 DQN迷宫挑战
DQN迷宫挑战







书接上回,《【强化学习】Q-learning训练AI走迷宫》
(去年的)本节讲述在相同的环境下,使用DQN来走迷宫。(假设我们已经了解相关基础。)
一. 概念重温
1.1 什么是DQN?
让我们从颗粒度上对齐一下:不良少年走迷宫 Deep Q Network
1.2 DQN比Q-learning好在哪儿?
在Q-learning中,我们使用一个Q值表(Q-table)来存储智能体在每个状态下采取不同动作的Q值。Q值表示在特定状态下采取某个动作的预期累积奖励。智能体通过不断地与环境交互和更新Q值表来学习最优策略。
但是在DQN中,我们使用一个神经网络来近似Q值函数,而不是直接存储Q值表。
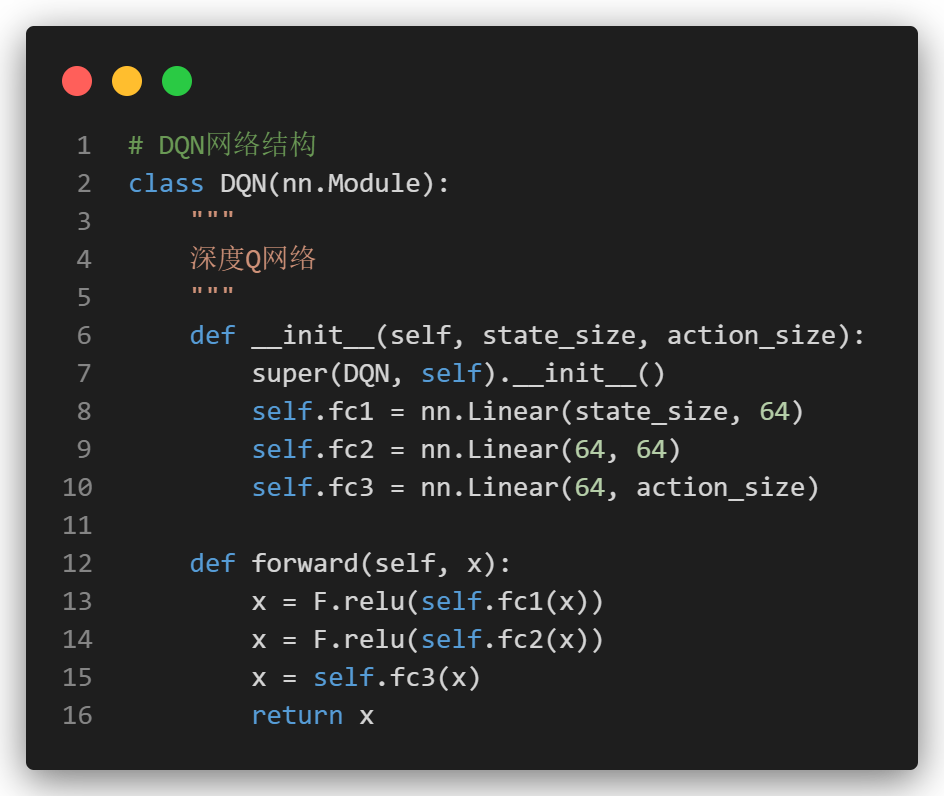
可以这么理解:DQN的优势 == 神经网络的优势:
1. 状态表示
- Q-learning:状态必须是离散的,Q值表的大小与状态和动作的数量成正比,适用于小型和离散的状态空间。
- DQN:状态可以是高维和连续的,因为神经网络可以处理复杂的输入。通过神经网络的泛化能力,DQN可以在大型和连续的状态空间中工作。
这是否意味着,原本我们固定的10*10迷宫可以进一步扩展成1000*1000的随机迷宫呢?
