






简介
初次学习,我这次要复现的论文是南洋理工大学的 GauHuman:来自单眼人体视频的铰接式高斯飞溅
-
论文名称:GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
-
论文下载地址:https://arxiv.org/abs/2312.02973
-
项目主页:https://skhu101.github.io/GauHuman
-
代码开源:https://github.com/skhu101/GauHuman
配置:
系统:Linux version 5.15.0-124-generic (buildd@lcy02-amd64-118)
gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
显卡:NVIDIA GeForce RTX 4090
显卡驱动版本:Driver Version: 550.90.07
cuda版本:11.8
Anaconda下载和安装
下载anaconda:(这里推荐去镜像站选择想要的版本Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror)
wget --user-agent="Mozilla" https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2024.10-1-Linux-x86_64.sh安装anaconda:
bash Anaconda3-2024.10-1-Linux-x86_64.sh安装完毕后,输入conda,显示conda 24.11.0即成功安装
conda --version确定CUDA版本
下载官方代码
git clone https://github.com/skhu101/GauHuman.git安装虚拟环境前,我们需要了解系统的cuda版本,这里有两种情况
①键入nvcc -V,直接查看当前系统运行cuda
nvcc -V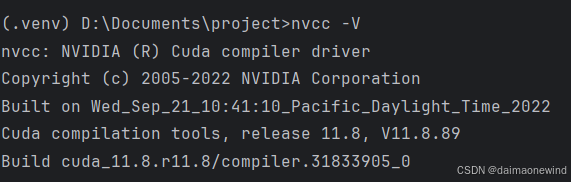
这里显示的cuda_11.8代表当前系统运行的是cuda 11.8版本
②使用服务器的同学可能在输入nvcc -V显示以下信息

这里我们去/usr/local/cuda/version.txt/version.json查询服务器运行cuda
cat /usr/local/cuda/version.txt
cat /usr/local/cuda/version.json
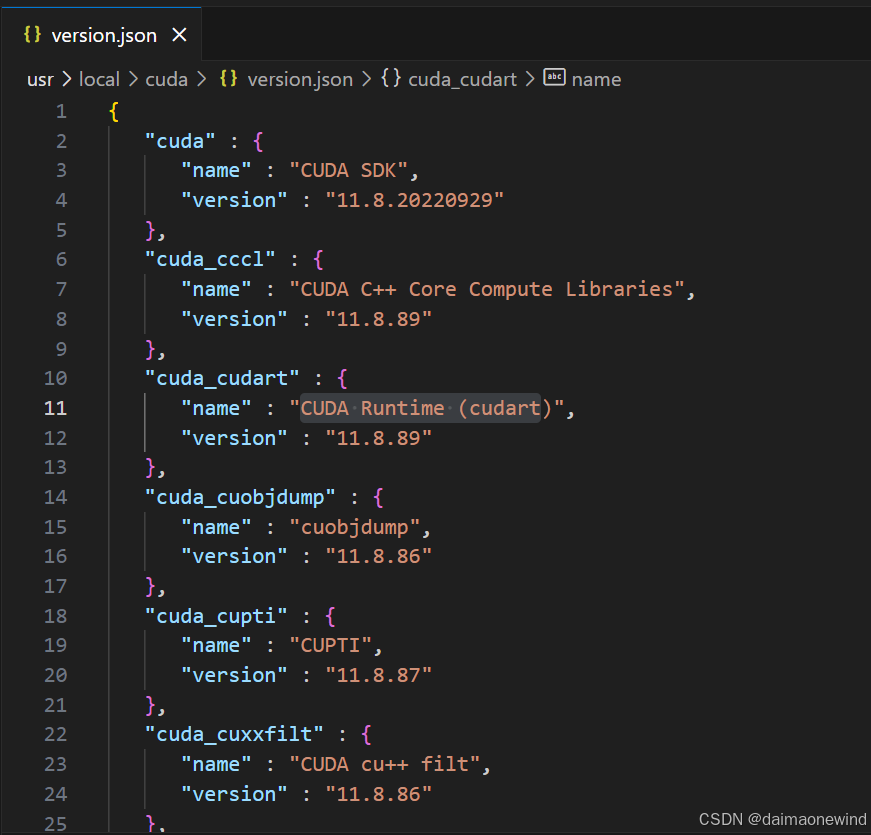
这里我们看到cuda版本为11.8
配置虚拟环境
确定了cuda版本后,我们开始配置虚拟环境
先克隆官方仓库
git clone https://github.com/skhu101/GauHuman.git
配置名为gauhuman的虚拟环境并且运行
conda create --name gauhuman python=3.8
conda activate gauhuman运行上述代码后,开头的(base)应该变为(gauhuman)表示已经进入虚拟环境

