




Domain Adaptation for Deep Entity Resolution
摘要
实体解析(ER)是数据集成的一个核心问题。ER的最先进(SOTA)结果是通过基于深度学习(DL)的方法实现的,使用大量标记匹配/非匹配实体对进行训练。当使用准备良好的基准数据集时,这可能不是一个问题。然而,对于许多真实世界的ER应用程序,情况发生了巨大的变化,收集大规模标记数据集是一个痛苦的问题。在本文中,我们试图回答:如果我们有一个标记良好的源ER数据集,我们能否为一个没有任何标签或有一些标签的目标数据集训练一个基于DL的ER模型?(If we have a well-labeled source ER dataset, can we train a DL-based ER model for a target dataset, without any labels or with a few labels?)这被称为领域适应(DA),它在计算机视觉和自然语言处理方面取得了巨大的成功,但尚未对ER进行系统的研究。我们的目标是系统地探索广泛的DA方法( wide range of DA methods for ER)对ER的好处和局限性。为此,我们开发了一个DADER(深度实体解析的领域适应(Domain Adaptation for Deep Entity Resolution))框架,该框架显著提高了在应用DA方面的ER。我们为DADER的三个模块,即特征提取器、匹配器和特征对齐器,定义了一个设计解决方案(define a space of design solution)的空间。我们进行了迄今为止最全面的实验研究,以探索设计空间,并比较不同的DA的选择。我们根据广泛的实验,为选择合适的设计方案提供指导。
Feature Extractor 特征提取器
Matcher 匹配器
Feature Aligner 特征对齐器
1 Introduction
实体解析(ER)确定两个数据实例是否引用同一个真实世界的实体。经过几十年以模型为中心的研究,已经有相当数量的文献,包括基于规则的方法(例如,析取范式[59]和一般布尔公式[59]),基于ML的方法(如SVM[5]和随机森林[20]),基于DL的方法(如DeepMatcher[49],DeepER[21]和Ditto[42])。最先进的(SOTA)结果是通过基于DL的解决方案实现的。
然而,基于DL的ER方法通常需要大量的标记训练数据。例如,即使通过使用Ditto[42]等预训练的语言模型,仍然需要成千上万的标签来达到令人满意的准确性。事实上,ER practitioners的主要痛点是,他们需要大量的标签努力来创建足够的训练数据。
幸运的是,大数据时代使得许多标记的ER数据集可以在相同或相关领域使用,无论是从公共基准(例如WDC[52]和DBLP-Scholar[49]),还是在企业内部。因此,一个自然的问题是:我们能否重用这些标记的源ER数据集用于新的目标ER数据集?对上述问题的肯定回答有可能显著减少数据标记的人力成本。
Domain adaptation
重用已标记的源数据的关键挑战是,在源数据和目标之间可能会发生分布变化或域转移(domain shift),这将降低性能。( The key challenge of reusing labeled source data is that there may be distribution change or domain shift between the source and the target, which would degrade the performance.)
源数据集:labeled Source
目标数据集:unlabeled Target

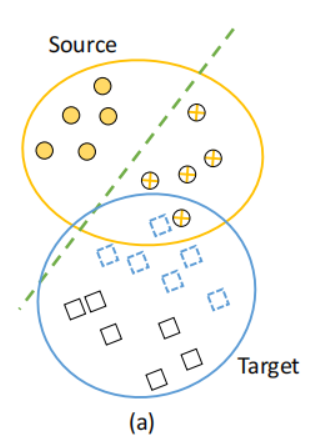
图1(a)显示了一个labeled source数据集(圆圈)和一个unlabeled target数据集(正方形)的示例。由于源数据集和目标数据集可能不来自同一个域(domain),因此它们不遵循相同的分布。因此,从源中训练出来的ER模型(绿色虚线)不能正确地预测目标。
在Source中训练得到的分类器,直接应用于Target,很难准确。通俗点说,同样的一条线,可以将圆圈一分为二,却很难将正方形一分为二。
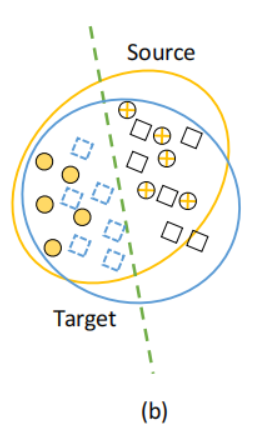
