







TL;DR
- Youtu-GraphRAG 提出把 知识图谱构建 → 社区/层次化组织 → schema 感知的检索/拆解 → 生成推理 纵向统一成一个 agentic 流程,从而在复杂多跳/知识密集任务上同时提升准确率与效率。(arXiv)
- 核心亮点:Seed Graph Schema(种子 schema) 约束抽取、dually-perceived community detection(结构+语义混合的社区检测) 生成四层知识树、Agentic Retriever(schema-aware 的查询拆解 + 反思)、以及用于公平评测的 AnonyRAG(匿名还原) 数据集。论文与实现开源、并在多个基准上报告了显著的 token/精度收益。
文章目录
1. 引言:为什么要做 GraphRAG(以及痛点)
检索增强生成(RAG)把外部知识“检索 + 上下文化”注入 LLM,能显著降低幻觉并提升事实性。但当问题需要跨多个实体、依赖实体间关系链(多跳)或需要把碎片化信息组织成逻辑结构时,纯基于文档片段的 RAG 往往不够稳健:检索片段难以显式表达实体关系、跨文档链路会丢失中介节点、拼接上下文代价高且不利于可解释性。Youtu-GraphRAG 的出发点是:用图结构组织知识并把构建与检索纵向统一,能更好支持复杂推理与跨域迁移。(arXiv)
2. 一句话速览:论文与开源仓库
- 论文:Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning(arXiv,2025-08-27)。核心概念、算法与实验详见论文。(arXiv)
- 开源实现:TencentCloudADP / youtu-graphrag(GitHub),包含构建器、检索器、前端 demo、AnonyRAG 数据集链接与复现脚本。仓库 README 明确给出模块路径与运行示例。(GitHub)
- 附:作者/团队还提供了 HuggingFace 上的 AnonyRAG 数据集(用于匿名还原评测)。
论文宣称(最重要的量化结论):在多项基准上,Youtu-GraphRAG 能把 token 构建/检索成本显著降低(论文中给出