2. 存储需求
- Q-learning:需要为每个状态-动作对存储一个Q值,因此在大状态空间中,存储需求会迅速增长。
- DQN:神经网络参数的数量与状态和动作空间无关,只与网络的结构有关,因此在大状态空间中更为高效。
3. 训练过程
- Q-learning:
- 更新Q值表是直接的,但在高维状态空间中学习效率低,容易陷入局部最优。
- 智能体根据当前Q值表选择动作,观察结果,更新Q值表。
- DQN方法:
- 通过经验回放(Experience Replay)和目标网络(Target Network),DQN在训练过程中使用的样本更加多样化,减少了相关性,提高了学习效率和稳定性。
- 智能体根据当前Q网络选择动作,存储经验到回放缓存(Replay Buffer),从回放缓存中抽样进行训练,使用目标网络计算目标Q值,更新Q网络的参数。
下面解释一下这两个的好处。
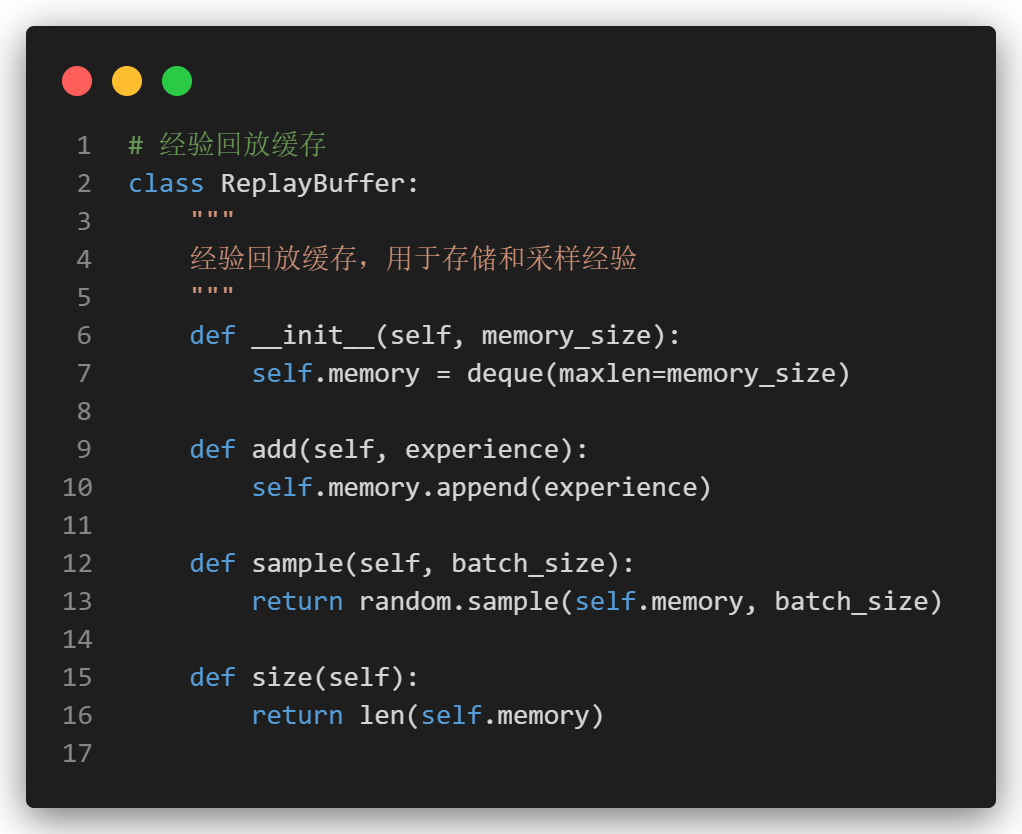
1.3 经验回放 (Experience Replay)
经验回放是一种通过存储智能体的经历并从中随机抽样的小批量经验进行训练的方法。
-
