




sqlalchemy查询 一天内的数据
最新推荐文章于 2024-06-10 13:08:00 发布
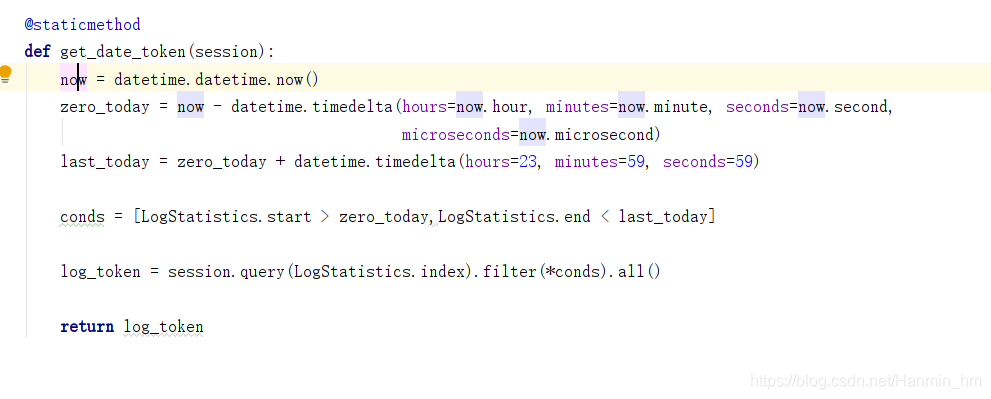
 该博客围绕SQLAlchemy查询一天内的数据展开,虽未给出具体内容,但可知聚焦于利用SQLAlchemy这一工具进行特定时间范围的数据查询操作,属于后端开发中数据库查询相关内容。
该博客围绕SQLAlchemy查询一天内的数据展开,虽未给出具体内容,但可知聚焦于利用SQLAlchemy这一工具进行特定时间范围的数据查询操作,属于后端开发中数据库查询相关内容。
该博客围绕SQLAlchemy查询一天内的数据展开,虽未给出具体内容,但可知聚焦于利用SQLAlchemy这一工具进行特定时间范围的数据查询操作,属于后端开发中数据库查询相关内容。
该博客围绕SQLAlchemy查询一天内的数据展开,虽未给出具体内容,但可知聚焦于利用SQLAlchemy这一工具进行特定时间范围的数据查询操作,属于后端开发中数据库查询相关内容。
 1110
1943
1823
3546
1110
1943
1823
3546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