up to 90.71%的 token 消耗节省的上界),并在准确率上对比 SOTA 有 ~16.62% 的相对提升(详见论文实验节)。读者在引用时请以论文原文为准。(arXiv)
(注)仓库 README 在某处对 token 节省写了
33.6%的数字(可能是不同实验设置/平均指标),因此在引用具体数字时请优先核对论文/相应实验表与 README 的具体上下文。(GitHub)
3. 架构总览:四层知识树与 agentic 流程(概念图解)
Youtu-GraphRAG 的高层逻辑可以用以下步骤概括:

-
Schema-bounded extraction(种子 schema 约束抽取)
先定义 seed graph schema(目标实体类型、关系、属性),用其约束自动抽取 agent,从文档中抽出实体/关系/属性 triples。这样减少噪声并利于迁移。 -
Graph Construction → Dually-Perceived Community Detection → Four-level Knowledge Tree
构建基本图后,用一种“结构拓扑 + 子图语义”联合感知的社区检测算法,把图聚类成社区并生成层次化的 四层知识树(Attributes / Relations / Keywords / Communities),允许 top-down 过滤和 bottom-up 汇总。 -
Agentic Retriever(schema-aware query decomposition)
对复杂问题,检索 agent 会把 query 根据 schema 拆解成并行子查询(atomic sub-queries),并采用迭代反思(iterative reflection / IRCoT 风格)来修正与合并结果。 -
融合与生成(LLM)
把检索到的子图/社区 summary/原文片段融合成 LLM 的上下文(通常配合链式提示 / reasoning traces),生成最终答案并导出可解释的推理路径(能导入 Neo4j 可视化)。
这套纵向统一的 pipeline(从构建到检索再到生成)是 Youtu-GraphRAG 的核心工程哲学:不是把各模块孤立优化,而是让 schema 在全流程中发挥约束与协调作用。