打破时间相关性:直接从环境中获取的连续样本可能具有很强的时间相关性,这会导致神经网络的训练不稳定。通过随机抽样经验回放缓存中的样本,经验回放打破了这种时间相关性,使得每个训练批次样本更加独立。
-
提高样本利用率:在传统的在线学习方法中,经验只能被使用一次。经验回放缓存允许经历被多次重用,提高了样本的利用率,从而提高了数据效率。
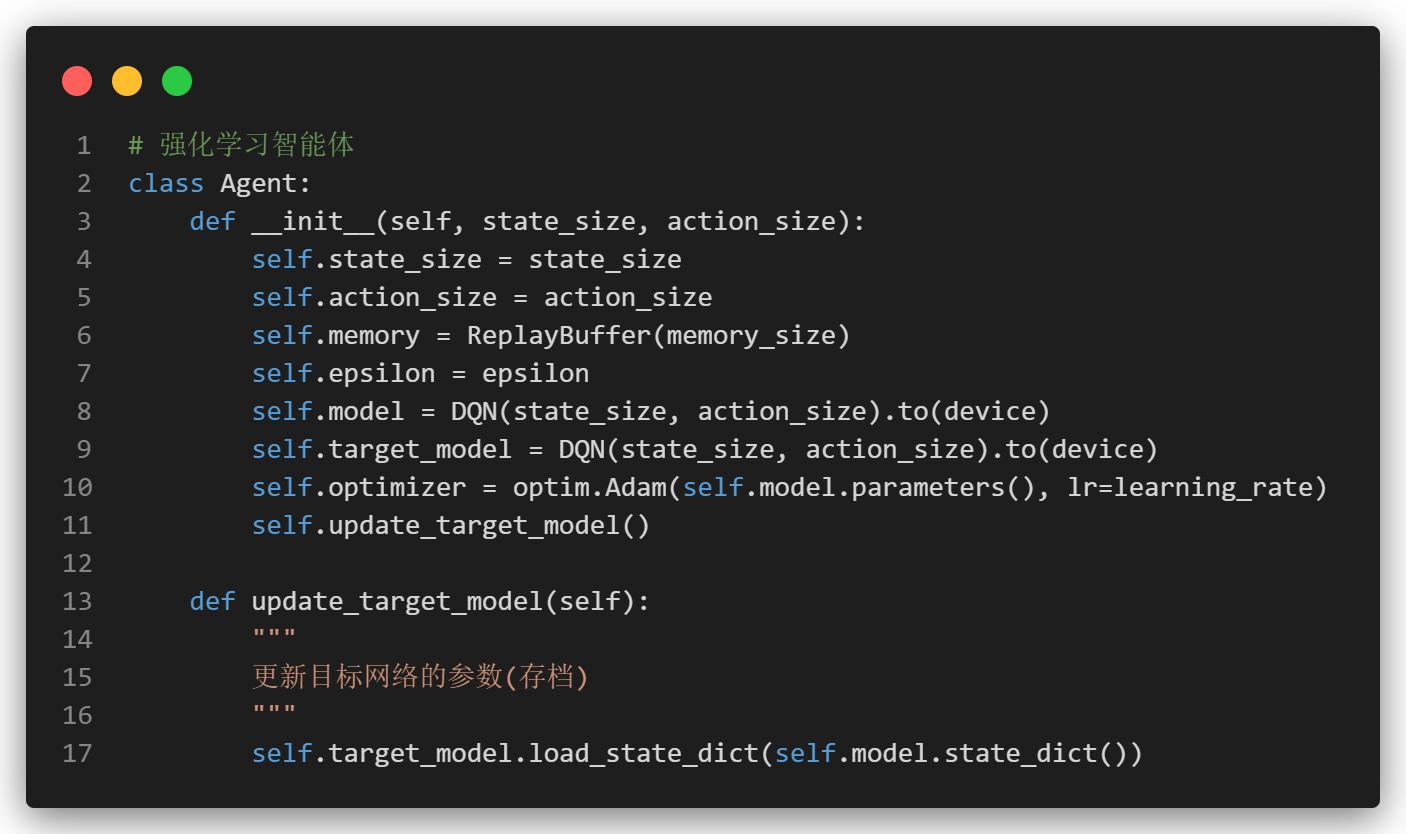
1.4 目标网络 (Target Network)
- 目标网络是一种用于计算目标Q值的固定神经网络,其参数每隔一定步骤才更新一次。
- 目标网络就像当前网络的一个存档。每次走了n步之后就要记得存档。
- 用来计算next_q_value。(后面看智能体学习逻辑会看到它。)
-
减少更新震荡:在没有目标网络的情况下,当前网络在更新时,目标值也在不断变化,这会导致训练过程中的震荡。目标网络的参数在短时间内保持不变,提供了一个稳定的目标,减少了这种震荡。
-
更快收敛:由于目标网络减少了更新的震荡,提高了训练的稳定性,因此可以帮助Q网络更快地收敛到最优策略。
二. 代码实现 (v1)
