




【本节概括】本节主要讨论如何对网页进行排序,使得用户能够最快获得所需信息。
目录
一、信息检索与相关度计算
1.1 信息检索模型概述
信息检索模型是用来描述文档与查询的表示形式与相关性的框架。一个好的信息检索模型应该在可以理解用户的基础之上,产生近似用户决策的结果,从而在顶部返回最相关的信息。
信息检索模型的形式化表述: [D, Q, F, R(Di, q)]
- D:文档表达
- Q:查询表达
- F:查询与文档间的匹配框架
- R:查询与文档间的相关性度量函数(Di与q分别表示特定文档与查询)
以布尔模型为例,对应介绍信息检索模型的形式化表述如下:
- D:文档表达——词项的组合(注意是词项不是单词!)
- Q:查询表达——布尔表达式(词项 + 布尔运算符)
- F:完全匹配(二值匹配)
- R:满足布尔表达式,相关性为1,否则为0(即使部分满足)
但布尔检索的二值化匹配并不准确,我们需要为每个【查询 - 文档】赋予一个 [0, 1] 中的分值来衡量并排序其匹配程度。
1.2 向量空间模型
布尔模型的假设是所有的查询条件都必须满足,事实上大部分情况下并不能完全满足。如果用查询和文档之间的重合度来估算文档的相关性,那么就可以实现部分匹配。
如果 A 和 B 是两个集合,那么有:
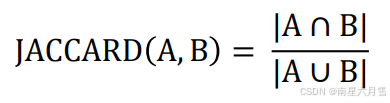
显然,我们有:JACCARD(A, A) = 1,JACCARD(A, B) =0(如果A ∩ B = ∅ )。我们可以用 Jaccard 来量化查询和文档的重合度,举个例子:

然而,这样的部分匹配没有考虑到查询词本身的重要性区别,也没有考虑文档的长度因素(词多的文档天然吃亏)。比 Jaccard 更进一步,如何通过词项区分文档的权重?显然,查询词在文档中出现的越多,该文档越相关。
我们定义,词项频率TF(t,d),指词项 t 在文档 d 中出现的次数(Term Frequency)。利用原始的TF值,可以粗略计算文档的相关性,但存在一定问题,相关性与频率并不线性相关(某个词在文档A中出现100次,在文档B中出现10次,A比B相关10倍,这样的假设显然有问题)。
在原始TF基础之上的改进:引入对数词频
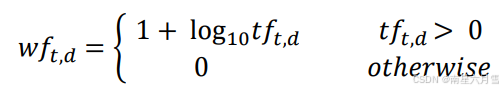