4. 模块深入(对应仓库/代码文件)
下面以仓库里的目录与关键文件为线索,解读实现层面的要点(文件名直接来自 repo README / tree)。(GitHub)
4.1 知识图构建(KTBuilder)
- 关键文件 / 路径:
models/constructor/kt_gen.py(KTBuilder)。(GitHub) - 职责:以 seed schema 为蓝本,结合 LLM / OpenIE /规则从文档抽取实体、属性、关系三元组;进行消歧、合并与图数据结构化(可导出为 Neo4j 导入格式)。(arXiv)
实现细节提示:通常流程包含 NER → triple extraction → attribute extraction → entity linking/merge → 插入图数据库/内存图结构(networkx / DGL / neo4j)。kt_gen.py 在仓库中包含该流水线的实现(可在
FULLGUIDE.md中找到运行参数)。(GitHub)
4.2 社区检测与层次知识树
- 关键文件 / 路径:
utils/tree_comm.py(社区检测算法实现与层次构建)。(GitHub) - 算法特色:论文采用 dually-perceived 思路 — 同时使用图结构特征(拓扑)与子图语义(节点/边的 embedding 或 LLM 生成的摘要)进行聚类;并在聚类后做 community summary(用 LLM 生成高层抽象),从而得到四层结构:属性 / 关系 / 关键词 / 社区(Knowledge Tree)。(arXiv)
4.3 检索器与查询拆解(Agentic Retriever)
- 关键文件 / 路径:
models/retriever/agentic_decomposer.py(Query decomposer);models/retriever/enhanced_kt_retriever.py(KTRetriever);models/retriever/faiss_filter.py(向量检索过滤)。(GitHub) - 要点:拆解器基于 schema 把复杂 query 分解为若干 schema-aligned 的子查询(支持并行检索)。检索器结合图遍历(子图召回)与向量检索(Faiss)做候选过滤,再由 agent 进行迭代反思(IRCoT)以修正检索/拼接策略。(arXiv)