为了解决这一挑战,领域自适应(DA)得到了广泛的研究,即将一个或多个相关源域中的标记数据用于目标域[25,45,64,69]中的新数据集。直观地说,DA是从数据实例中学习,寻找对齐源和目标数据分布的最佳方法,如此一来,在labeled source上训练的模型就可以被使用在(或适应于)unlabeled target。如图1(b)所示,DA的优势是能够学习更多的域不变(domain-invariant)表示,减少源和目标之间的域转移(domain shift),并提高ER模型的性能,例如,绿线可以正确分类在源和目标数据集中的数据实例。
然而,尽管最近进行了一些尝试,但据我们所知,在ER中采用DA并没有在同一框架下进行系统的研究,因此从业者很难理解DA对ER的好处和局限性。为了弥补这一差距,本文引入了一个通用框架,称为DADER(Deep ER的领域适应),它统一了DA解决方案[73,74]的广泛选择。具体来说,该框架由三个主要模块组成。
(1)特征提取器(Feature Extractor)将实体对转换为高维向量(high-dimensional vectors)(又叫做features)
(2)匹配器(Matcher)是一种二元分类器,它以实体对的特征作为输入,并预测它们是否匹配。
(3)特征对齐器(Feature Aligner)是domain adaptation的关键模块,旨在缓解域偏移(domain shift)的影响。为了实现这一点,特征对齐器调整特征提取器,以对齐源和目标ER数据集的分布,从而减少源和目标之间的域偏移(domain shift)。此外,它还对匹配器进行了相应的更新,以最小化调整后的特征空间中的匹配误差(minimize the matching errors in the adjusted feature space)。
Design space exploration
在此框架的基础上,我们系统地分类和研究了DA中最具代表性的方法,并重点研究了两个关键问题。
问题1
DA是机器学习(如计算机视觉和自然语言处理)中的一个广泛的主题,并且有大量的领域自适应的设计选择( large set of design choices)。因此,有必要提出一个问题,即哪些设计选择有助于ER。为了回答这个问题,我们广泛回顾了现有的DA研究,然后重点关注最流行和最丰富的方向。在此基础上,我们对DADER中的每个模块进行了分类,并通过总结具有代表性的DA技术来定义一个设计空间(design space)。具体来说
-
特征提取器通常由递归神经网络[38]和预训练语言模型[19,44,55]来实现。
-
匹配器通常采用深度神经网络作为二值分类器。
-
特征对齐器由三类解决方案实现:(1)基于差异,(2)基于对抗,以及(3)基于重建。
由于特征提取器和匹配器的具体选择已经得到了充分的研究,我们的重点是识别特征对齐器的方法,为此我们开发了六种具有代表性的方法,涵盖了广泛的SOTA DA技术。
问题2
DA是否有助于ER,去利用相关领域的labeled data。为了解决这个问题,本文考虑了两种设置:
(1)没有任何target labels的无监督DA设置
(2)有一些target labels的半监督DA设置。
此外,我们还比较了DADER和ER的SOTA DL解决方案,如DeepMatcher[49]和Ditto[42]。在此基础上,我们对DA对ER的优缺点进行了综合分析。
Contributions
(1)据我们所知,我们是第一个正式定义DA for deep ER(第3节),并对迄今为止将DA应用于ER进行了最全面的研究。
(2)我们介绍了一个支持DA for ER的DADER框架,它由三个模块组成,即特征提取器、匹配器和特征对齐器。我们通过对框架中的每个模块进行分类,系统地探索了ER的DA设计空间(第4节)。特别地,我们开发了六种具有代表性的特征对齐器的方法(第5节)。
(3)我们进行了一个彻底的评估,以探索设计空间,并比较所开发的方法(第6节)。源代码和数据已经在Github上提供。我们发现DA对于ER非常有前途,因为它减少了源和目标之间的domain shift。我们指出了DA对ER的一些开放问题,并确定了研究方向(第8节)。
Github地址:https://github.com/ruc-datalab/DADER
2 Deep Entity Resolution
我们正式定义了实体解析,并提出了一个使用深度学习进行实体解析(或简称Deep ER)的框架。
Entity resolution
