




 本文深入介绍了PyTorch的自动求导功能及其在神经网络训练中的应用,包括反向传播算法的基本原理、自动求导的具体实现方式及注意事项。
本文深入介绍了PyTorch的自动求导功能及其在神经网络训练中的应用,包括反向传播算法的基本原理、自动求导的具体实现方式及注意事项。
pytorch 的自动求导功能简介
自动求导是 pytorch 的一项重要功能,它使得 pytorch 能够灵活快速地构建神经网络模型。反向传播算法是优化神经网络模型参数的一个重要方法,在反向传播过程中需要不断计算损失函数对参数的导数,然后更新相应的模型参数,首先简单介绍一下反向传播算法。
一、反向传播算法简介
这部分的主要参考资料来自这里:https://www.cnblogs.com/charlotte77/p/5629865.html,原文的计算过程非常详细,有需要可以去阅读原文,另外原文中有一处疏漏之处,就是也需要计算损失函数对偏置量 b 1 b_1 b1、 b 2 b_2 b2的导数并且更新偏置量。
回到正题,对于一个典型的神经网络模型,如下所示:
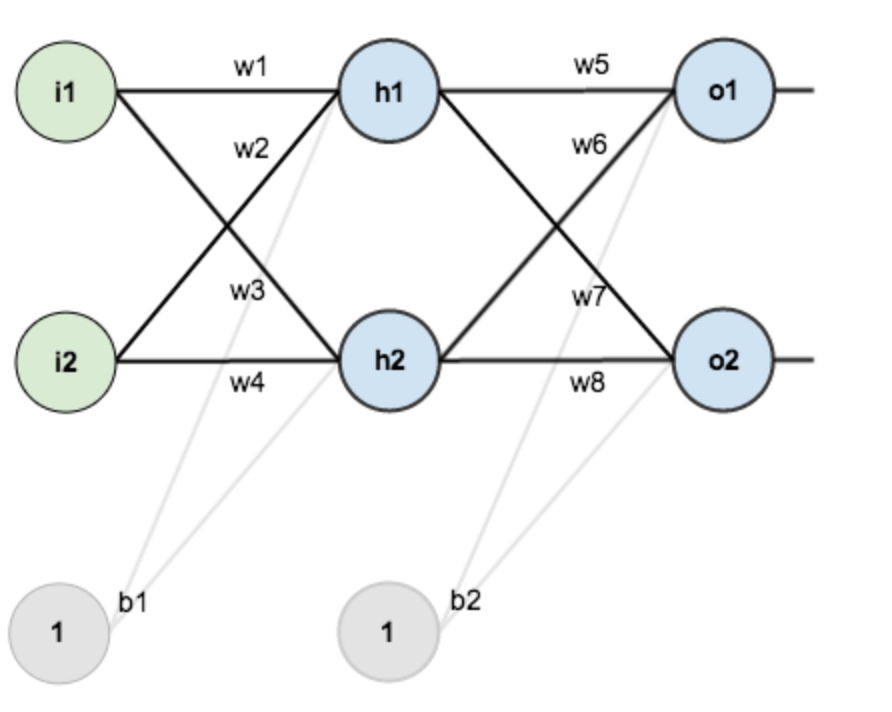
我们可以将它看作是一个映射( F \mathscr{F} F),即是从输入向量 [ i 1 , i 2 ] [i1, i2] [i1,i2]到输出向量 [ o 1 , o 2 ] [o1, o2] [o1,o2]之间的映射,而这个映射关系完全是由网络的连接关系和w1-w8、b1、b2这些参数决定的。在模型的训练过程中,输入和输出数据是固定的,我们要做的是调节这些控制参数来使得通过神经网络计算的输出与实际输出的误差达到最小,误差的具体形式通过损失函数( L \mathscr{L} L)来定义,由于输入和输出数据是固定的,同时在网络结构固定的情况下,损失函数( L \mathscr{L} L)仅是w1-w8、b1、b2这些控制参数的函数,神经网络的优化过程用公式表达就是:
f i n d w 1 0 − w 8 0 , b 1 0 , b 2 0 s t L 0 ( w 1 0 − w 8 0 , b 1 0 , b 2 0 ) = m i n L ( w 1 − w 8 , b 1 , b 2 ) find \quad w1_0-w8_0,b1_0,b2_0 \quad st \\ \mathscr{L}_0(w1_0-w8_0,b1_0,b2_0) = min\mathscr{L}(w1-w8, b1, b2) findw10−w80,b10,b20stL0(w10−w80,b10,b20)=minL(w1−w8,b1,b2)
反向传播过程就是通过不断计算损失函数( L \mathscr{L} L)对w1-w8、b1、b2这些控制参数的导数,根据梯度下降法的原理,更新参数,使得损失函数( L \mathscr{L} L)向着减小的方向优化,优化完成即代表损失函数达到最小。
需要注意的一点是,在网络参数优化过程中,我们是通过损失函数( L \mathscr{L} L)对控制参数求梯度来优化的,而不是通过网络模型( F \mathscr{F} F)对控制参数求梯度,损失函数( L \mathscr{L} L)是一个标量函数,而网络模型( F \mathscr{F} F)通常是一个向量函数,我们说的求梯度是对多变量的标量函数求梯度,参数的更新方法用公式可以表达为:
