



关注、星标公众号,精彩内容每日送达
来源:网络素材作者:Zhang Cheng,AMD开发者;来源:AMD开发者社区
在 AMD Versal 自适应 SoC 器件中,SelectIO 是实现高速接口的重要组成部分。它为器件提供了灵活且高性能的通用 I/O 资源,支持多种工作模式,能够满足源同步接口、异步接口以及各类自定义接口的需求。高速接口设计中,源同步接口(Source-Synchronous Interface) 是一种常见方式,其特点是发送端不仅传输数据信号,还会同时发送一条或多条时钟或选通信号(Strobe),以帮助接收端在高速条件下实现精确的数据采样。
在 Versal 器件中,XPIO 提供了灵活的时钟与数据路径资源。本文将以源同步接口为例,说明如何利用 XPIO 构建并实现带有 Strobe 的高速接口设计。
01
XPIO的内容部架构
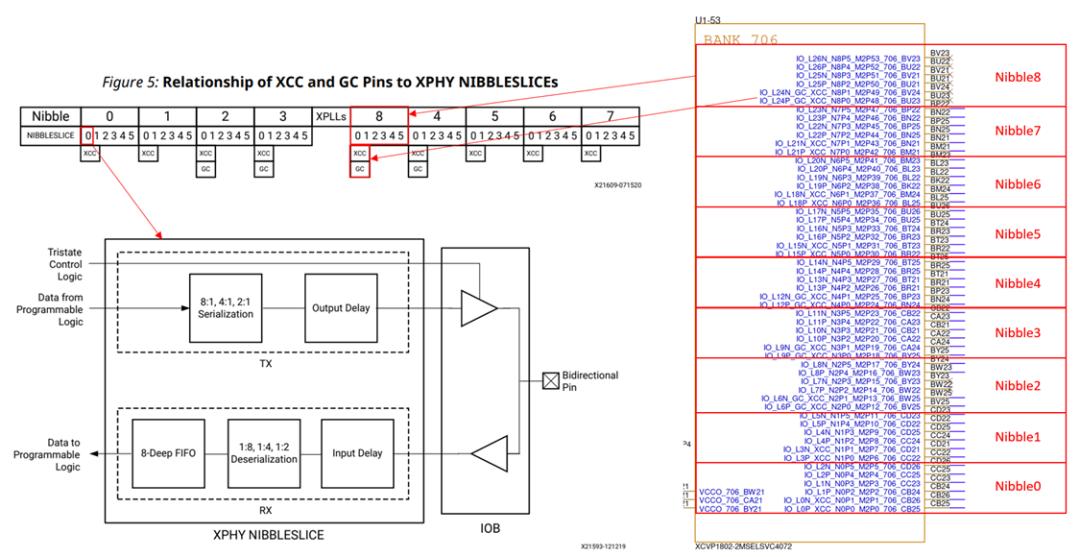
这里以VP1802的Bank706为例,如下图所示,一个Bank有9个XPHY Nibble和2个XPLL组成,每个Nibble有6个NIBBLESLICE,对应6个引脚或3组差分对,每个 XPHY NIBBLESLICE 由串行器(serializer)、解串器(deserializer)、I/O 延迟单元和接收 FIFO 组成。
02
GC和XCC管脚
GC是全局时钟输入管脚,通常作为XPLL的时钟源,可以驱动同一 XPIO bank 内的所有 XPLL,以及相邻 bank 内的 XPLL。
XCC是Strobe的输入管脚,Strobe通常是由对端的TX接口发送的。
在一个Bank中,只有NIBBLESLICE [0]和NIBBLESLICE [1] 可以用作GC或XCC的输入。无论是单端还是差分,都必须从与 NIBBLESLICE [0] 关联的 I/O 引脚输入。如果时钟是差分信号,那么时钟的反相信号(输入到与 NIBBLESLICE [1] 关联的 I/O 引脚)应与输入到 NIBBLESLICE [0] 的 I/O 引脚的信号连接到同一个差分缓冲器。
03
时钟布线资源
如果源同步接口有一路strobe输入和多路data输入,则可以利用XPIO内部的两种时钟资源( Inter-nibble clocking和 Inter-byte clocking)来转发 strobe。当SERIAL_MODE属性为FALSE时, Inter-nibble clocking和Inter-byte clocking会被使能,适用于同步模式; SERIAL_MODE属性为TURE时,每个nibble的采样时钟都来自于PLL_CLK输入,适用于异步模式。
