




 该博客讨论了一种在二叉树中寻找节点值之和等于给定整数的路径的方法。利用深度优先遍历(DFS),从根节点开始递归地搜索所有可能的路径。当路径的节点值之和等于目标整数时,将该路径保存。最终返回所有满足条件的路径。题目与二叉树的前序遍历有关,但需要在遍历过程中检查路径和。
该博客讨论了一种在二叉树中寻找节点值之和等于给定整数的路径的方法。利用深度优先遍历(DFS),从根节点开始递归地搜索所有可能的路径。当路径的节点值之和等于目标整数时,将该路径保存。最终返回所有满足条件的路径。题目与二叉树的前序遍历有关,但需要在遍历过程中检查路径和。
描述
输入一颗二叉树的根节点和一个整数,按字典序打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。
所以说必须起点是根节点,终点是叶节点。
可以看一下官方示例来理解:
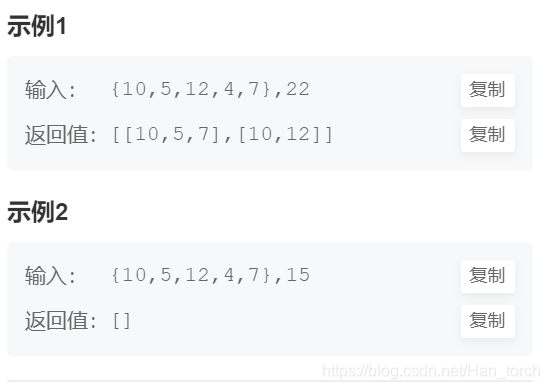
所以如果是一条路走到底的话,就是树的深度优先遍历(DFS)。
再来复习一下数据结构的基础:
深度优先遍历(DFS):首先以一个未被访问过的顶点作为起始点v,依次从未访问的邻接点出发对图进行遍历,直到图中和v相连的顶点都被访问到,若图中有未被访问的则从一个未被访问的顶点出发重新进行遍历。
广度优先遍历(BFS):以给定点为起始点,一圈一圈的遍历相关的所有点。
深度优先遍历相当于树的前序遍历,广度优先遍历相当于树的层序遍历。
跟JZ22从上到下打印二叉树联系起来,JZ22使用的是辅助队列,这道题需要使用的是辅助栈。
先定义深度优先遍历函数,将整个树的深度优先遍历路径输出。
其中:
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
所以在这里的作用是把树路径中的根节点值先去掉‘->’,然后转为int类型,为了做sum()函数的操作。
如果某一段路径的和值等于输入的那个整数,则把该条路径输入到列表中,最后返回这个二位列表。
class Solution:
# 返回二维列表,内部每个列表表示找到的路径
def FindPath(self, root, expectNumber):
res=[]
treepath=self.dfs(root)
for i in treepath:
if sum(map(int,i.split('->')))==expectNumber:
res.append(list(map(int,i.split('->'))))
return res
def dfs(self, root):
if not root: return []
if not root.left and not root.right:
return [str(root.val)]
treePath = [str(root.val) + "->" + path for path in self.dfs(root.left)]
treePath += [str(root.val) + "->" + path for path in self.dfs(root.right)]
return treePath

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