通过这种方式,数量级的差异性所造成的影响变得更为缓和.我们可以将文档与词项的匹配得分定义为所有同时出现在查询与文档 中的词项其对数词频之和,即
![]()
用这样的方法给文档和查询之间建立索引,不同文档的相关性可以很容易地出现区分,
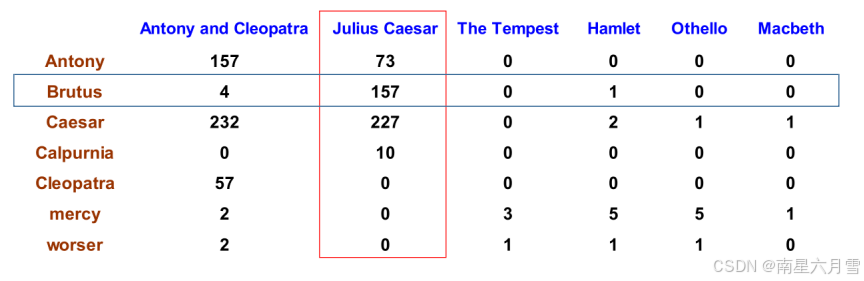
但我们还可以更进一步。有些词因为本身很常用,因此出现率很高(比如说,停用词)。这些词对最后结果的排序并没有什么贡献,反而可能产生一些干扰。
对此,我们要知道罕见词的信息量更为丰富,而频繁词的信息量相对较少。相应的,如果查询中包含某个罕见词,则包含这个词的文档可能很相关。
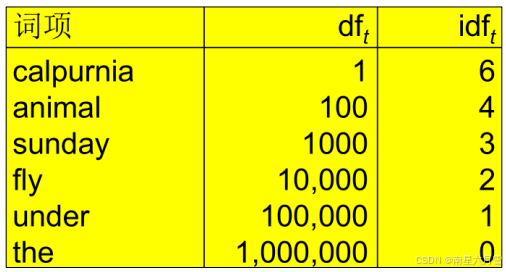
基于上述思想,引入新的度量机制:文档频率(Document Frequency) df_t,指出现词项 t 的文档数量。相应的,我们一般采用逆文档频率(Inverse DF)来衡量
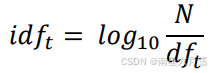
通过这样的计算方法将过于频繁的词的作用完全抹去,比如下面的示例:
将上面的 TF 和 IDF 结合起来,我们可以得到更完整的描述方式:
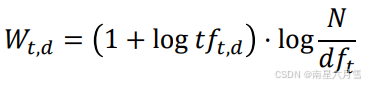
从这个指标中,我们可以看出在少数文档内多次出现的词更适合衡量文档的相关性。指标随词项频率增大而增大,随词项罕见度增大而增大。
这个指标就是我们的向量空间模型(VSM)中采用的量化方法。它将每个文档和查询视作一个词项权重构成的向量,查询时通过比较向量之间相似性来进行匹配。如果用开头提到的形式化表述加以概括,那么就是:
- D:文档表达,每个文档可视作一个向量,其中每一维对应词项的tf-idf值
- Q:查询表达,可视作一个向量,其中每一维对应词项的tf-idf值
- F:非完全匹配方式
- R:使用两个向量之间的相似度来度量文档与查询之间的相关性
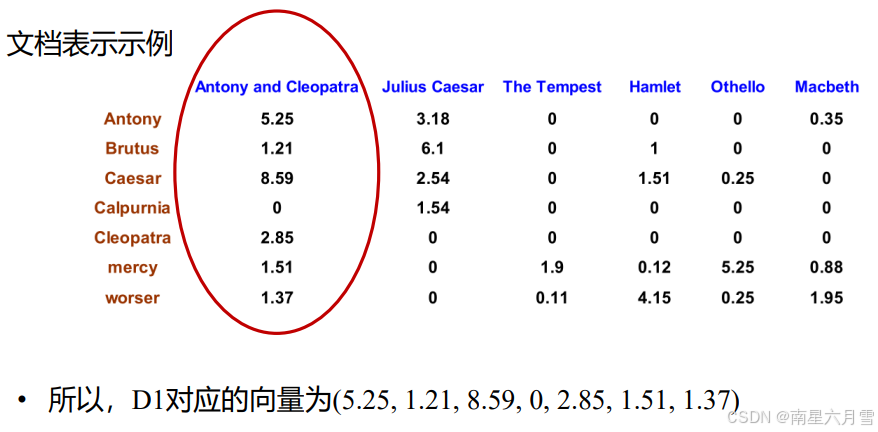
总结来说就是:首先,将文档与查询表示成词项的tf-idf权重向量;其次,计算两个向量之间的某种相似度(如余弦相似度);最后,按相似度大小进行排序,将Top-K的文档返回给用户。
