



 本文介绍了二分类模型性能评估的两种常用方法——PR曲线和ROC曲线。PR曲线通过绘制精度和召回率的关系,关注正例预测性能;ROC曲线绘制真阳性率和假阳性率的关系,更全面考虑正负类样本分类表现。还给出了相关计算及代码实现,可助于选择最优模型。
本文介绍了二分类模型性能评估的两种常用方法——PR曲线和ROC曲线。PR曲线通过绘制精度和召回率的关系,关注正例预测性能;ROC曲线绘制真阳性率和假阳性率的关系,更全面考虑正负类样本分类表现。还给出了相关计算及代码实现,可助于选择最优模型。
一、PR曲线
1.什么是PR曲线
PR曲线是评估二分类模型性能的一种常用方法,通过绘制在不同阈值下精度(precision)和召回率(recall)之间的曲线,帮助我们可视化地了解模型的性能。
精度(precision)是模型预测为正类的样本中,真正例的比例。精度越高,模型预测的正类样本中真正例的比例就越大,当精度为1时,表示所有被预测为正类的样本都是真正例,即没有假正例存在。
召回率(recall)是所有真正例中,被模型预测为正类的样本的比例。召回率越高,模型能够正确识别出更多的正类样本,当召回率为1时,表示所有真正例都被正确预测为正类,即没有假反例存在。
在二分类问题中,模型预测结果可以分为正类(positive)和负类(negative),其中正类可能是我们关注的事件或状态,负类则是我们不关注的事件或状态。模型将所有样本预测为正类或负类,会得到4种情况:真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)。其中,真正例表示模型正确地将样本分类为正类,假正例表示模型错误地将样本分类为正类,真反例表示模型正确地将样本分类为负类,假反例表示模型错误地将样本分类为负类。
2.混淆矩阵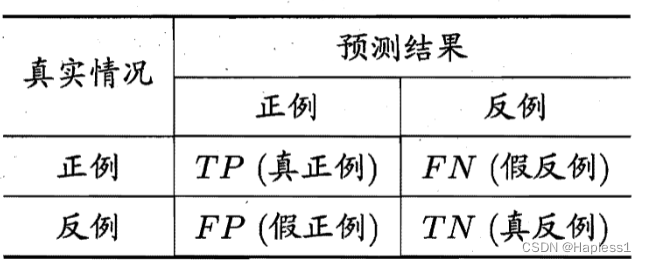
TP:被正确划分为正例的个数,即实际为正例且被分类器划分为正例的样例数
FP:被错误地划分为正例的个数,即实际为反例但被分类器划分为正例的样例数
FN:被错误地划分为反例的个数,即实际为正例但被分类器划分为反例的样例数
TN:被正确划分为反例的个数,即实际为反例且被分类器划分为反例的样例数
举例: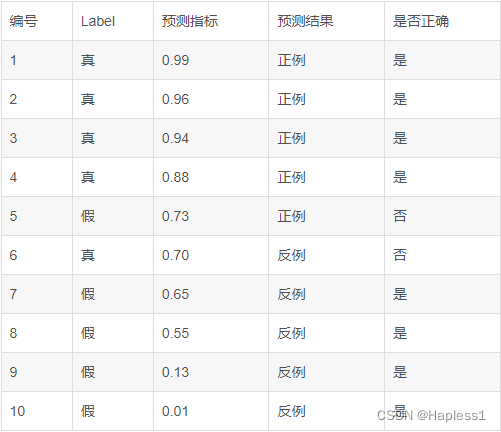
以上表格混淆矩阵为: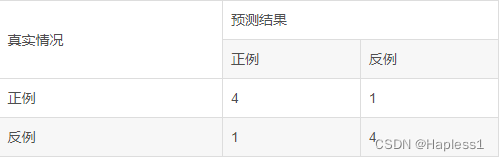
3.计算PR曲线的各个点
精度(precision): 召回率(recall):
召回率(recall):
以上混淆矩阵的PR值:
P=TP/(TP+FP)=4/(4+1)=0.8
R=TP/(TP+FN)=4/(4+1)=0.8
4.代码实现:
import matplotlib.pyplot as plt
# 随机生成测试数据集和模型预测结果
y_true = [0, 1, 1, 0, 1, 0, 1, 0]
y_pred = [0.2, 0.7, 0.8, 0.4, 0.5, 0.3, 0.6, 0.1]
# 计算精度和召回率,生成PR曲线数据
thresholds = sorted(set(y_pred), reverse=True)
precision_values = []
recall_values = []
for threshold in thresholds:
y_pred_binary = [1 if pred >= threshold else 0 for pred in y_pred]
true_positives = sum([1 for yt, yp in zip(y_true, y_pred_binary) if yt == 1 and yp == 1])
predicted_positives = sum(y_pred_binary)
actual_positives = sum(y_true)
precision = true_positives / predicted_positives if predicted_positives > 0 else 0
recall = true_positives / actual_positives if actual_positives > 0 else 0
precision_values.append(precision)
recall_values.append(recall)
# 按精度从高到低排序
precision_values, recall_values = zip(*sorted(zip(precision_values, recall_values), reverse=True))
# 绘制PR曲线
plt.figure()
plt.plot(recall_values, precision_values)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('PR Curve')
