







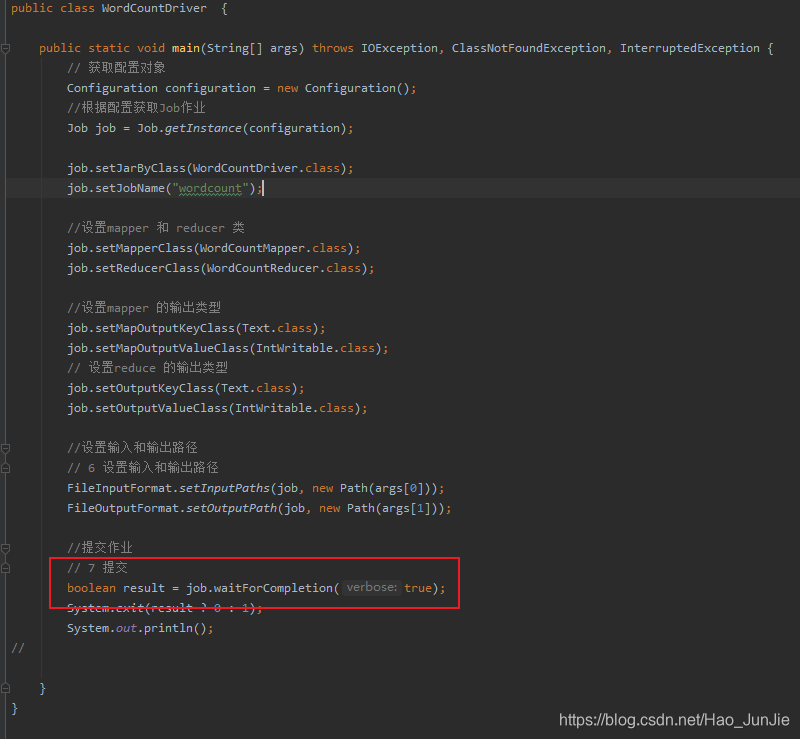
下图是wordCount驱动类,从源码方式看它是如何进行提交的
进入waitForCompletion 方法之后
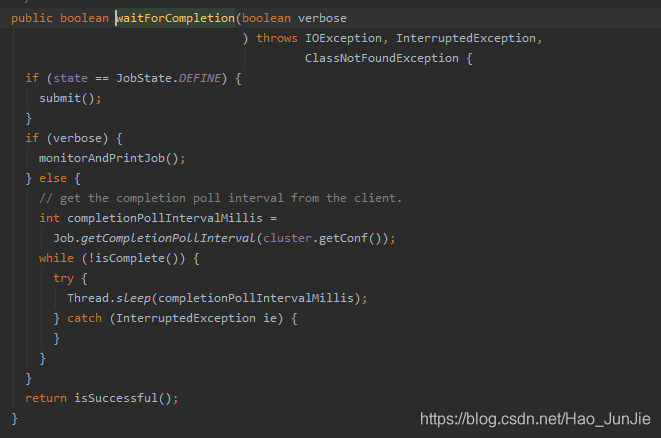
当state为DEFINE 进行submit() 进行提交
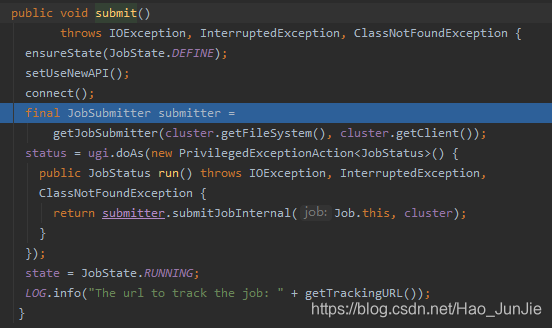
ensureState(JobState.DEFINE):确保job的状态为DEFINE
setUSerNewAPI(); 使用新的API
connect() 建立连接:是提交到YARN集群还是Local 如下图:
进入connect() 方法
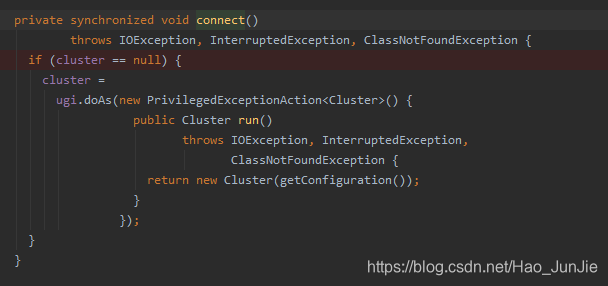
返回Cluster对象:return new Cluster(getConfiguration())
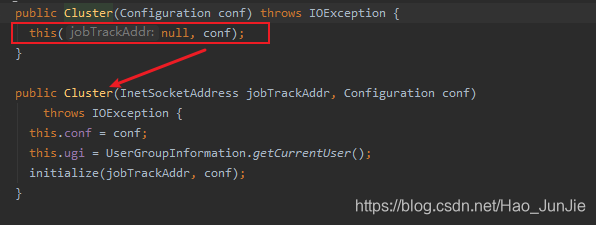
Cluster 调用initialize(jobTrackAddr,conf)