设𝐴和𝐵是两个具有多个属性的关系表。每个元组𝑎∈𝐴(或𝑏∈𝐵)也被称为由一组attribute-value对{ (attri,vali)}1≤i≤k\left\{\left(\operatorname{attr}_{i}, \operatorname{val}_{i}\right)\right\}_{1 \leq i \leq k}{ (attri,vali)}1≤i≤k组成的实体,其中,attr𝑖和val𝑖分别表示第𝑖个属性的名称和值。实体解析(ER)的问题是找到所有引用相同真实世界对象的实体对(𝑎,𝑏)∈𝐴×𝐵。如果它们引用了相同(不同的)现实世界中的对象,一个实体对就说是匹配的(不匹配),。
一个典型的ER管道包括两个步骤,阻塞(blocking)和匹配(matching)。阻塞步骤生成一组具有高召回率(high recall)的候选对,即修剪不太可能匹配的实体对(参见DL for ER blocking[67])。
匹配步骤将从阻塞步骤中生成的候选集作为输入,并确定哪些候选对是匹配还是不匹配。我们的重点是ER匹配步骤的域自适应。
Training data for ER
我们将一个labeled training set表示为(D,Y)({D}, \mathcal{Y})(D,Y),其中,D⊂A×B{D} \subset A \times BD⊂A×B是一组实体对,Y\mathcal{Y}Y是一个标签集。
每个实体对(𝑎,𝑏)∈D(𝑎,𝑏)∈D(a,b)∈D与一个标签𝑦∈Y𝑦∈\mathcal Yy∈Y相关联,该标签𝑦∈Y𝑦∈\mathcal Yy∈Y表示实体对𝑎和𝑏是匹配(即𝑦=1)还是不匹配(即𝑦=0)。

图2(a)显示了一个示例训练集。每对都由来自不同表的两个实体组成,例如(a1S,b1S)\left(a_{1}^{S}, b_{1}^{S}\right)(a1S,b1S),并与一个1/0的label相关联
Deep entity resolution
现有的深度ER解决方案[21,42,49]通常使用一个由特征提取器和匹配器组成的框架,如图3(a)所示

具体来说,给定一个实体对(a,b)(a,b)(a,b),一个特征提取器F(a,b):A×B→Rd\mathcal{F}(a, b): A \times B \rightarrow \mathbb{R}^{d}F(a,b):A×B→Rd,将这对数据转换为基于𝑑维向量的表示(又称为features),用x表示,即x=F(a,b)\mathbf{x}={F}(a, b)x=F(a,b)
然后,将特征x输入ER Matcher MMM,这是一个基于DL的二元分类模型。ER匹配器M以特征x作为输入,并预测匹配的概率y^\hat{y}y^
y^=M(x)=M(F(a,b))(1) \hat{y}={M}(\mathbf{x})={M}({F}(a, b)) \qquad (1) y^=M(x)=M(F(a,b))(1)
给定一个训练集(D,Y)({D}, \mathcal{Y})(D,Y),通过迭代应用小批量随机梯度下降( iteratively applying minibatch stochastic gradient descent),对F和M的参数进行优化,从而区分匹配实体对和非匹配实体对
领域 (Domain) 是学习的主体, 主要由两部分构成: 数据和生成这些数据的概率分布。我们通常用 花体 D\mathcal{D}D 来表示一个领域, 领域上的一个样本数据包含输入 x\mathbf xx 和输出 yyy, 其概率分布记为 p(x,y)p(\mathbf x, y)p(x,y), 即数据服从这一分布: (x,y)∼p(x,y)(\mathbf x, y) \sim p(\mathbf x, y)(x,y)∼p(x,y) 。我们用大写花体 X,Y\mathcal{X}, \mathcal{Y}X,Y 来分别表示数据所处的特征空间和标签空间, 则对于任意一个样本 (xi,yi)\left(\mathbf x_{i}, y_{i}\right)(xi,yi), 都有 xi∈X,yi∈Y\boldsymbol{x}_{i} \in \mathcal{X}, y_{i} \in \mathcal{Y}xi∈X,yi∈Y 。因此, 一个领域可以被表示为 D={ X,Y,P(x,y)}\mathcal{D}=\{\mathcal{X}, \mathcal{Y}, P(\boldsymbol{x}, y)\}D={ X,Y,P(x,y)}
王晋东,陈益强著.迁移学习导论.电子工业出版社.2021:43.
