



引言:
在人工智能的广阔天地里,大模型的构建与训练始终占据着核心位置。观察细致的朋友或许会留意到,大模型的训练过程往往被精心划分为预训练和微调两大环节。这背后究竟蕴藏着怎样的考量?今日,就让我们一同探究其缘由。
一、预训练与微调的定义及作用
- 预训练探秘
预训练,简而言之,就是利用庞大的未标注数据集对模型进行初步锤炼,使其能够捕捉到普遍存在的知识框架和模式。这些数据源广泛涉猎书籍、文章、网页等多个维度,覆盖了丰富的领域和语言构造。经过预训练,模型能够深刻理解语言的内在逻辑,如词汇间的语义联系、句子的结构规律,以及在不同情境下的通用表达模式和上下文关联。 - 微调的艺术
微调,则是在预训练成果的基础上,通过引入少量但高度针对性的标注数据,对模型进行精细化调整,以使其更好地适应特定任务或领域的需求。这些标注数据与目标任务紧密相连,比如情感倾向分析、语言翻译、法律文书的智能理解等。微调的过程,就是让模型在已有广泛知识的基础上,更加精准地聚焦到特定场景或任务上,从而提升其执行效率与准确性。
这一训练策略,不仅赋予了模型更强的泛化能力,还极大地削减了训练所需的成本。
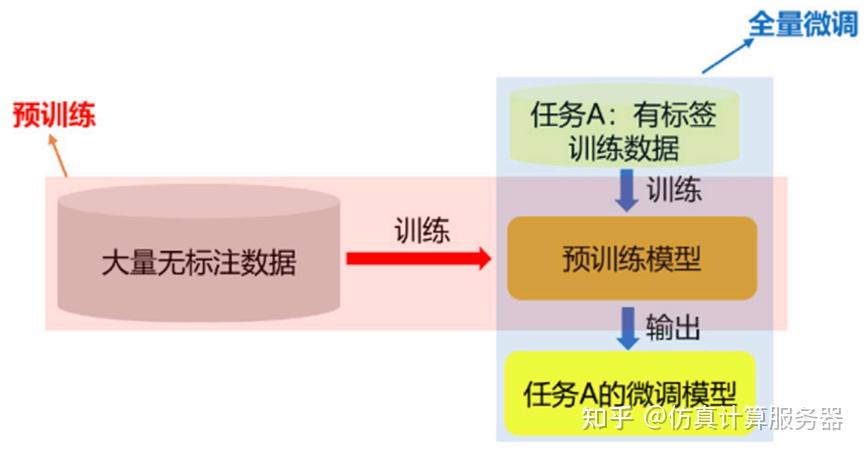
二、泛化能力的飞跃
- 泛化能力解析
泛化能力,是衡量模型能否将所学知识和模式有效应用于新数据、新任务或新环境中的关键指标。它体现了模型面对未知情境时,仍能做出合理判断、预测或生成恰当内容的能力。 - 预训练与微调如何携手提升泛化力
- 预训练阶段:通过吸纳多元化的海量数据,模型得以掌握语言的根本规律,这如同为模型打造了一个坚实的知识基石,使其对世界有了更为全面的认知。
- 微调阶段:在预训练的基础上,针对特定任务进行精细化调校。利用与目标任务紧密相关的少量高质量标注数据,使模型能够更精准地贴合特定场景或任务的需求,从而在特定领域内展现出更加卓越的性能。
三、训练成本的显著降低
- 预训练:一次投入,长期受益
尽管预训练阶段需要投入大量的计算资源和数据,但其带来的益处却是长远的:
- 通用知识的积累:预训练模型通过海量数据学习到通用特征,这些知识可以轻松迁移到多种任务中,避免了为每项任务单独训练模型的高昂成本。
- 模型的广泛复用:预训练模型作为通用基础模型,可被多个任务和开发者共享。例如,Meta的LLama系列、阿里的通义千问等,已在众多下游任务中展现出强大的应用价值,极大地降低了重复训练的成本。
- 微调:低成本,高效率
微调阶段的成本相较于从头训练模型要低得多:
- 数据的高效利用:微调仅需少量标注数据,可能仅占预训练数据量的千分之一甚至更少,大大减轻了数据收集和标注的负担。
- 计算的经济性:微调过程仅涉及对部分模型参数或少量训练步骤的调整,所需的计算资源远低于预训练。例如,对百亿参数模型的微调可能仅需数小时至数天即可完成,而预训练则可能需要数周乃至数月的时间。
四、结语
预训练与微调相结合的训练方式,不仅极大地提升了大模型的泛化能力,还显著增强了其实际应用价值。预训练为模型奠定了广泛的知识基础,而微调则使模型能够针对特定需求进行精细化优化,从而在众多任务和领域中展现出高效、稳定的性能。这一训练策略,无疑是大模型取得成功的关键要素之一。
通过这种巧妙的设计,大模型既保持了广泛的通用性,又具备了强大的特定任务适应能力,真正实现了“广度”与“深度”的完美融合。

















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









