







文章目录
ROUGE: A Package for Automatic Evaluation of Summaries
上一篇中的BLEU是用于文本翻译任务的,主要基于n-grams的方法,评测是以准确率为主要的指标。
这篇是面向文本摘要任务,基于同义词、词序的overlap方法,评测以recall为主。
introduction
首先先介绍了summary关注的的几个方面:连贯性、简洁性、语法性、可读性和内容(Mani,2001)。
conherence/conciseness/grammatically/readaility/content.
在以往的方法中,提到了基于content的方法,包括cos相似度、unit overlap、longest common subsequence.
However they did not show how the result of these automatic evaluation methods correlated to human judgements.
基础模型
Rouge-N

Rouge_Nmulti
当multiple references被使用时,计算每个reference和candidate之间的Rouge 分值,然后取最大值作为最终这一candidate的分值。
在计算最终的Rouge_N的分值时,采用所有的candidate的平均值作为最终值。
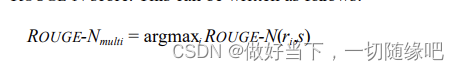
ROUGE-L: Longest Common Subs equence
1Sentence-level LCS
LCS :longest common sequence.
基于LCS的评测,是计算precision、recall、f1分值。
两个summary之间的相似值。
summary X:length=m
summary Y:length=n
对应的P、R和F分值计算为:
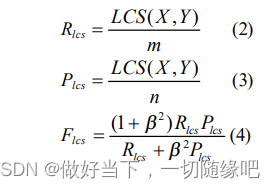
ß = Plcs/Rlcs
The disadvantages that it only counts the main in-sequence words; therefore the other alternative LCSes and the shortest sequences are not reflected in the final score.
2Summary-Level LCS
当candidate summary中有n个sentences时,计算这n个sentence和一个summery sentence的longest sequence score

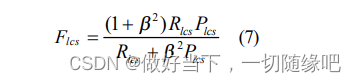
ROUGE-W: Weighted Longest Common Subsequence
β=Plcs/Rlcs

ROUGE-S: Skip-Bigram Co-Occurrence Statistics
police killed the gunman 对应的skip bi-grams有
(“police killed”, “police the”, “police gunman”,
“killed the”, “killed gunman”, “the gunman”)
在计算时,采用计算方法:
C(m,2)是所有全排的数量。
X reference,Y candidate

匹配和词序有一定的关联性。
可能会存在虚假匹配,比如,the the、of in 这种,文中提出的解决方式,限制skip distance的最大距离。
ROUGE-SU: Extension of ROUGE-S
当两个句子的词的顺序完全相反时,Rouge_S 的计算分值是0,但是这不太合理,提出了Rouge_SU。它是在Rouge_S的基础上加上了unigram作为计算单元????
We can also obtain ROUGE-SU from ROUGE-S by adding a begin-of-sentence marker at the beginning of candidate and reference sentences
在评估这个metric方法好坏时,采用的皮尔逊相关性。评价和人类评级分值的相关性。

结论
变量条件:
single summary
multi-document summary
short summary
exclusion of stopwords
multiple references
(1) ROUGE-2, ROUGE-L, ROUGE-W, and
ROUGE-S worked well in single document summarization tasks,
(2) ROUGE-1, ROUGE-L, ROUGE-W, ROUGE-SU4, and ROUGE-SU9 performed great in evaluating very short summaries (or headline-like
summaries)
(3) correlation of high 90% was hard to
achieve for multi-document summarization tasks but ROUGE-1, ROUGE-2, ROUGE-S4, ROUGE-S9, ROUGE-SU4, and ROUGE-SU9 worked reasonably well when stopwords were excluded from matching,
(4) exclusion of stopwords usually improved correlation, and
(5) correlations to human judgments were increased by using multiple references.
总结
这两篇文章都是先从“指标项”开始的,比如translation更关注什么指标?summary关注什么指标?一致性、流畅性等等。
上一篇是bi-grams
这一篇是:P/R/F,longest common sequence
有一个核心假设,比如,相同的公共子序列越长,则效果越佳。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