Example 1
考虑图2(a).中的ER数据集,假设我们使用预训练的语言模型Bert[19]来实现特征提取器F,像Ditto[42]一样。给定一个实体𝑎𝑎a,F首先通过应用以下函数,将𝑎的所有属性-值对{
(attri,vali)}1≤i≤k\left\{\left(\operatorname{attr}_{i}, \operatorname{val}_{i}\right)\right\}_{1 \leq i \leq k}{
(attri,vali)}1≤i≤k序列化为一个标记序列(即文本)。其中,[ATT]和[VAL]分别starting属性和值的两个特殊token。
S(a)=[ATT]attr1[VAL]val1…[ATT]attrk[VAL]valk \mathcal{S}(a)=[\mathrm{ATT}] \operatorname{attr}_{1}[\mathrm{VAL}] \mathrm{val}_{1} \ldots [ATT] \operatorname{attr}_{k}[\mathrm{VAL}] \operatorname{val}_{k} S(a)=[ATT]attr1[VAL]val1…[ATT]attrk[VAL]valk
例如,我们将实体a1Sa_{1}^{S}a1S序列化为一个标记序列,即,S(a1S)={S}\left(a_{1}^{S}\right)=S(a1S)=[ATT] title [VAL] balt … [ATT] price [VAL]239.88
然后,FFF将(𝑎S,𝑏S)(𝑎^S,𝑏^S)(aS,bS)转换为标记序列
S(aS,bS)=[CLS]S(aS)[SEP]S(bS)[SEP] \mathcal{S} \left(a^{\mathrm{S}}, b^{\mathrm{S}}\right)= [\mathrm{CLS}] \mathcal{S}\left(a^{\mathrm{S}}\right)[\mathrm{SEP}] \mathcal{S}\left(b^{\mathrm{S}}\right)[\mathrm{SEP}] S(aS,bS)=[CLS]S(aS)[SEP]S(bS)[SEP]
其中,[SEP]是分隔两个实体的特殊token,而[CLS]是BERT中用于编码整个序列的特殊token
最后,我们将S(𝑎S,𝑏S)S(𝑎^S,𝑏^S)S(aS,bS)输入BERT,得到一个基于向量的表示x\mathbf xx(例如,[CLS]的嵌入)。然后,我们可以使用一个全连接层来实现匹配器MMM,然后从x\mathbf xx中产生匹配的概率y^\hat{y}y^
因此,给定图2(a)中所有标记的对{ (aS,bS,yS)}\left\{\left(a^{\mathrm{S}}, b^{\mathrm{S}}, y^{\mathrm{S}}\right)\right\}{ (aS,bS,yS)},我们可以通过最小化{ (yS,y^)}\left\{\left(y^{\mathrm{S}}, \hat{y}\right)\right\}{ (yS,y^)}上的一个损失函数来训练FFF和MMM。
3 Domain Adaptation For Deep ER
接下来,我们描述了针对deep ER的领域自适应。我们考虑一个 labeled source ER数据集(DS,YS)={ (aS,bS,yS)}\left({D}^{ {S}}, \mathcal{Y}^{ {S}}\right)=\left\{\left(a^{\mathrm{S}}, b^{\mathrm{S}}, y^{\mathrm{S}}\right)\right\}(DS,YS)={ (aS,bS,yS)}和一个unlabeled target数据集DT={ (aT,bT)}{D}^{T}=\left\{\left(a^{T}, b^{T}\right)\right\}DT={ (aT,bT)}
目的是寻找对目标DT{D}^{T}DT产生精确匹配/非匹配结果的最佳Feature Extractor和Matcher
一个粗糙的方法是直接使用DSD^SDS训练出的Feature Extractor FFF 和Matcher MMM ,来预测 DTD^TDT
但是,由于源数据和目标数据可能不来自同一个域,因此针对源数据和目标数据,由FFF提取的特征可能不遵循相同的数据分布,从而导致域移位(domain shift)问题。
因此,使用源数据训练的 MMM不能正确地预测目标数据。为了解决这一障碍,我们研究了ER的领域自适应问题,并引入了一个统一了代表性方法的框架DADER。
High-level idea of DA for ER
图3(b)显示了DADER框架
High-level的idea是从数据实例中学习——寻找生成(generating)和对齐(aligning)source和target实体对的特征的最佳方法,如此,在labeled source上训练的匹配器就可以使用在(或适应于)unlabeled target。
为此,DADER引入了一个 Feature Aligner A,它引导Feature Extractor F (特征对齐器)生成域不变的(domain-invariant)和判别(discriminative)的特征,并相应地更新Matcher M。在形式上,我们定义了对齐损失(alignment loss)和匹配损失(matching loss)如下:
(1) Domain-invariant(域不变性)
域不变性,直观地说,我们希望source features xS\mathbf{x}^{S}xS和target features的xT\mathbf{x}^{T}xT分布尽可能接近