4.4 输出 / 可视化
- 关键路径:
output/graphs/(导出 Neo4j 导入格式与可视化数据),前端 demo 在frontend/。仓库 README 给出如何在本地通过 Docker 或脚本启 demo。(GitHub)
5. 关键算法细节解析
5.1 Schema-Bounded Extraction(形式化视角)
论文把 seed schema 写成一个紧凑集合 (S = (E, R, A)),分别是实体类型集合 (E)、关系类型集合 ® 和属性类型集合 (A)。抽取 agent 的行为被设计为:
给定 document (d),抽取 agent 输出受限于 (S) 的三元组集合 (\mathcal{T}d = {(e_i, r{ij}, e_j)}) 与属性对 (\mathcal{P}_d = {(e_k, a_l, v)})。
这种约束有两个好处:一是减少开放抽取带来的噪声;二是为后续检索/拆解提供统一语义空间,便于把 query 映射到 schema slot(实现时常用 LLM prompt + 验证器/规则混合)。
5.2 Dually-Perceived Community Detection(思路)
传统社区检测多用拓扑( L o u v a i n / L e i d e n Louvain/Leiden Louvain/Leiden)。Youtu-GraphRAG 提出的“dually-perceived”思路是混合拓扑相似度 S t o p o S_{topo} Stopo 与语义相似度 S s e m S_{sem} Ssem,例如:
S
j
o
i
n
t
(
u
,
v
)
=
α
⋅
S
t
o
p
o
(
u
,
v
)
+
(
1
−
α
)
⋅
S
s
e
m
(
u
,
v
)
S_{joint}(u,v) = \alpha \cdot S_{topo}(u,v) + (1-\alpha) \cdot S_{sem}(u,v)
Sjoint(u,v)=α⋅Stopo(u,v)+(1−α)⋅Ssem(u,v)