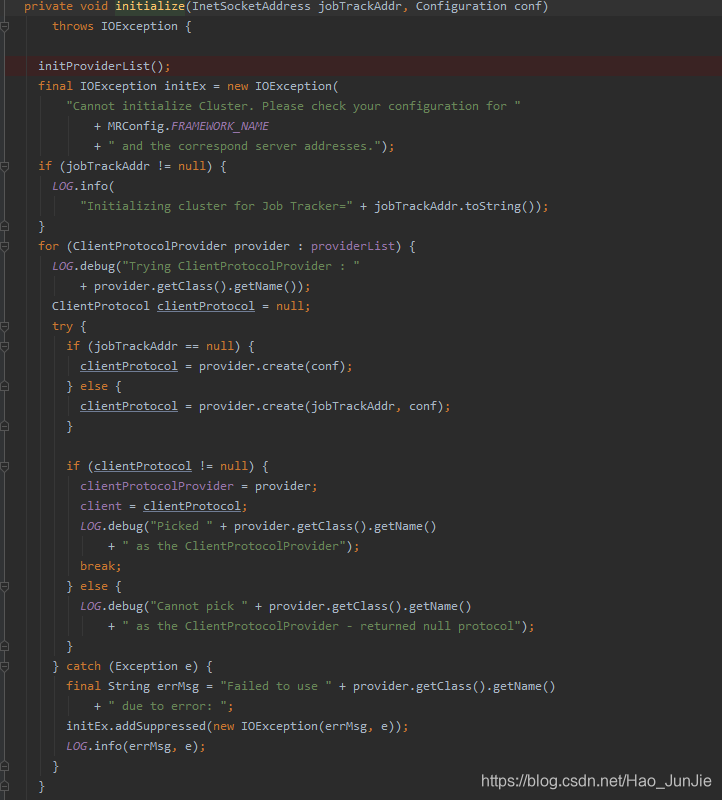
调用 initProviderList(); 初始化提交者
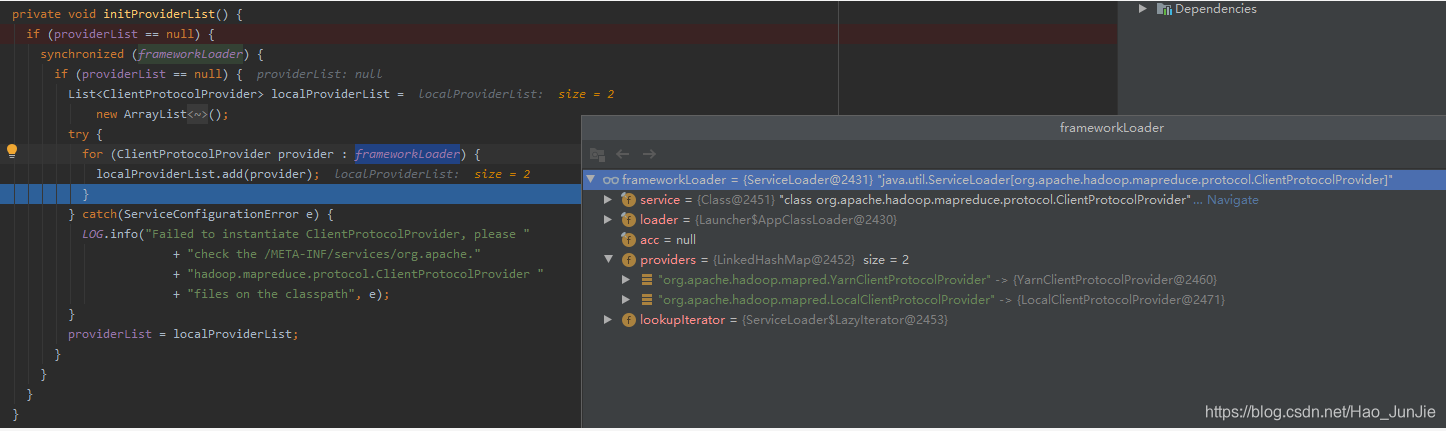
providerList 值为:YarnClientProtocolProvider 和 LocalClientProtocolProvider
继续图六:
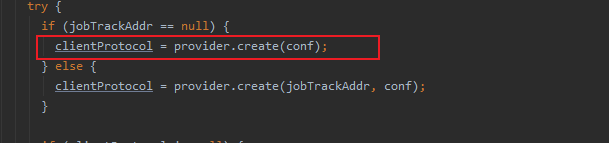
进入create(conf)方法 (是个抽象方法)
Yarn的实现:

本地的实现:
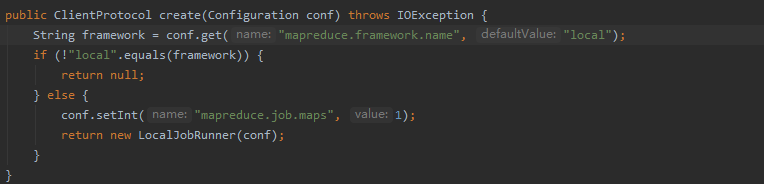
如果连接的是Yarn集群 clientProtocol就是 YARNRunner 如果连接的是local clientProtocol就是LocalJobRunner
connect() 方法结束后
进行提交 submitJobInternal(Job.this,cluster):如下代码:截图放不下,改成代码段
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