[ w 1 , … , w 8 , b 1 , b 2 ] = [ w 1 , … , w 8 , b 1 , b 2 ] − α [ ∂ L ∂ w 1 , … , ∂ L ∂ w 8 , ∂ L ∂ b 1 , ∂ L ∂ b 2 ] [w1, \dots, w8, b1, b2] = [w1, \dots, w8, b1, b2] - \alpha[\frac{\partial{\mathscr{L}}}{\partial{w1}}, \dots, \frac{\partial{\mathscr{L}}}{\partial{w8}}, \frac{\partial{\mathscr{L}}}{\partial{b1}}, \frac{\partial{\mathscr{L}}}{\partial{b2}}] [w1,…,w8,b1,b2]=[w1,…,w8,b1,b2]−α[∂w1∂L,…,∂w8∂L,∂b1∂L,∂b2∂L]
其中 α \alpha α为学习率。
一个完整的神经网络训练过程可以总结以下两步循环进行:
- 前向传播:计算在当前参数下,带入输入数据后模型的输出
- 反向传播:计算损失函数对网络各个控制参数的梯度,然后更新控制参数。这里要注意的是由于一些参数前后有耦合关系,因此在某些求导中需要用到链式法则。
二、pytorch 的自动求导功能
pytorch 能够自动求导,这为构建神经网络提供了很大的方便。以下的内容大部分都翻译自 pytorch 官方的内容:https://pytorch.org/tutorials/beginner/introyt/autogradyt_tutorial.html,部分有所改动,以官网为准。
1. 前言
pytorch 的自动求导特征使得其能够快速灵活地构建机器学习项目,在复杂的计算中它能够快速且容易地计算多变量偏导数(梯度),在基于反向传播的神经网络模型中这一操作是核心。
pytorch 的自动求导能力来自于在程序运行过程中,它会动态地追踪你的计算,这意味着如果你的模型有条件分支,或者循环的步数在程序运行之前是未知的,它同样能够正确地追踪计算,你能够得到正确的结果来继续学习过程,所有的这些,结合你建立在 python 之上的模型,相比于传统的用于计算梯度的固定结构,能够提供一个更加灵活的框架。
2. 我们需要自动求导机制做什么
机器学习模型是一个有输入和输出的函数,在这个讨论中,我们将把输入看作是一个i维的向量 x ⃗ \vec{x} x,其中的元素写作 x i x_i xi。我们可以把模型写作M,它是关于输入的一个向量函数: y ⃗ = M ⃗ ( x ⃗ ) \vec{y}=\vec{M}(\vec{x}) y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2711
2711


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