其中 (S_{sem}) 可由节点上下文 embedding 或 LLM 摘要后 embedding 得到。基于 (S_{joint}) 进行层次聚类可得到更语义一致的社区,再用 LLM 为社区生成 summary(meta-node),得到四层知识树(属性/关系/keywords/communities)。实现上 utils/tree_comm.py 是该逻辑的工程化实现点。(arXiv)

5.3 Agentic Retriever + Iterative Reflection(IRCoT)
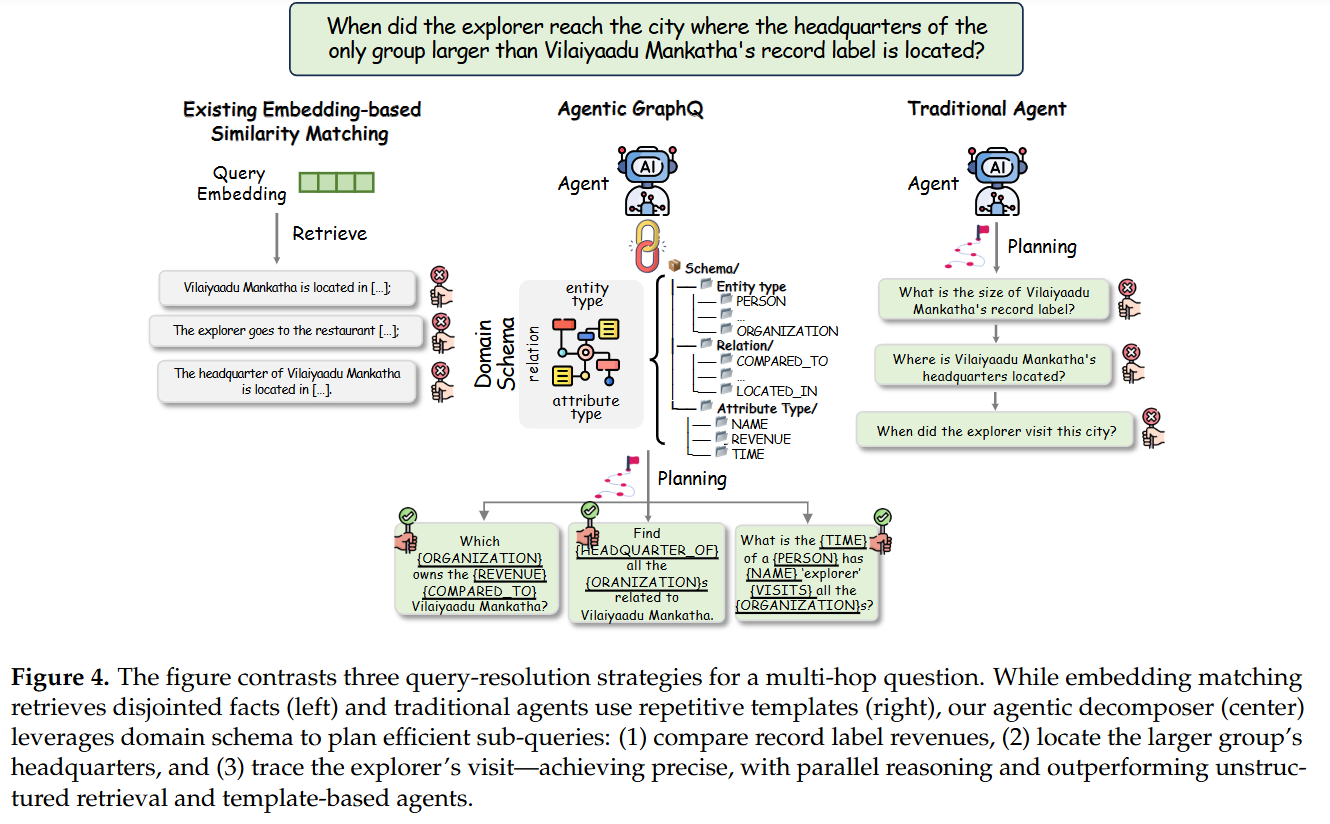
对复杂 query (q),拆解器会输出一组子查询 ({q_1,\dots,q_k}),每个 (q_i) 映射到 schema 的某一 slot(entity / relation / attribute)。对每个子查询并行检索得到子图集合,再由 agent 做合并/推理并在必要时生成新的子查询(反思步骤)直到满足终止条件(置信度阈值或 max rounds)。论文把这种 iterative retrieval + reflection 称为提升复杂推理能力的关键。
—
6. 实验与结果
6.1 实验设置
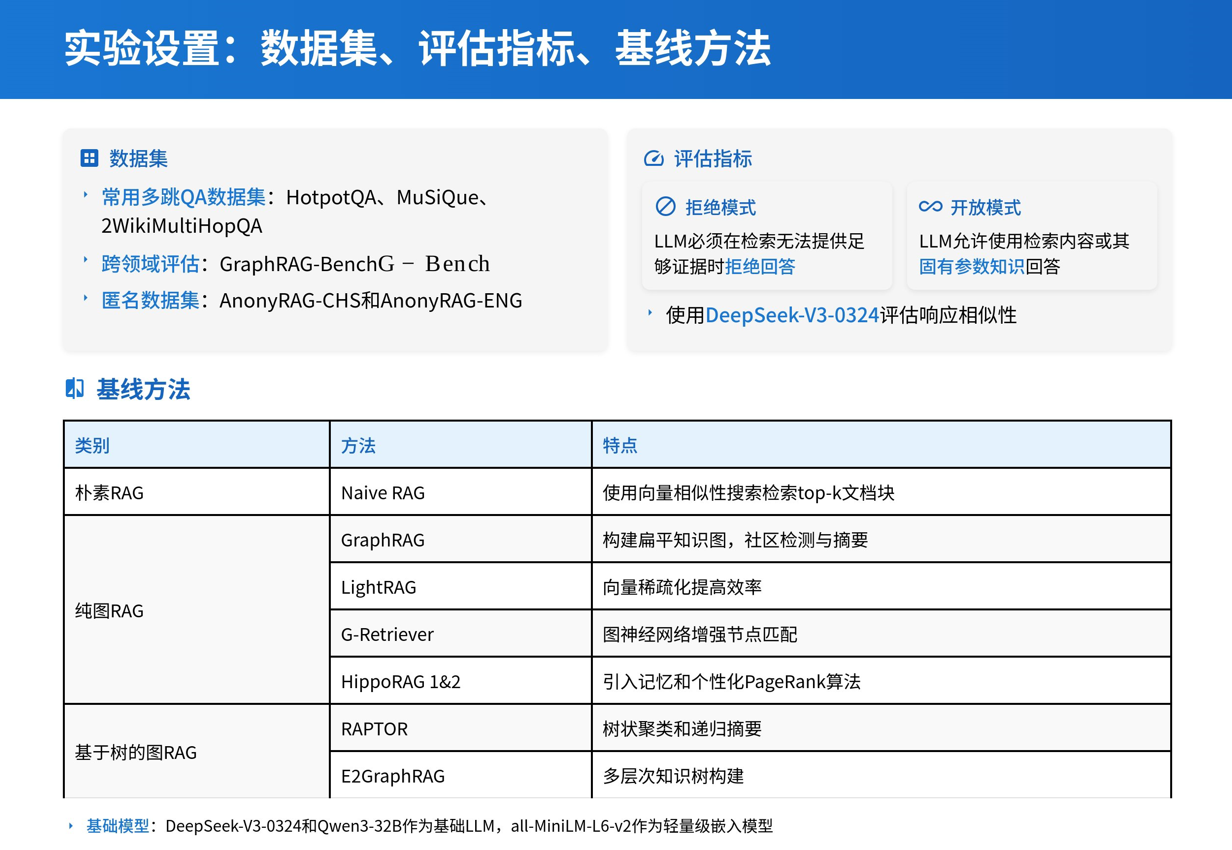
- 数据集:在六个具有挑战性的基准数据集上进行了广泛的实验,包括HotpotQA、MuSiQue、2WikiMultiHopQA、GraphRAG-Bench、AnonyRAG-CHS和AnonyRAG-ENG。为了评估框架的跨域性能,还提出并构建了两个新的双语匿名数据集AnonyRAG-CHS和AnonyRAG-ENG,并设计了“匿名反转”任务。
- 评估指标:评估分为两个阶段:首先评估检索证据的准确性,然后通过评估LLMs生成的响应质量来检查端到端性能。采用DeepSeek-V3-0324来评估响应相似性,以防止知识泄露。