我们基于上一篇的实现进行修改,我们将分别对游戏地图、训练流程、奖励设置、动作选择和智能体的学习进行说明。至于其他可视化的绘图方法、模型保存之类的,就看仓库就ok啦。
2.1 地图生成逻辑
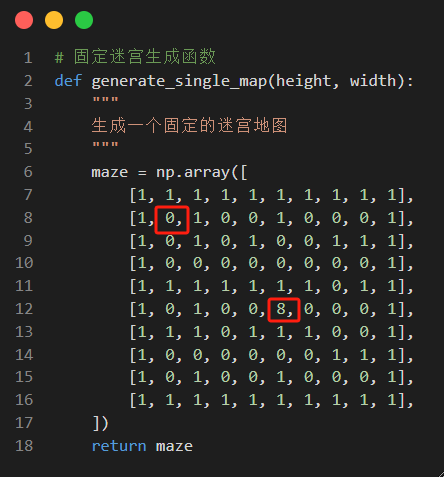
我们首先写一个固定地图生成函数,设置终点为数值8,1为墙,0为路。坐标(1,1)的0是我们固定的出发点。
2.2 训练流程逻辑
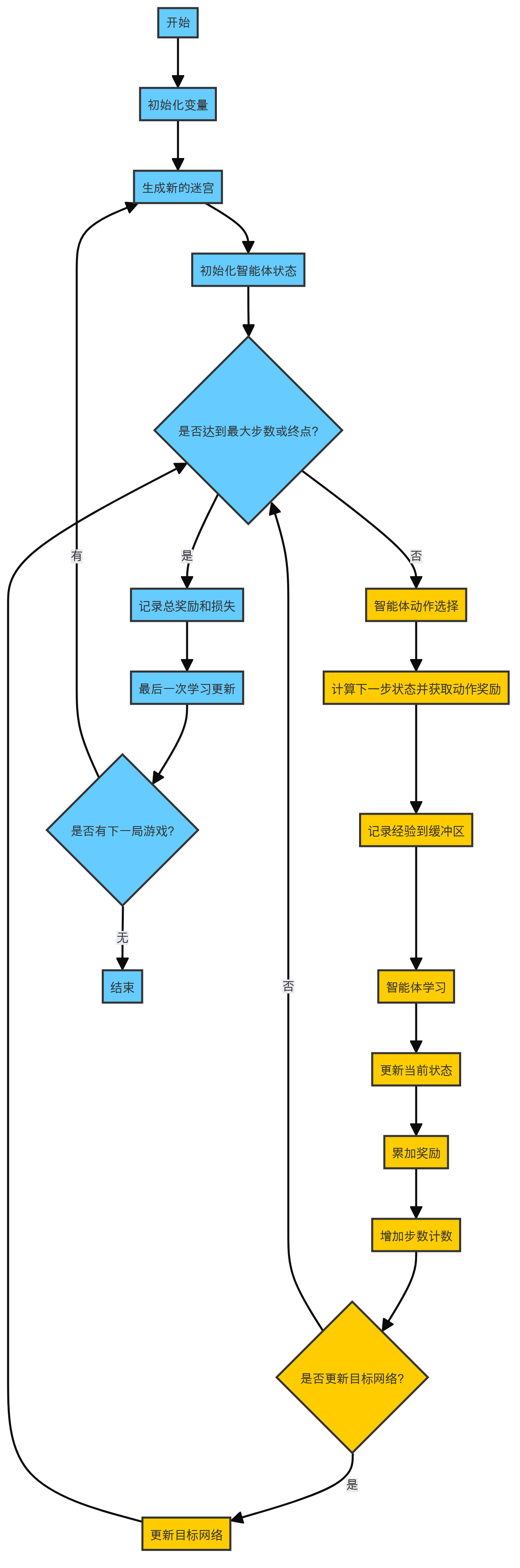
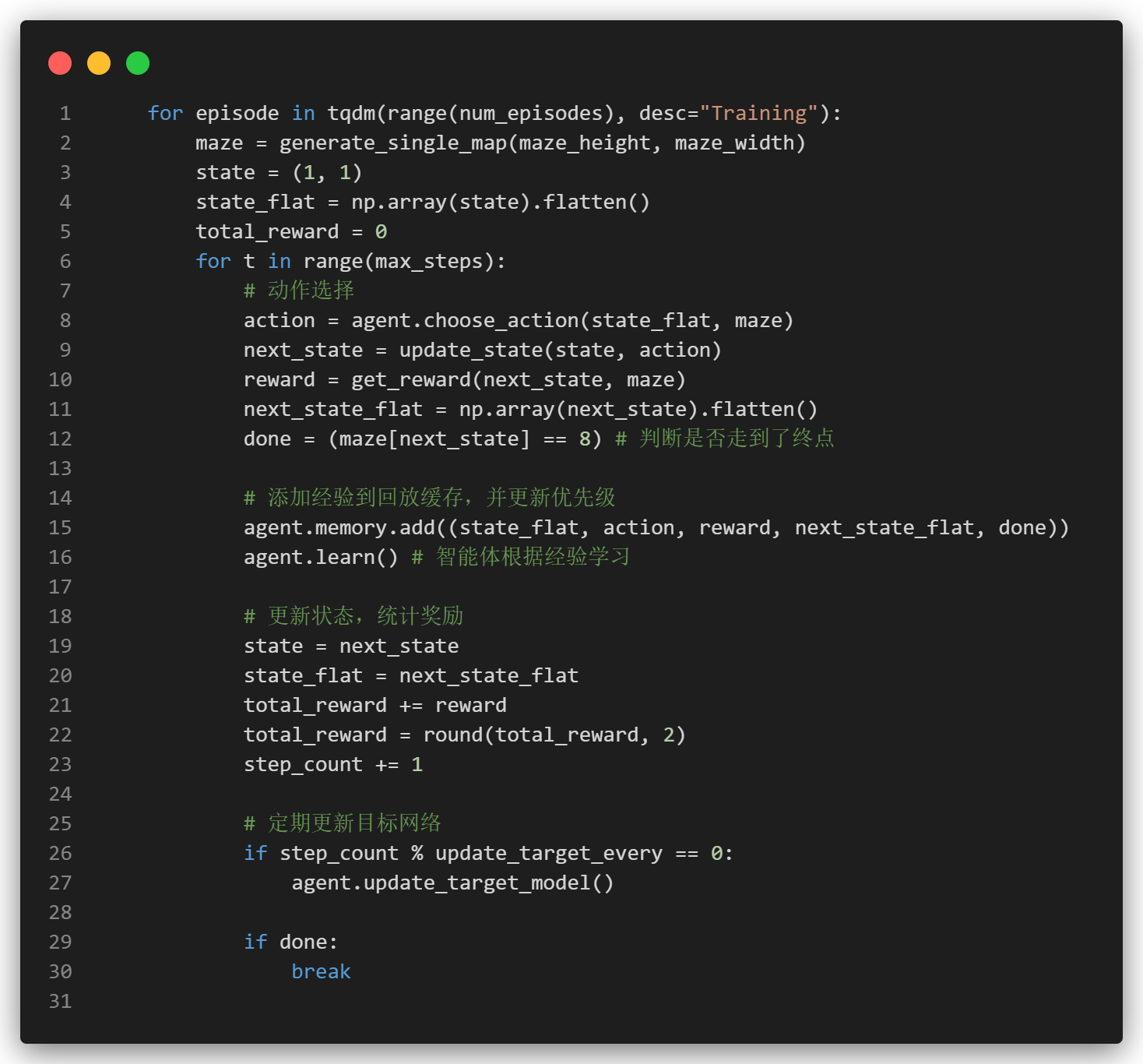
在每局游戏中,依旧是套用RL经典思路。我们设置一个最大步数的限制,每次选择动作之后,获取这个动作的奖励,将当前的状态记录到经验缓冲区中,并且让智能体从这些经验缓冲区中学习,最后更新游戏状态以及智能体采样用的目标网络即可。
2.3 奖励设置
我们的奖励逻辑和之前相同,从直观看,我们到达终点之后就给予大量奖励,每走1步扣0.1分。撞到墙上了就扣1分。

(不过我们在下面的动作选择进行了合法动作的过滤,理论上是不会撞墙的。)
2.4 动作选择逻辑