【余弦相似度】

这种模型的优点在于简洁直观,可以支持多种不同度量或权重方式,实用效果不错。缺点在于缺乏语义层面的理解和匹配,同时依赖tf-idf值也可能造成干扰。
1.3 查询迭代优化
用户的查询需要通过相关性反馈逐步更新,本质上,这是一个逐步逼近用户目标文档的过程。
某种意义上说,由向量表示的文档,可以视作高维空间中的一个点。由此,“质心”就是一系列点(文档)的重心。这里我们要介绍的迭代算法 Rocchio 算法使用一种近似逼近的方式试图找到一个完美的最优查询向量,使得查询尽可能离与之相关的文档更近,离与之无关的文档更远。
Rocchio算法(1971)实际使用的近似方法如下:
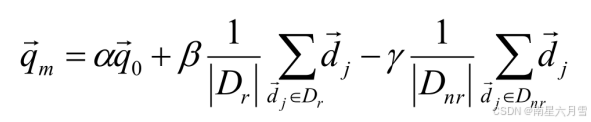
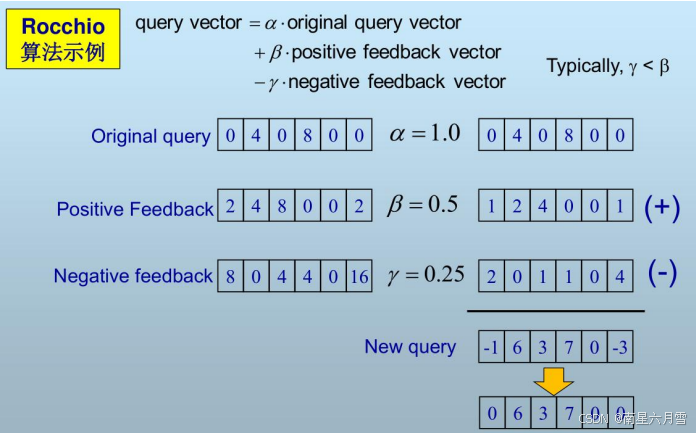
其中,Dr为已知相关文档的向量集合,Dnr为已知不相关文档的向量集合。q0为初始查询向量。α、β、γ为权重,根据手工调节或经验设定。由此,新的查询向量将逐渐向相关文档向量移动,远离不相关文档向量。举个例子:
二、文档表征技术初阶
2.1 TF-IDF 技术的局限性
使用 tf-idf 来表示词项简单快速而且容易理解,但是这仅以 “词频” 度量词的重要性,无法体现词项之间的关联关系。
尽管共现矩阵可以描述关联关系,但缺陷也是明显的。
- 问题1:数据规模过大,存储以及处理困难。降维会导致原有的词项与矩阵一一对应关系被破坏。
- 问题2:无法体现词项的位置信息以及词项与上下文的关系。位置关系可以引入拓展倒排表加以解决,但比较复杂。
因此,我们需要一种能够表示出文本上下文关系的词项表示方法。
2.2 描述词项之间的语义关联
Word2vec模型的出现:直接面向文本序列进行建模。它一般有两种设计思路:
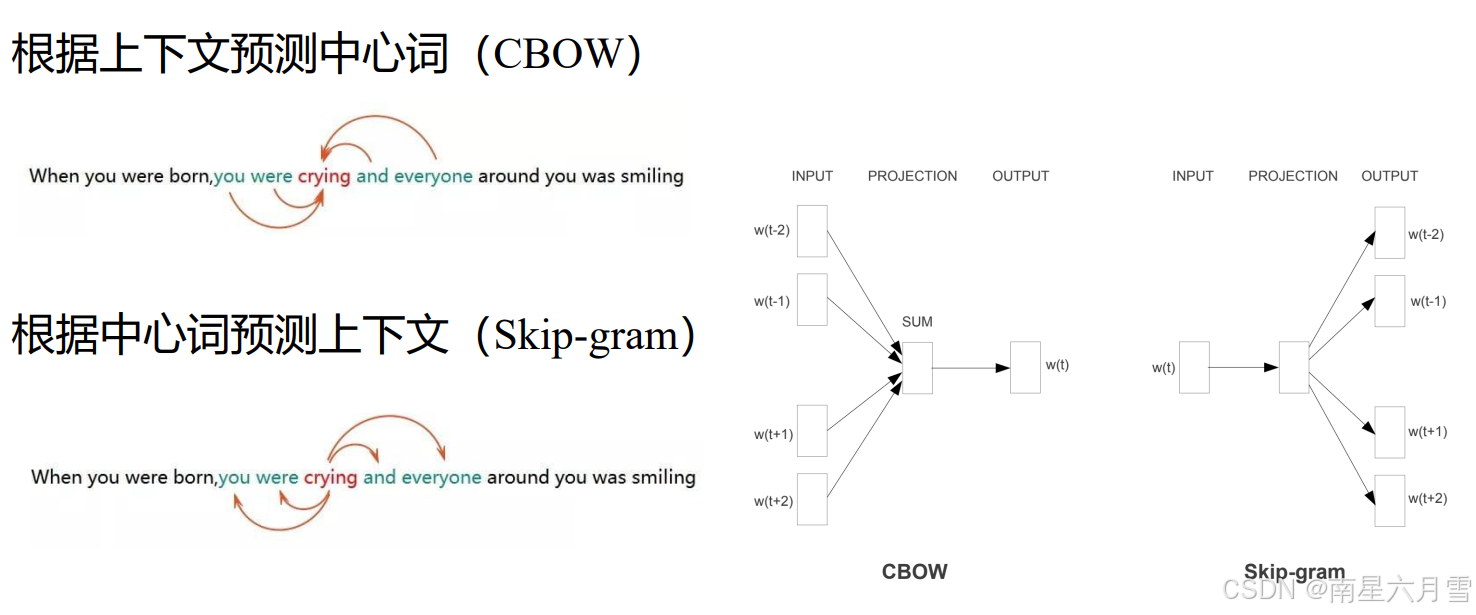
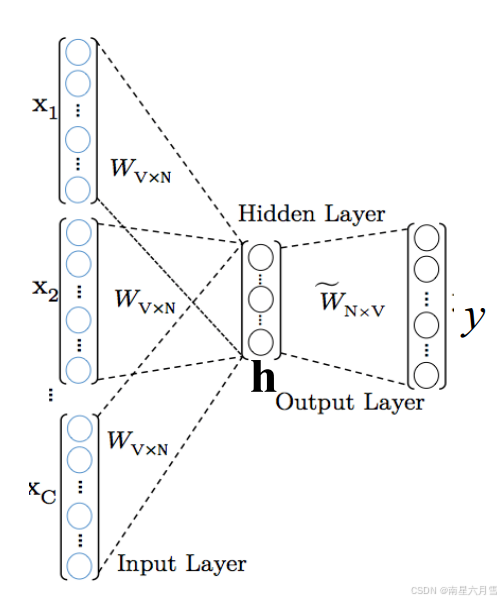
它的基本流程基于深度学习,用独热向量表示词项,用加权矩阵和平均值来计算隐藏层,再计算预测的中心词的概率,根据交叉熵损失,反向传播优化模型。最终基于多个不同滑动窗口进行多次训练,最终得到各个词项的表征。
从性能上说