1)Inter-nibble clocking
Inter-nibble clocking用于两个相邻XHPY Nibble对之间传递时钟。比如Nibble0和Nibble1在同一个Nibble对里面,它们可以相互使用对方的时钟。同样的还有Nibble2和Nibble3、Nibble4和Nibble5以及Nibble6和Nibble7。但是Nibble8因为没有与之配对的Nibble,因此也就不能通过Inter-nibble clocking资源与其他Nibble传递时钟,只能通过Inter-byte clocking来传递时钟。
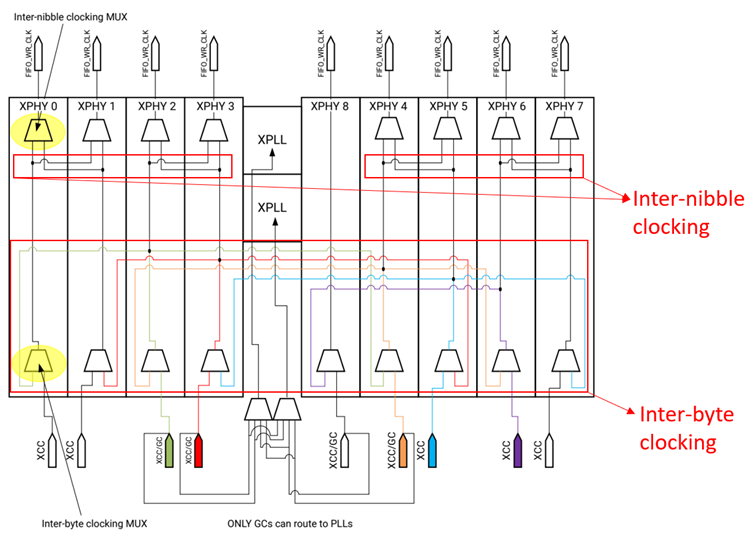
2)Inter-byte clocking
Inter-byte clocking支持在一个bank中的两个特定非相邻的nibble之间传递时钟,注意这里是特定的nibble,而不是所有的Nibble之间都可以传递。下面通过三个案例来做详细说明。
以Nibble3为例,它的Inter-byte clocking MUX的输出分别连到了Nibble1和Nibble5的Inter-byte clocking MUX输入端(下图红色线路),红框内的实心点表示水平与垂直线存在相交。因此对应到Table-7第五行第三列,Nibble3的时钟可以通过Inter-byte clocking传递到Nibble1和Nibble5,在到达Nibble5之后还可以再通过Nibble5的Inter-byte clocking把时钟传递到Nibble7,也就是上文所提到的特定Nibble,而不是所有的Nibble。
以Nibble0为例,它的Inter-byte clocking MUX的输出(下图黄色线路)只连到了Inter-nibble Clocking MUX的输入,没有与任何别的端口连接,因此Nibble0不能通过Inter-byte Clocking将自己的时钟传递到别的Nibble,也对应了Table-7第二行第三列的 “-” ,Nibble1的原因相同。
以Nibble8为例,它的内部没有Inter-nibble clocking MUX,Inter-byte clocking MUX的输出直接连到了XPHY的外部,Nibble8只能接收来自Nibble2、Nibble4和Nibble6传递过来的时钟,而无法将自己的时钟传递给别的Nibble,正如在Table-7的最后一行的所示。
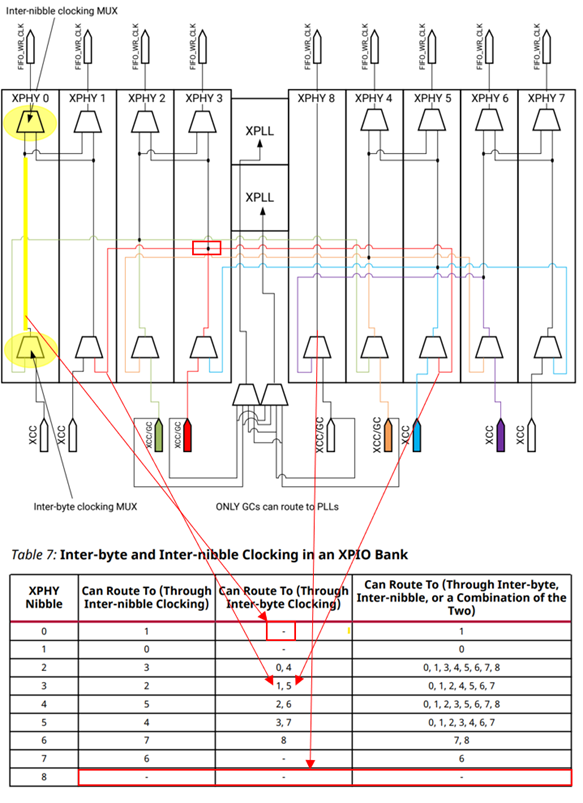
3)组合使用
