




 这篇笔记介绍了Python中字母大小写的转换,通过ord()和chr()函数操作Unicode编码实现。文章通过解决句子缩写问题,讲解了如何判断并转换小写字母到大写,探讨了函数的定义和复用性,最后展示了简洁的改进程序实现相同功能。
这篇笔记介绍了Python中字母大小写的转换,通过ord()和chr()函数操作Unicode编码实现。文章通过解决句子缩写问题,讲解了如何判断并转换小写字母到大写,探讨了函数的定义和复用性,最后展示了简洁的改进程序实现相同功能。
前言:本笔记仅仅只是对内容的整理和自行消化,并不是完整内容,如有侵权,联系立删。
一、字母的大小写转换
在信息学中,有许多符号都存储在一个叫做 Unicode 的字符集中。Unicode字符集非常广泛, 包括很多种语言的字符、符号和特殊字符。
字母在 Unicode 中的也有自己的存储编号。这是一个整数值,用于唯一标识对应的字符,比如小写字母 'a' 的对应 Unicode 编码值为97,小写字母 'b' 的编码值为98,对于小写字母而言以此类推。大写字母 'A' 的对应 Unicode 编码值为65,大写字母 'B' 的编码值为66,对于其他大写字母而言以此类推。
我们可以使用 Python 中的 ord ( ) 函数来查找字符的 Unicode 编码值。
# 使用 ord() 函数
print(ord('A')) # 输出 65
print(ord('Z')) # 输出 90
print(ord('a')) # 输出 97
print(ord('z')) # 输出 122二、利用所学解决问题
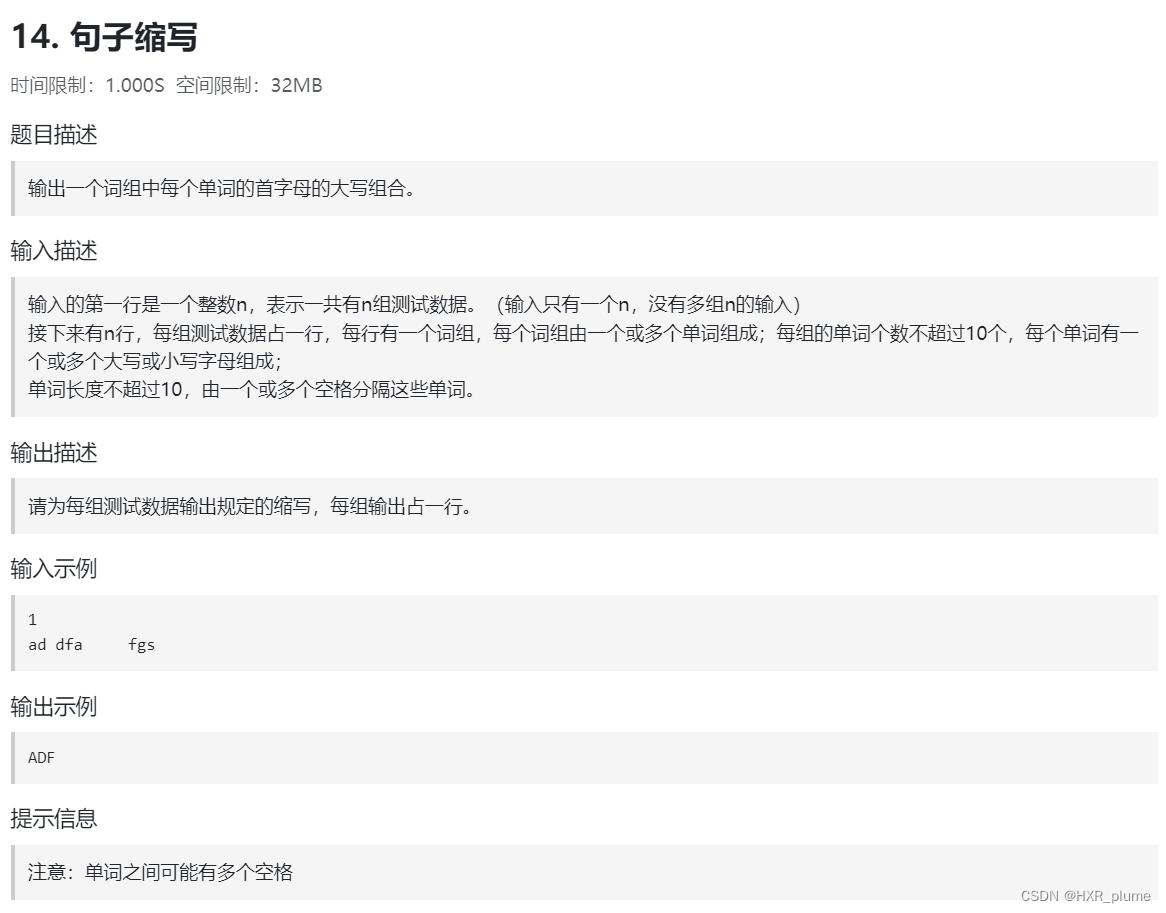
针对上述程序,我们进行一定分析。首先,因为输入只有一个 n,没有多组 n 的输入,因此不需要使用 while True 语句。其次,我们选择对输入的整个字符串进行处理。在处理过程中,我们遍历整个字符串,对所有前一个字符是空格,并且此时所处位置不是空格的字符均可认为是一个单词的首字母,我们将它
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









