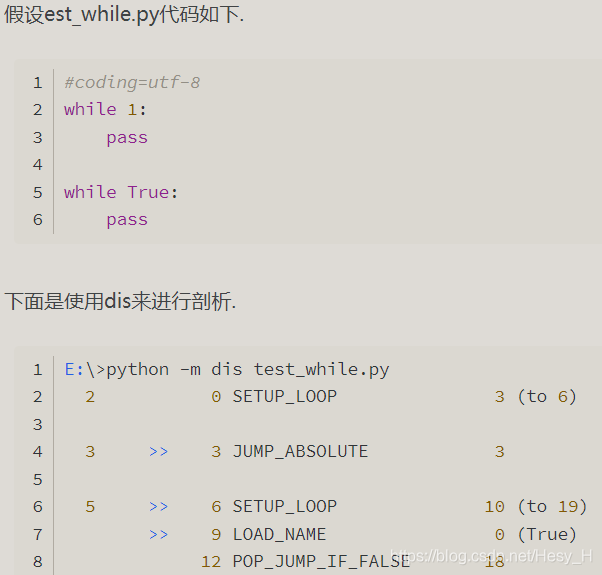

原来True在python2中不是一个关键字,只是一个内置的变量,bool类型,值为1,即True+True输出2.
而且还可以被赋值.比如赋值True = 2, 甚至可以赋值True = False.
所以while True的时候, 每次循环都要检查True的值, 对应指令LOAD_NAME
使用方法二 dis.dis ( [bytesource] )
bytesource是一个代码块
In[6]: def test():
... x = 1
... if x < 3:
... return "yes"
... else:
... return "no"
代码执行后输出:
In[7]: import dis
In[8]: dis.dis(test)
2 0 LOAD_CONST 1 (1)
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (3)
12 COMPARE_OP 0 (<)
15 POP_JUMP_IF_FALSE 22
4 18 LOAD_CONST 3 ('yes')
21 RETURN_VALUE
6 >> 22 LOAD_CONST 4 ('no')
25 RETURN_VALUE
26 LOAD_CONST 0 (None)
29 RETURN_VALUE
以第一条指令为例, 第一列的数字(2)表示对应源代码的行数。第二列的数字是字节码的索引,指令LOAD_CONST在0位置。英文那一列列是指令本身对应的人类可读的名字。倒数第二列表示指令的参数(如果没有参数就是0)。最后一列则是计算后的实际参数(写在括号里面)。其中的“>>" 一个labelled instruction , 第15行的“22” 表明了跳转到索引为22的指令。
- 也可以这样用:dis.dis( ’ for _ in x: pass’)
文件读写的字符格式
import json
with open(str file ,'a' ,encoding=utf-8') as f:
f.write(json.dumps(content ,ensure_ascii=False) +'\n')
查看帮助文档 查看对象属性和函数
- dir( className/functionName )
- 相关的还有 getattr() setattr() hasattr()
hasattr(object,x)主要判断该object是否有x这个属性,如果有,则返回true。若没有则会报错,但我们可以设置默认返回值。
getattr(object,x) 主要返回对象object的x属性,也可以将对象object的x属性赋值给另外一个对象。
setattr(object,x,y) 主要设置对象object的x属性值为y。
注意,python里面 一切皆对象,类的实例、或者类本身、或者一个函数都是一个对象
这种用法也可以 ,此时display不是一个类也不是一个类的实例或者函数 ==》 但是一切皆为对象!from Ipython import display dir(display)
ipython的多样功能
内省
除了上面提到的,还有:
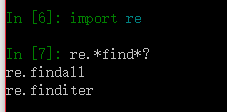
可以使用通配符字符串查找出所有与该通配符字符串相匹配的名称,比如我们查找re模块下所有的包含find的函数:
魔法命令
refer @
https://blog.youkuaiyun.com/gavin_john/article/details/53086766
https://zhuanlan.zhihu.com/p/55723473
单个百分号表示对这一行有效,放在单行行首
两个百分号表示对这一个Cell有效,放在Cell最开头,单独一行
%hist
%hist -n 会把in的输入序号也放出来
%timeit / %time
%timeit是运行100000次测试运行时间(比%time更加准确,避免了单次运行的偶然性)
%matplotlib inline
一个notebook中只需要运行一次,则之后用matplotlib库作图不需要plt.show()即可把图展示出来。
%lsmagic
! 调用系统命令
like !where python
也可以用%%bash运行整个Cell的shell命令
-
ipython继承Unix风格命令
%ls
%cd
%pwd -
看某个魔法命令的文档
eg:%run?