# 显示曲线
plt.show()
5.运行结果: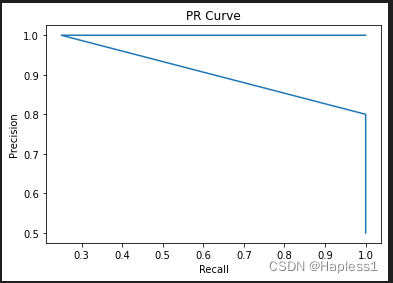
二、ROC曲线
1.什么是ROC曲线
ROC 曲线(Receiver Operating Characteristic curve)通过绘制不同分类阈值下的真阳性率(True Positive Rate,即召回率)和假阳性率(False Positive Rate)之间的关系曲线来展示模型在不同阈值下的表现。绘制 ROC 曲线时,我们将 FPR 放在横轴上,TPR 放在纵轴上。ROC 曲线将展示 TPR 和 FPR 之间的关系。一条优秀的 ROC 曲线将尽可能地靠近左上角,表示高的 TPR 和低的 FPR。
除了 ROC 曲线,我们还可以通过计算曲线下面积(Area Under Curve,AUC)来评估模型性能。AUC 的取值范围在 0.5 到 1 之间,越接近 1 表示模型性能越好,越接近 0.5 表示模型预测能力较弱。
真阳性率(TPR)表示模型将正样本正确分类为正类的比例。
假阳性率(FPR)表示模型将负样本错误分类为正类的比例。
2.计算公式
真阳率: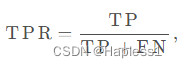 假阳率:
假阳率:
3.代码实现
import matplotlib.pyplot as plt
# 随机生成测试数据集和模型预测结果
y_true = [0, 1, 1, 0, 1, 0, 1, 0]
y_pred = [0.2, 0.7, 0.8, 0.4, 0.5, 0.3, 0.6, 0.1]
# 计算TPR和FPR,生成ROC曲线数据
fpr_values = []
tpr_values = []
for threshold in thresholds:
y_pred_binary = [1 if pred >= threshold else 0 for pred in y_pred]
true_positives = sum([1 for yt, yp in zip(y_true, y_pred_binary) if yt == 1 and yp == 1])
false_positives = sum([1 for yt, yp in zip(y_true, y_pred_binary) if yt == 0 and yp == 1])
actual_positives = sum(y_true)
actual_negatives = len(y_true) - actual_positives
tpr = true_positives / actual_positives if actual_positives > 0 else 0
fpr = false_positives / actual_negatives if actual_negatives > 0 else 0
tpr_values.append(tpr)
fpr_values.append(fpr)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr_values, tpr_values)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
# 显示曲线
plt.show()
4.运行结果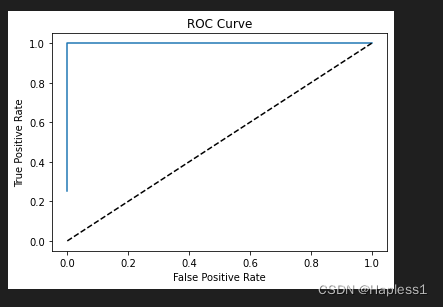
三、总结
PR 曲线和 ROC 曲线都是常用的二分类模型性能评估工具,用于可视化模型性能并帮助我们选择最优的阈值。
PR 曲线(Precision-Recall curve)主要关注的是模型在正例预测方面的性能,它将模型的精度(Precision)和召回率(Recall)之间的关系展示出来。PR 曲线上横轴是召回率,纵轴是精度。当正样本比例较低或者我们更关注模型在正类样本识别方面的性能时,PR 曲线是一种更好的评估工具。在不同的分类阈值下,我们通过计算模型的精度和召回率来绘制 PR 曲线。PR 曲线越靠近右上角,表示模型的性能越好。
ROC 曲线(Receiver Operating Characteristic curve)则是一个更加全面的性能评估工具,同时考虑了模型在正类与负类样本分类上的表现。ROC 曲线上横轴是假阳性率,纵轴是真阳性率,每个点表示在不同的分类阈值下模型的假阳性率与真阳性率。ROC 曲线越靠近左上角,表示模型的性能越好。
在模型选择中,我们可以通过比较不同模型或同一模型在不同参数设置下的 PR 曲线或 ROC 曲线,来判断哪一个模型具有最好的性能。如果我们更关注正类样本识别的准确率,可以选择 PR 曲线;如果要全面考虑分类准确度,那么 ROC 曲线是更为合适的选择。


















 2620
2620



 到【灌水乐园】发言
到【灌水乐园】发言