为了确保公平的性能比较,我们使用相同的设置复现了所有基线和youtu-GraphRAG,并使用一致的指标进行评估。就基础模型而言,我们保持DeepSeek-V3-0324和Qwen3-32B作为基础LLM,以及一个轻量级嵌入模型all-MiniLM-L6-v2。 - 对比方法:包括Naive RAG、Pure GraphRAG、Tree-based GraphRAG等基线方法,以及youtu-GraphRAG的不同变体(如无代理的迭代推理和反思版本)。
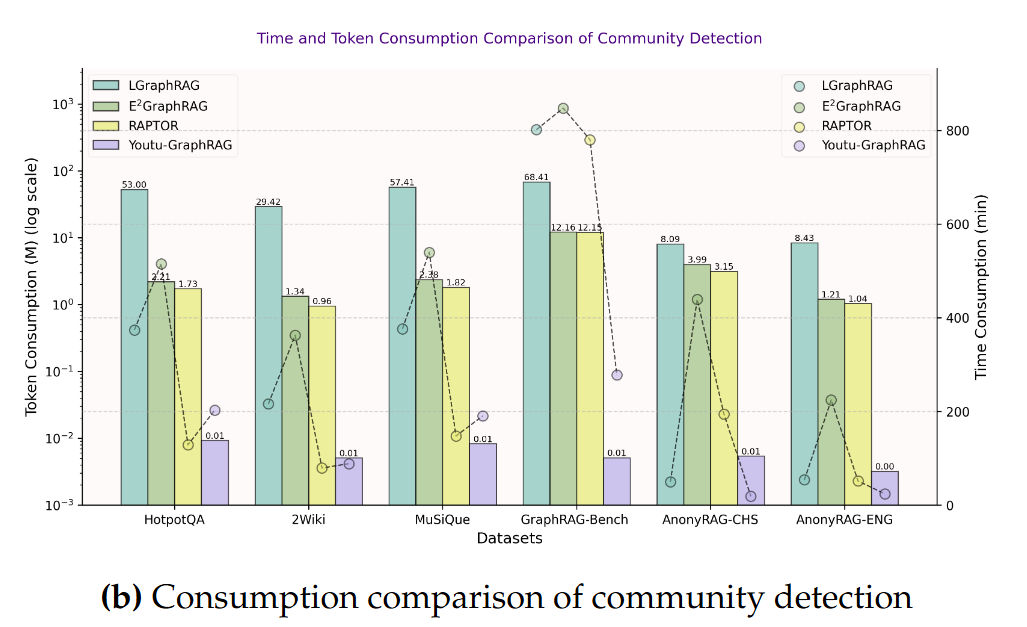
6.2 主要定量结论(摘自论文)
- 最高可达
up to 90.71%的 token 构建/检索消耗节省(论文给出的上界/若干设置下的最大值);整体上论文报告在某些配置下既降低 token 成本又提高准确率。 - 准确率提升:论文报告在多跳问答/合成任务上相对 baseline 有 ~16.62% 的提升(不同模型与后端 LLM 下的平均效果)。
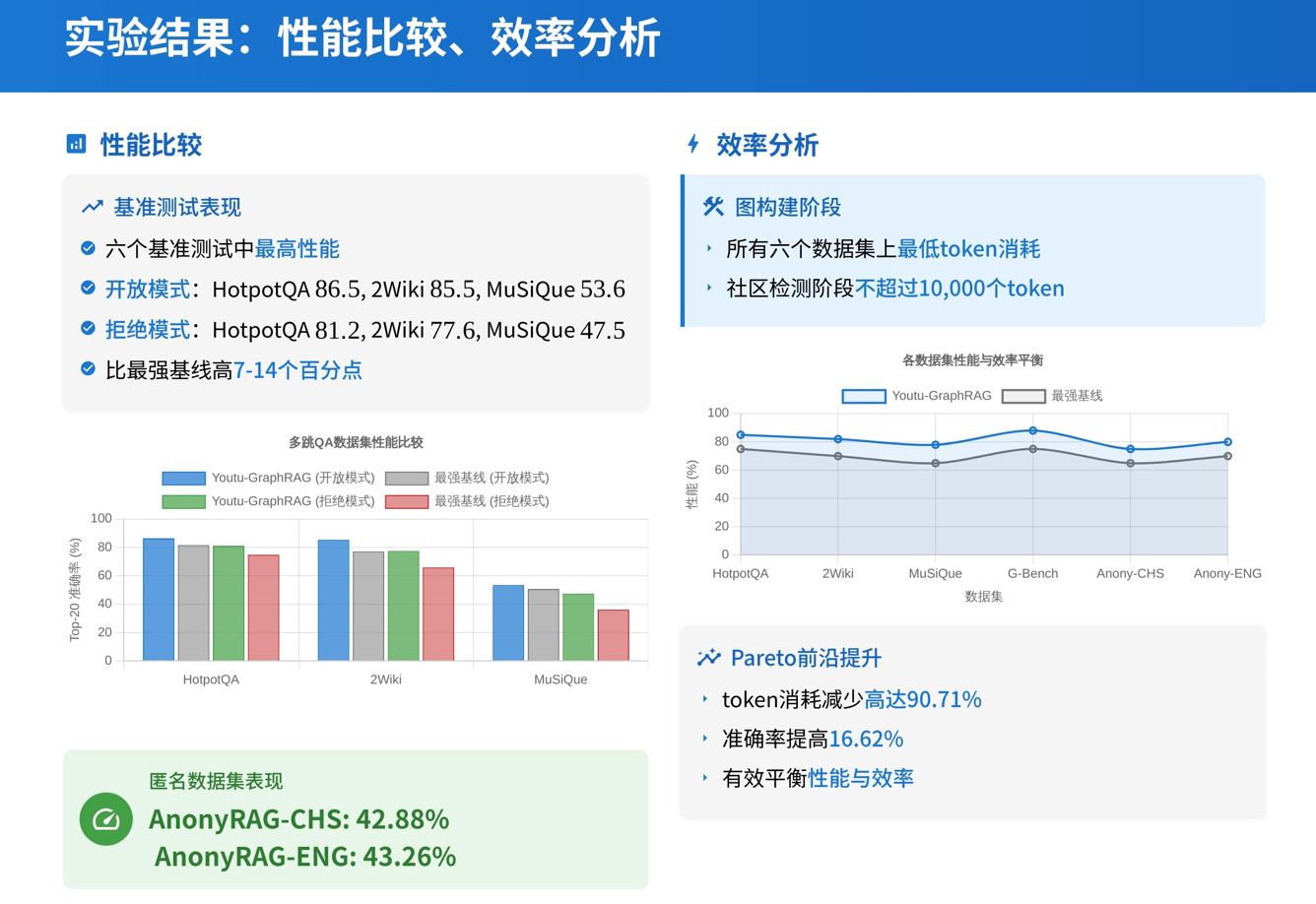
省钱!
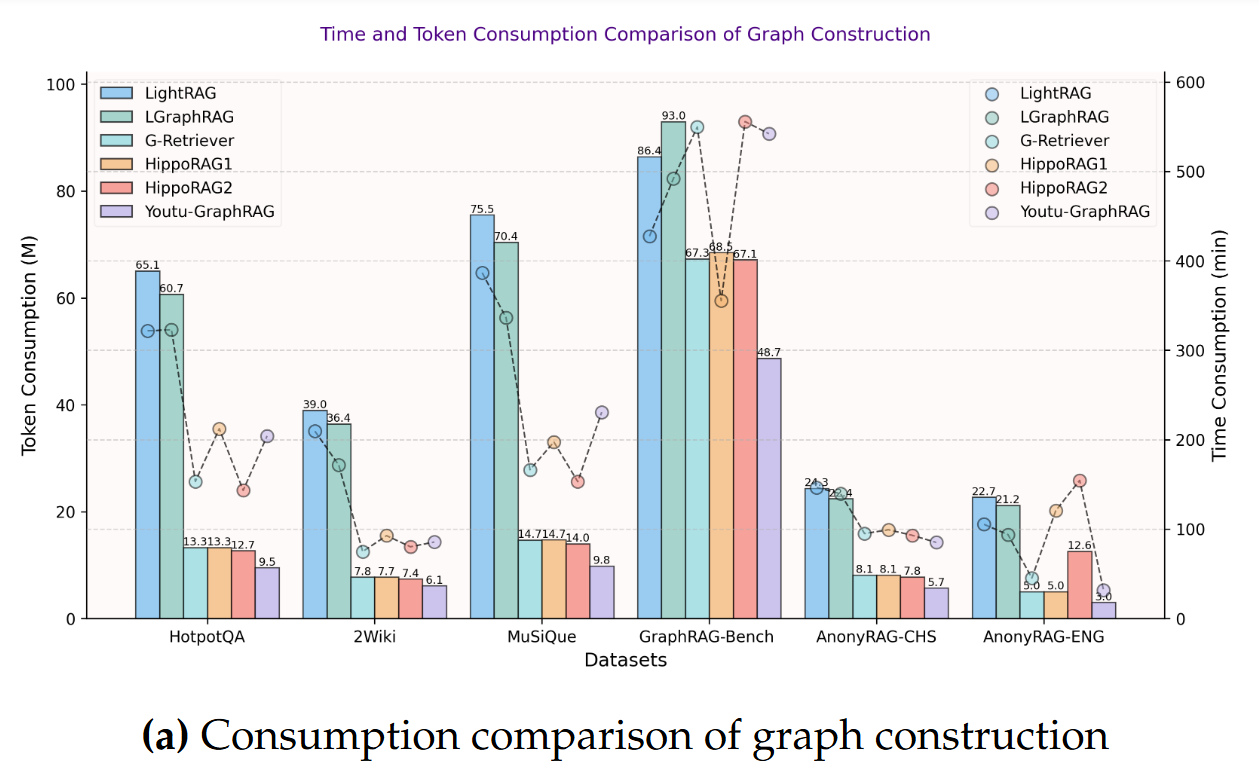
7. 预计可能需要注意的问题
- LLM 与 embedding 版本敏感:不同 LLM(Qwen、Deepseek、OpenAI、Qwen3 等)会产生不同抽取质量与 token 成本。论文给出的数值在不同后端会有显著差别——复现时记录模型/版本非常关键。
- Seed schema 的设计影响巨大:schema 定义过宽会导致噪声;太窄又会漏关键信息。建议先用小数据集逐步调优 schema,再做大规模构建。
- 社区检测超参数:dually-perceived 聚类里 α(结构 vs 语义权重)、社区最小/最大规模会影响 downstream 检索质量。可以做 grid search 或小样本验证。
8. 优势、局限与适用场景
优势
- 对复杂多跳/跨文档推理友好:图结构天然表达实体关系,便于构建可追溯的推理路径。
- 纵向统一利于迁移:schema 在构建与检索间作桥梁,有利于跨域迁移与工程化部署。
- 可解释性与可视化:社区 summary + 知识树便于审计与人工检查输出。
局限
- 构建成本与工程复杂性:图构建、社区检测与迭代检索带来计算与实现成本;并非所有查询都适合用图(简单事实查询开销不划算)。
- 依赖良好 schema & 高质量抽取:如果抽取质量差,图反而会产生噪声传播。