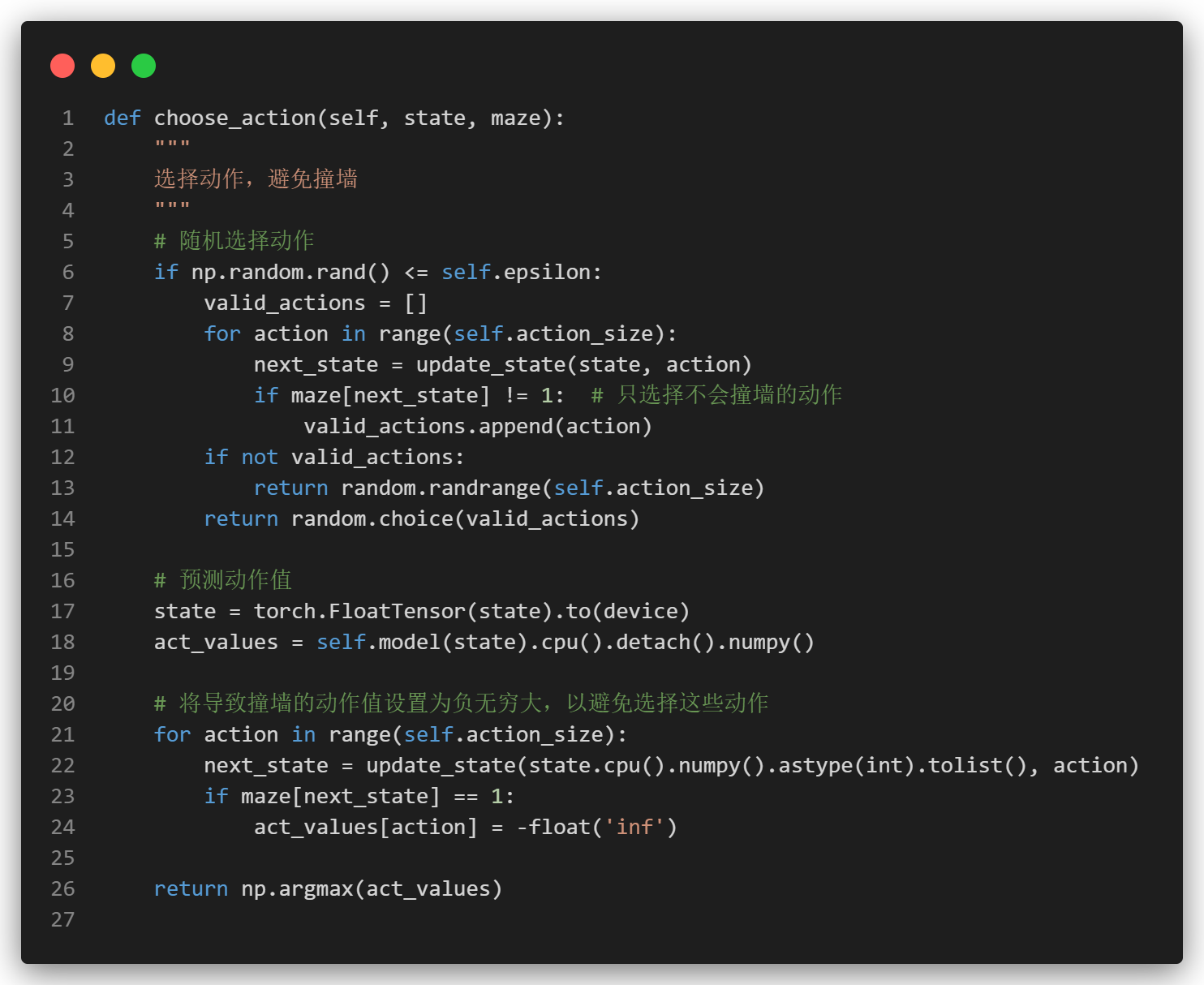
为了避免智能体陷入局部最优解,我们使用epsilon-greedy策略进行合法动作选择。在该策略中,智能体以概率epsilon随机选择动作(探索),以概率1-epsilon选择最优动作(利用)。
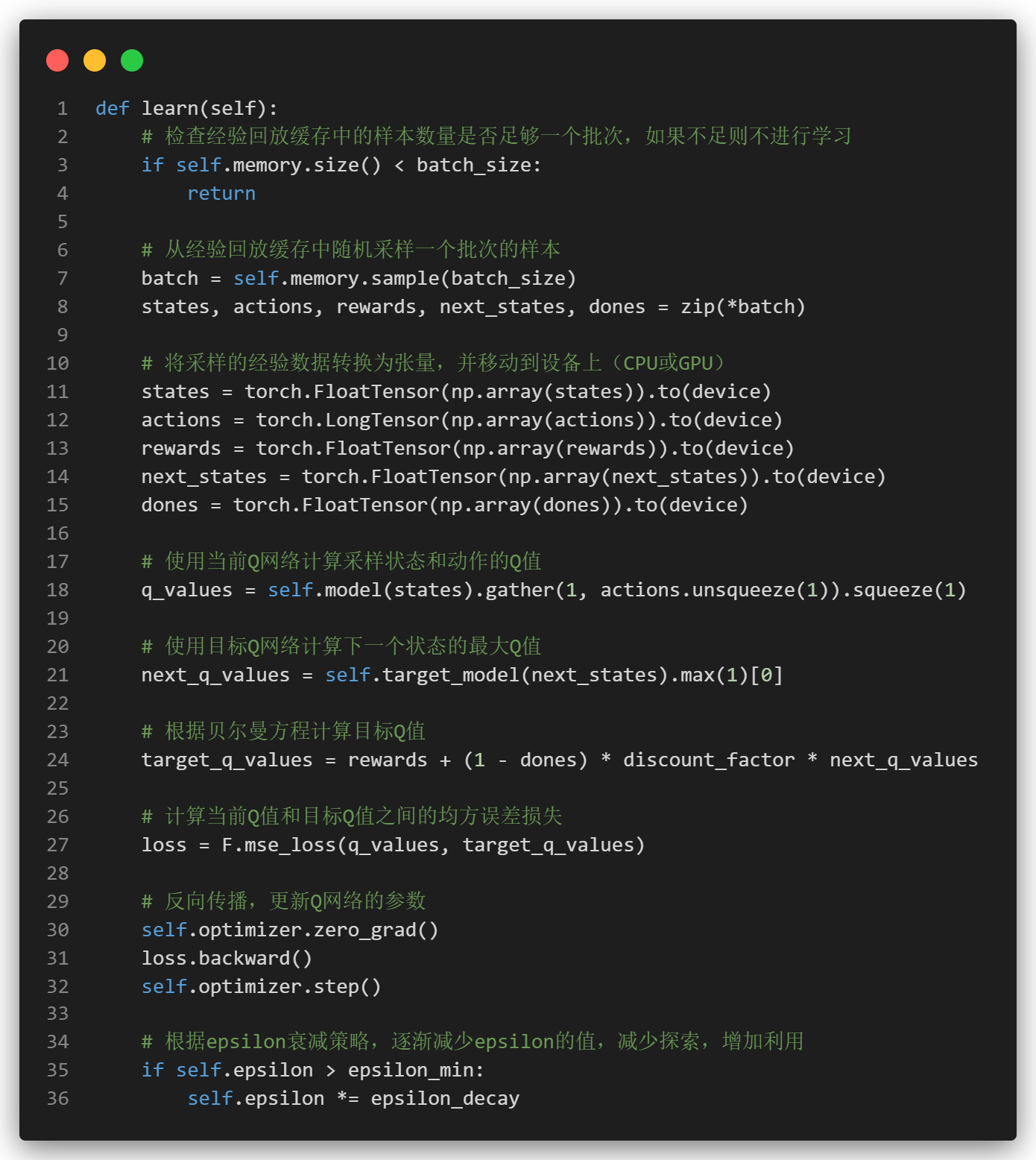
2.5 智能体的学习逻辑
在智能体的学习过程中,关键的一步是更新Q网络,使其能够更好地预测每个状态下不同动作的价值。
我们首先从经验回放缓冲区中随机采样,转为张量后,计算当前Q值和下一状态Q值,根据贝尔曼方程计算目标Q值,目标Q值等于当前奖励加上折扣因子乘以下一个状态的最大Q值。
最后计算均方差损失,反向传播即可。
三. 实际效果 (v1)
我们设置如下超参:由于最大步数设置为500步。如果每步-0.1分,没到达终点的情况下,最低分数应该是 -50。
# 超参数设置
num_episodes = 100 # 迭代次数
epsilon = 1.0 # 初始探索率
epsilon_min = 0.2 # 最小探索率
epsilon_decay = 0.995 # 探索率衰减