组合使用两种时钟路径可以更加灵活地将时钟传递到其他Nibble中,比如要将Nibble2的时钟传递给Nibble7,可以先通过Nibble2的Inter-byte clocking把时钟输出到Nibble4(上图绿色路径),再通过Nibble4的Inter-byte clocking把时钟输出到Nibble6(上图橙色路径),最后通过Nibble6的Inter-nibble clocking把时钟输出到Nibble7。
注意组合使用存在一定的限制,Inter-byte clocking的时钟输出可以连到Inter-nibble clocking再次传递,但是不能反过来操作,这与XPHY的结构有关。从上图XPHY的结构图中可以看到,Inter-byte clocking MUX的输入是XCC或GC,输出与Inter-Nibble clocking MUX相连,所以时钟传递的顺序就必须是先到Inter-byte clocking,再到Inter-Nibble clocking,反过来没有对应的时钟路径。
以Nibble7为例,当1个XCC时钟被连到Nibble7以后,它可以通过Inter-Nibble clocking被传递到Nibble6,但是在这个时钟到达Nibble6以后就不能再被传递到其他Nibble中。因为Nibble7通过Inter-Nibble clocking输出的时钟没有任何路径可以再回到Inter-byte clocking MUX的输入端。因此,如果希望时钟被灵活的传递到同一个Bank的多个Nibble中,选择Nibble2、Nibble4的XCC或GC输入是比较好的选择。
04
应用分析
1) 使用Advanced IO wizard生成IP,这里需要注意以下几点:
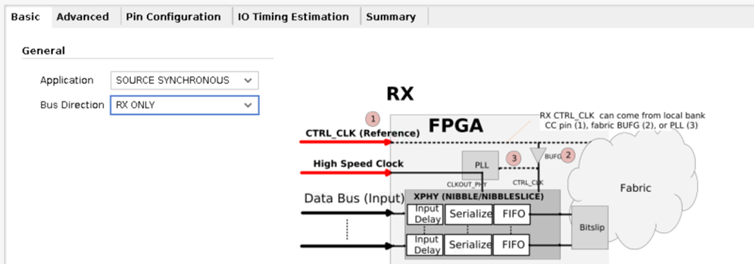
Basic页面,Application有两个选项,分别是源同步和异步,这里选择源同步(SOURCE SYNCRONOUS)。Bus Direction选择RX ONLY,其余保持默认。
Pin Configuration页面,这里需要设置Data通道的数量。因为XPIO的1个Bank有9个Nibble,每个Nibble有3组差分对,这样1个Bank总共有27组差分对可以使用。其中1对用于Strobe输入,那么在使用差分电平输入的情况下,Number of Data Channels最大只能设置为26。而使用单端输入时,可以最大设置为53。也就是说,1个XPIO Bank最多可以接收1路Strobe+26路data(差分模式)或1路Strobe+53路data(单端模式)。这里把Number of Data Channels设置为10。