为此目的, Feature Aligner A(xS,xT):Rd×Rd→R{A}\left(\mathbf{x}^{\mathrm{S}}, \mathbf{x}^{T}\right): \mathbb{R}^{d} \times \mathbb{R}^{d} \rightarrow \mathbb{R}A(xS,xT):Rd×Rd→R,被用于产生alignment loss LAL_{A}LA
例如, LAL_{A}LA的一个简单方法是定义源分布和目标分布均值之间的距离。第4节将讨论对实现的 LAL_{A}LA更全面的设计探索。
Define a distance between the means of source and target distributions
(2) Discriminative(判别)
我们还考虑了一个matching loss LML_MLM,用于衡量源数据集上,predicted和ground-truth结果之间的差异。回想一下,给定源数据集中的一个实体对(𝑎S,𝑏S)(𝑎^S,𝑏^S)(aS,bS),我们的Matcher M预测为y^=M(F(aS,bS))\hat{y}={M}\left({F}\left(a^{S}, b^{S}\right)\right)y^=M(F(aS,bS))。因此,matching loss(匹配损失) LML_MLM被定义为LM=loss({ (y^,yS)}){L}_{M}=\operatorname{loss}\left(\left\{\left(\hat{y}, y^{\mathrm{S}}\right)\right\}\right)LM=loss({ (y^,yS)}),其中loss是一个函数,例如交叉熵(cross entropy)。
现在,我们准备提出DA对ER的目标,即找到最佳的特征提取器F∗F^∗F∗和匹配器M∗M^∗M∗,以最小化对齐损失(alignment loss)L𝐴L_𝐴LA和匹配损失(matching loss)L𝑀L_𝑀LM,即
F∗,M∗=argminF,M aggregate (LA,LM). (2) {F}^{*}, {M}^{*}=\arg \min _{
{F}, {M}} \text { aggregate }\left({L}_{A}, {L}_{M}\right) \text {. } \qquad (2) F∗,M∗=argF,Mmin aggregate (LA,LM). (2)
在这里,aggregate是一个结合了这两个损失的函数,这是由各种特征对齐策略(feature alignment strategies)决定的。为了实现方程(2)中的目标,我们利用反向传播(back-propagation)来更新F和M的参数,如图3所示。通过这种方式,F可以改进,以产生跨Source和Target的域不变特征(domain-invariant features across source and target),而M可以相应地更新,以改进源和目标数据集上的ER匹配。
训练F,使得Source和Target数据集上提取到的特征尽可能的看不出差别
训练M,使得Matcher在源数据集上的匹配准确率提高—直接效果—(期待可以在目标数据集上也有较高的准确率)
注意,这种情况下,得到的在源数据集上的匹配准确率,相比于NoDA,有提高吗?按理说应该会下降,因此在对齐的过程中,也做出了一部分妥协,对齐的一个目的是使得模型学习到两个Domain之间的相似性并做迁移,相似性学到了,那么损失了特有的一些信息。
之后,M和F都可以在目标数据集上使用。具体来说,给定每个目标实体对(𝑎T,𝑏T)(𝑎^T,𝑏^T)(aT,bT),它们可以一起进行,做出预测M(F(𝑎T,𝑏T))M(F(𝑎^T,𝑏^T))M(F(aT,bT))
Example 2
考虑图2中的示例。假设F将源(即圆)和目标(即正方形)中的实体对映射到一个二维空间,如图1(a).所示。然后,我们可以看到一个在源数据集和目标数据集之间的域转移(domain shift)的例子。
将entity pairs映射到2-dimensional space如何理解:降维

这可能是因为F非常关注在源数据集但不在目标数据集内的特定属性,例如category和brand。因此,Matcher M(即虚线)并不直接适合于DT,并且对所有的目标实体对(Target entity pairs)产生non-match的结果。
对所有的目标实体对(Target entity pairs)产生non-match的结果,指的是图1中的(a)中,对于Source,虚线一侧为匹配,另一侧为不匹配,对于Target而言,所有的Target entity pairs对应的结果,全在虚线的一侧。
为解决这个问题,引入特征对齐器A(Feature Aligner)来实现以下两个目标:
(1)调整F,以对齐源和目标实体对的分布,例如,充分利用共享属性(shared attributes)
(2)与之相应地更新M,以在新生成的特性空间(newly generated feature space)减少匹配错误。
在此基础上,A使更新后的F和M产生更准确的ER结果,如图1(b)所示。
为了更好地说明,我们还在第6.2.1节中提供了几个关于实验数据集的真实例子
Remarks
请注意,领域适应是机器学习中一个广泛的话题,并且在CV和NLP中都取得了巨大的成功(参见最近的调查显示,[73,74])。在我们的ER场景中,我们采用了最流行和富有成果的domain adaptation技术家族,即学习domain-invariant特征和discriminative特征[25,45,69]。然而,domain adaptation有更大的选择集,本文没有涉及许多DA技术,如生成伪标签
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