learning_rate = 0.001 # 学习率
discount_factor = 0.9 # 折扣因子
batch_size = 64
memory_size = 10000
max_steps = 500
model_path = "./models/dqn_maze.pt"测试效果出现了两极分化,如下:
1. 如果是初始随机时,智能体凑巧探索到了一条通往终点的道路,那么在大量财富的奖励下,将会迅速确定到一条最优的路线。
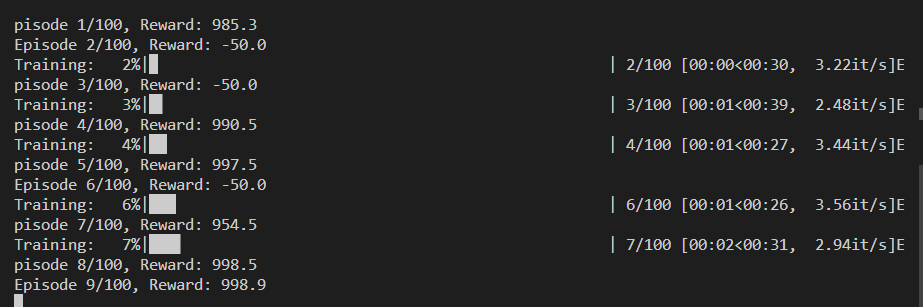
此时包括每局的训练时间都会特别短。(因为一下子就到终点了。)

2. 而一旦初始随机没有到达终点,智能体每次行动带来的代价会使得他依旧畏惧地在原地徘徊。
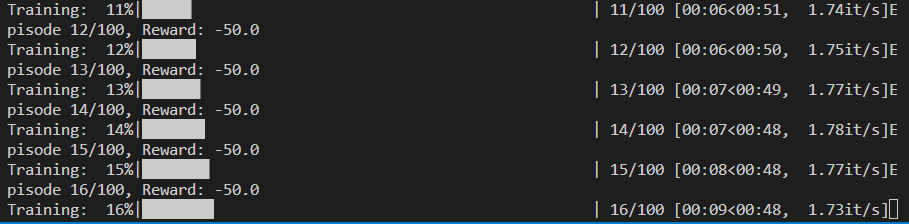
直到走完50步。

结论1
在后续调整地图的终点时,若智能体本身随机能够触碰到终点的概率越大,则越容易学到。但是如果是在我们地图的右下角,则几乎不可能依靠500步内随机到达终点从而获取奖励。
从智能体的视角上看,无论我选择哪一个动作,都是扣分,似乎就没有奋斗学习的必要了啊。