- CBOW模型仅预测中心词,复杂度约为O(V),即词表规模
- 而Skip-gram模型基于中心词预测周边词,复杂度约为O(KV),即考虑窗口
从效果上说
- 在Skip-gram模型中,由于每个词都可以作为中心,都将得到针对性训练
- 因此,对于生僻词(数据稀疏)的训练而言, Skip-gram模型效果更好
这种方法有效表征了词项之间的上下文关系,无监督,通用性强,可适用于各种NLP任务。但是,无法解决一词多义的问题,例如play music 和 play football。同时,Word2vec 是一种静态的方式,其词项表征一旦训练确定就不会再做更改。 因此,虽然通用性强,但是无法针对特定任务进行动态优化。
三、预训练模型初阶
3.1 Transformer 技术
文档表征技术近年来有了长足进步,但语料的 飞速积累,导致大部分人难以充分学习利用。因此,现在的主流方向是通过大规模的数据和模型,学习语料库中的知识,然后将这些知识迁移到某一个具体的任务中,从而获得较好的表现。
Transformer 在学习词表征得同时学习位置表征。基于位置信息表征,既可以更好地适应较长文本,也可以有效学习词项之间的相对位置关系。它的核心思想是使用注意力机制捕获序列的全局信息,解决长距离依赖问题。
Transformers Explained Visually:https://towardsdatascience.com/transformers-explainedvisually-part-1-overview-of-functionality-95a6dd460452
3.2 如何训练 BERT 模型
Bert预训练方法与 Word2Vec 类似。


预训练模型与word2vec的区别与联系在于同样是在语料库中进行训练,但是把任务改成了难度更大的形式,比如:完形填空,句子顺序预测。预训练模型使用上游预训练和下游微调的范式,使模型得以运用于更广泛的场景。
它的优点在于充分利用了大量的无标签数据,将开放世界的知识应用于下游任务中,从而大幅提高模型效果,针对具体的任务,可以直接使用已经开源预训练好的模型,而且能够得到非常好的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