2) 点击OK产生IP,右击IP选择open example design。
3) Example design生成完毕后,可以看到内部包含了两个Advanced IO的IP,名字分别为core_inst和exdes_inst,分别对应RX和TX两组接口
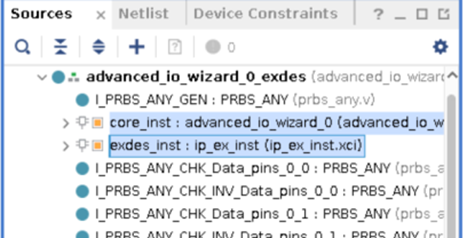
4) 管脚约束
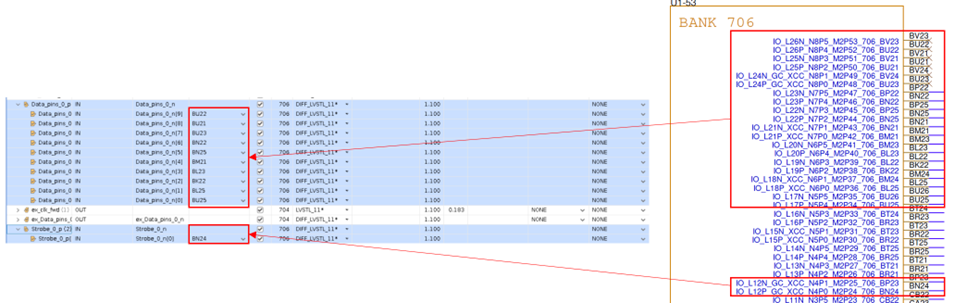
这里还是把1路Strobe和10路Data都约束在VP1802的Bank706,Strobe从Nibble4的XCC管脚输入,10路Data被约束到Nibble5-8,参考下图:
此外,TX相关的端口也需要作相应的约束,TX的管脚约束取决于外部信号的连接。所有输入到MMCM的时钟需要被约束到GC管脚,其余的输入输出管脚没有特别的要求,可根据实际情况连接。
5) 约束完成后,点击Generate Device Image,完成后open implemented Design,下面我们验证一下XPHY的时钟资源
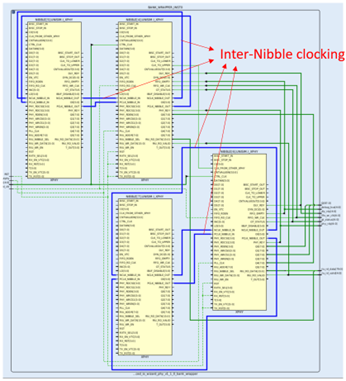
Strobe管脚被约束到了BN24,这个管脚属于Bank706的Nibble4
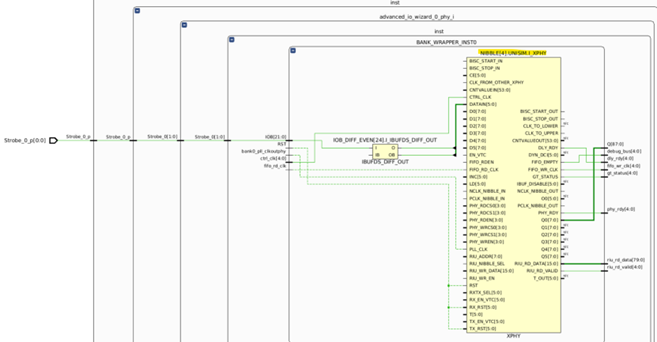
10路Data信号分别被约束到了Nibble5-Nibble8,根据XPHY内部的时钟结构,Nibbe4会通过CLK_TO_UPPER管脚经过Inter-byte clocking(下图蓝色线)输出时钟给Nibble6的CLK_FROM_OTHER_XPHY管脚和Nibble8的CLK_FROM_OTHER_XPHY管脚,如下图所示:
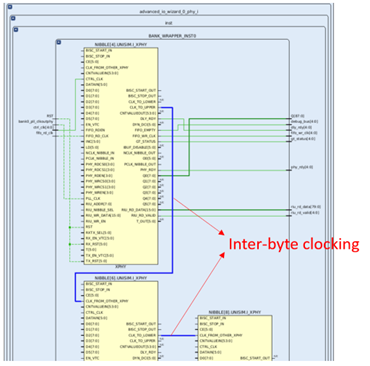
Nibble4和Nibble6再通过P/NCLK_NIBBLE_OUT管脚经过Inter-nibble clocking分别输出时钟给Nibble5的P/NCLK_NIBBLE_IN和Nibble7的P/NCLK_NIBBLE_IN,下图蓝色的走线都是Inter-nibble clocking。
6) 下一篇博客将结合仿真与上板实测数据,对 XPHY 的性能进行更深入的阐述与说明。
(全文完)
声明:我们尊重原创,也注重分享;文字、图片版权归原作者所有。转载目的在于分享更多信息,不代表本号立场,如有侵犯您的权益请及时联系,我们将第一时间删除,谢谢!

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