(下面内容是进阶版迷宫的思考)
四. 奖励优化
既然是我们奖励太稀疏,那么就需要洞察游戏环境本质!
4.1 距离优化?
既然我们想让智能体到终点,那肯定是越近越好呀。
我们是否可以设置一个最后结算的奖励,如果最后max_step到了,是否可以计算智能体距离终点的距离呢?最后距离越近,扣的分越少。
理想很美好,可现实和理想还有一堵无情的墙。
如果写一个广搜计算最近距离,那么就没有RL这个事情了。
4.2 探索优化!
迷宫的本质是是探索游戏,但是我们不需要重复来回的探索。
——思考n天的yy
-
增加小且频繁易得的奖励(访问记录):
- 每次智能体访问一个新的状态时,更新
visit_map,记录智能体访问过的位置。 - 在奖励函数中,添加对访问记录的检查,如果智能体访问一个已经访问过的位置,则扣分,如果是探索了新的区域,则加分。
- 每次智能体访问一个新的状态时,更新
经验之谈:设置奖励的时候不要总是扣分,转为适当加分的效果往往更好。
4.3 调参优化?(TODO)
RL的性能与超参数关联性比较强,这里我们并没有做过多的尝试。
4.4 经验回放 升级为 优先经验回放(TODO)
大部分情况下agent都是走超时的,即便出现了少量的通关场景似乎利用率不高,我们还可以在这里进行优化。提高通关样本的回放权重。
五. 完整代码
只是实现了一个简易版的DQN走迷宫,想要一个泛化能力超级好的DQN还没有实现,可惜周末结束了...
Github 代码文件 https://github.com/YYForReal/ML-DL-RL-Learning/blob/main/RL-Learning/Project/%E8%BF%B7%E5%AE%AB/game_v3_dqn_blog_1_explore.py如有大佬感兴趣,欢迎再来讨论一下。
https://github.com/YYForReal/ML-DL-RL-Learning/blob/main/RL-Learning/Project/%E8%BF%B7%E5%AE%AB/game_v3_dqn_blog_1_explore.py如有大佬感兴趣,欢迎再来讨论一下。


















 2909
2909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