适用场景建议
- 企业知识库问答、科研文献综述、多文档多步合成类任务、需要可解释的法务/医疗知识检索等。对于「直接事实查询」或低延迟需求的场景,传统 lightweight RAG 仍然可能是更合适的选择。
9. 可延展研究与工程路线图
- 增量图 / 实时更新:对动态知识场景(如新闻/知识库)做增量图更新与 streaming 社区检测。
- 自动化 schema 学习:研究如何让系统自动建议新的 schema slot,减少人工介入。
- GNN/融合模块:在子图融合阶段引入 GNN 做关系融合,再输入 LLM。
- 成本感知的拆解器(RL 优化):用强化学习优化拆解策略,使系统在 token 成本与准确率间自动权衡。
- 跨模态 GraphRAG:把图中节点扩展到图像/表格/表单等多模态对象,构建跨模态知识树。
这些方向可以直接在 repo 的 models/ 子模块上扩展,也可以把 AnonyRAG 作为健壮性评测基准来驱动研究。
10. 总结 + 参考资源
总结:Youtu-GraphRAG 是一个工程化且富有洞见的 GraphRAG 实践——它把“schema”作为连接构建与检索的线索,提出混合拓扑与语义的社区检测、schema-aware 的查询拆解与反思流程,并提供开源实现与匿名评测数据集。论文在实验中展示了在复杂推理任务上提升精度并降低 token 成本的潜力,但复现与部署需要谨慎处理 LLM 后端、schema 设计与社区检测超参数。(arXiv)
参考资源:
- 论文(arXiv):Youtu-GraphRAG — Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning. (arXiv)
- 开源仓库:TencentCloudADP / youtu-graphrag(GitHub,含 FULLGUIDE、示例与代码)。(GitHub)
- AnonyRAG 数据集(HuggingFace,用于匿名还原评测)。(Hugging Face)



















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