下一步需要安装torch,我们直接去pytorch官网查看
我是cuda11.8版本,所以运行以下代码,读者应当根据自己查到的运行cuda版本安装!
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia安装完毕后,我们按照官方文档逐步安装所需的包
pip install submodules/diff-gaussian-rasterizationpip install submodules/simple-knnpip install --upgrade https://github.com/unlimblue/KNN_CUDA/releases/download/0.2/KNN_CUDA-0.2-py3-none-any.whlpip install -r requirement.txt安装KNN-CUDA总是报错,可能是和网络问题有关,建议直接手动下载到目录然后手动安装https://github.com/unlimblue/KNN_CUDA/releases/download/0.2/KNN_CUDA-0.2-py3-none-any.whl
pip install KNN_CUDA-0.2-py3-none-any.whl到此为止,官方要求的环境已经安装完毕,接下来我们来下载模型
数据集下载
数据集按照文章下载即可,这里更推荐下载ZJU-Mocap数据集,一是只要填写表单即可获得,而是ZJU-Mocap在最近的文章中用的比较多,想要复现其他文章的时候可以用到,不用重复下载。
6个my_xxx.tar.gzd的数据集只要下载一个就可以开始训练了,也可全部下载。
下载完毕后,在GauHuman/data文件夹中新建一个名为zju_mocap_refine的文件夹
zju_mocap_refine文件夹建好后,将数据集放入该文件夹中,在该目录下新建终端执行解压命令
tar -zxvf my_394.tar.gz 解压完毕后,检查是否完全解压,以my_394.tar.gz为例,images下应该有00-22完整的文件夹
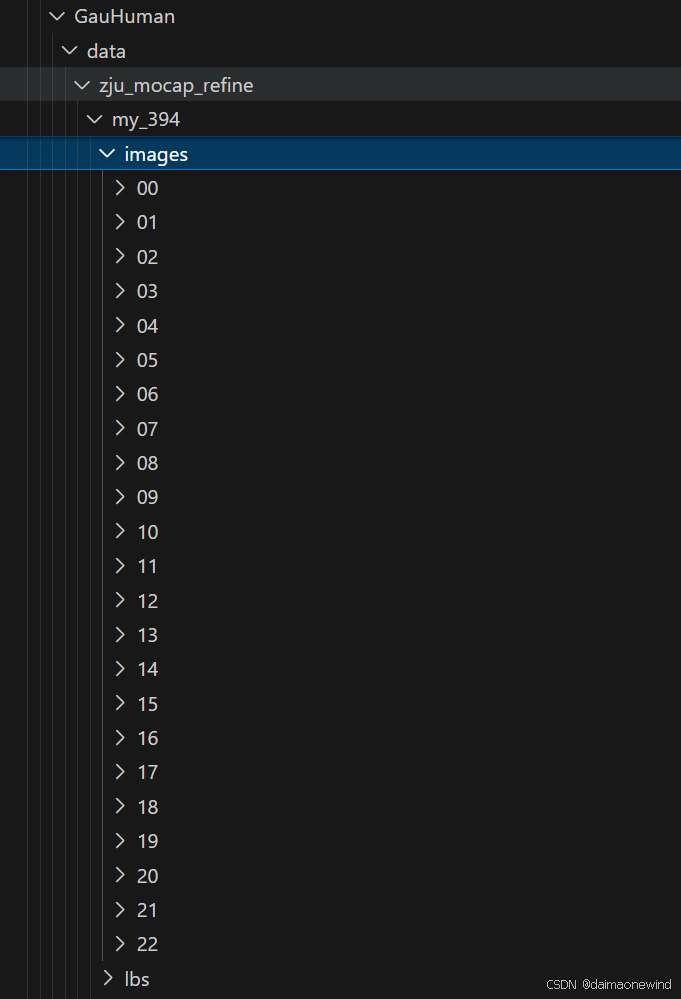
可在解压后的文件夹中的mask_list.txt中检查是否全部都下载了
SMPL模型下载
SMPL模型在下面的网址下载,点击SMPLIFY_CODE_V2.ZIP下载

下载后解压,在smplify_public\code\models中你会看到一个
basicModel_neutral_lbs_10_207_0_v1.0.0.pkl的文件,将该文件改名为
SMPL_NEUTRAL.pkl下一步,我们下载一个SMPLX的仓库,目的是为了删除 Chumpy 对象
git clone https://github.com/vchoutas/smplx.gitcd smplx在smplx\tools目录下的clean_ch.py中修改第34行的内容防止出现报错 //原内容
//原内容
def clean_fn(fn, output_folder='output'):
with open(fn, 'rb') as body_file:
body_data = pickle.load(body_file,encoding='latin1')执行下面的命令,\path\修改为指向SMPL_NEUTRAL.pkl的路径
pip install chumpy
python tools/clean_ch.py --input-models \path\ --output-folder output-folder将output-folder文件夹中的SMPL_NEUTRAL.pkl复制到GauHuamn/assets目录下
(assets文件夹需要自己创建)
到此,数据集和SMPL模型全部下载和配置完毕,正确的文件夹结构应该如下图所示
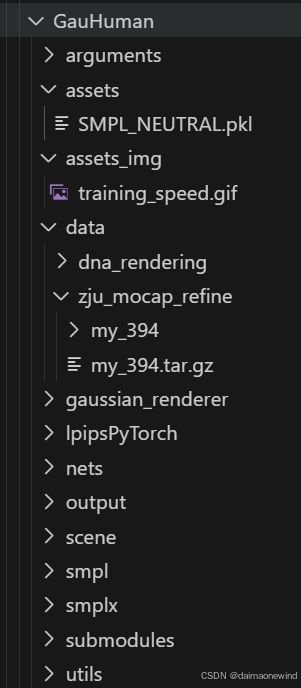
运行训练和评估命令
在运行run_zju_mocap_refine.sh之前,安装ninja库防止报错
pip install ninja安装好之后我们就可以开始训练和评估了
bash train_zju_mocap_refine.shbash eval_zju_mocap_refine.sh运行和评估结果都在GauHuman/outout目录下
心得
这是我第一次复现论文,前前后后花了近3天时间,先是在自己的电脑windows上尝试,但是由于第一次接触,在环境的配置上就很头大,更不要说后面要将sh命令修改为bat命令。于是我向实验室的学姐请求帮助,在实验室服务器来完成这次复现,有了第一次失败的经验,配置环境和修改代码都顺手了很多,只花了一下午就完成了代码运行。虽然这几天磕磕绊绊地,非常苦恼,完成所有代码运行的那一刻还是十分畅快的,希望能做出更多成果吧!

















 2550
2550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