help(%run)
两个都可以 -
还有很多,like列出全局变量 自动导入更新包之类的,更多请看那两个链接
…
display模块
可以在ipython shell里面(自然including jupyter notebook)显示image
ndarray.shape和.size 以及tensor.size()
- ndarray.shape和.size都是属性。 前者返回tuple(row,col) 【二维情况下】,后者返回整个array的总体元素个数【无论多少维】
- tensor.size() ,这里size是函数,返回的和ndarray.shape得到的结果类似,但是是tensor(row,col),而且没有shape的函数和属性
- ndarray很搞笑的是,np.random_norm( mu , sigma , size=tuple ) ==> 这里又变成了size,而不是shape
补充
格式转换
json.dumps() <==> json.loads()
- dumps是将dict转化成str格式,loads是将str转化成dict格式。
- dump和load也是类似的功能,只是与文件操作结合起来了。
# transform dict data into str(/file)
json.dump( jsonData ,fileHandler ) -> str
json.dumps( jsonData ) -->void
# transform str in file into dict data
json.load( fileHandler) -> dict
# transform strData(json format) into dict data
json.loads( jsonData ) -> dict
- 实际上,dump很少用,用的比较多的是dumps
需要注意的是,在python中其实没有json格式,json格式的数据实际上就是用str存储的。 但是,json.dumps( dict data )和str( dict data )得到的结果又是不一样的。证明如下:
>>> d = {'a': 1, 'b': 2}
>>> d_d = {"a": 1, "b": 2}
>>> string = str(d)
>>> string_d = str(d_d)
>>> js = json.dumps(d)
>>> js_d = json.dumps(d_d)
>>> string == string_d
True
>>> js = js_d
True
>>> string == js
False
>>> string
"{'a': 1, 'b': 2}"
>>> js
'{"a": 1, "b": 2}'
可以看出来string和js的区别在于引号。
对于可以作为json.loads()参数对象的字符串,除了要满足字典类型的格式外,所有的字符串对象必须是双引号。
size & shape IN torch & numpy
import numpy as np
data = np.array([[1,2,3],[1,2,3]])
print(data)
print(data.shape) # 矩阵的size
print(data.size) # 元素个数
--- result for numpy ----
--> [[1 2 3]
[1 2 3]]
--> (2, 3)
--> 6
----------------
import torch
dataInTensor = torch.rand(2,3) #注意这里不是输入一个list 哦,参数列表是*args
print(data)
print(data.shape) '''注意,返回torch.Size 也是一个Tensor类型!'''
print(data.size( ) ) '''注意,这里size不是一个attr 是一个func了!'''
--- result for torch ----
--> tensor([[0.1778, 0.0355, 0.0338],
[0.7351, 0.1348, 0.5127]])
--> torch.Size([2, 3])
--> torch.Size([2, 3])
----------------
tensor.shape 和 tensor.size() 得到的是一个结果(也都是tensor类型的)
numpy只有shape属性和size属性
vars( Object )和dir( Object )
- refer
- var以dict方式打印 属性和方法 以及其取值
- dir只打印其属性
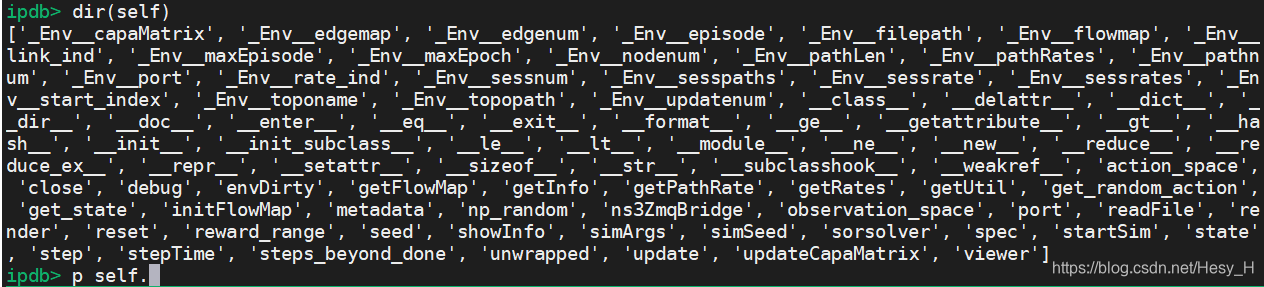
- 在ns3-gym里面经常是debug的时候发现得dir(self),没法儿直接dir(Env)
numexpr 加速
reference: numexpr:你以为 numpy 已经够快了,其实它还可以更快
- numpy底层OP是用C加速的
- numexpr比numpy中C实现的操作还要快,且计算逻辑越复杂加速效果越好
- pandas是基于numpy写的,numexpr也可以加速pandas且效果良好

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









