




一. 模型规格与内存需求对照表
1.1 CPU模式下的内存需求(FP32)
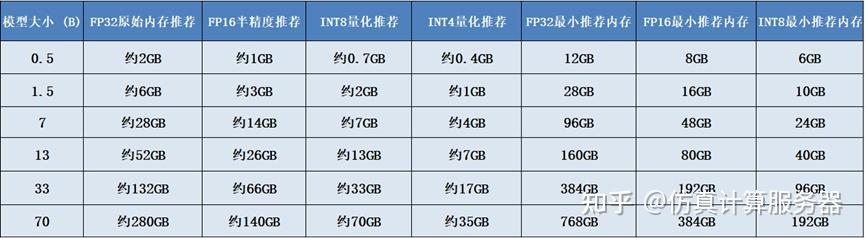
*最小推荐内存基于相应精度计算,包含工作内存和系统预留 **最小推荐内存(FP32)基于全量参数计算,包含工作内存和系统预留
1.2 GPU显存需求(使用CUDA)
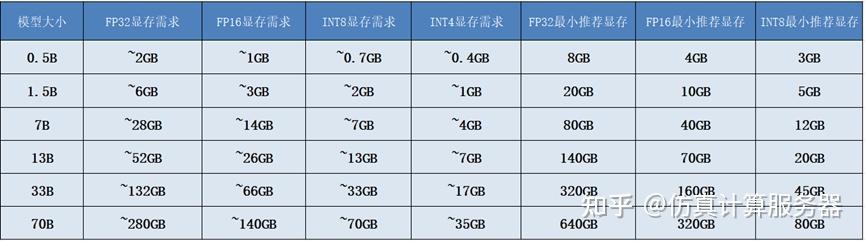
*最小推荐显存基于相应精度计算,包含CUDA开销和工作内存 **最小推荐显存(FP32)基于全量参数计算,包含CUDA开销和工作内存
1.3 内存与显存估算方法
CPU环境下的内存估算
在CPU运算场景下,为确保系统稳定运行,我们推荐采用以下公式来估算所需的最小内存:
推荐内存 = (基础模型内存 + 运算内存 + 系统预留内存) × 1.2
其中,运算内存涵盖了KV Cache(键值缓存)、激活值以及临时计算所需的空间,具体估算方式如下:
- KV Cache:大致等于2乘以网络层数、批次大小、序列长度、隐藏层大小以及每个元素的字节数。
- 激活值:与网络层数、批次大小、序列长度、隐藏层大小及每个元素的字节数成正比。
- 每个元素的字节数:在32位浮点数(FP32)精度下为4字节,16位浮点数(FP16)精度下为2字节。
- 系统预留内存:建议预留基础模型内存的50%以供操作系统和其他应用程序使用。
GPU环境下的显存估算
对于GPU运算,我们推荐使用以下公式来估算所需的最小显存:
推荐显存 = (基础模型显存 + CUDA开销 + 运算显存) × 1.2
其中,CUDA开销通常为基础模型显存的15%,运算显存则包括KV Cache、激活值以及CUDA缓存,每个元素的字节数同样取决于所选精度。
注意事项:
- 上述估算基于标准配置(批次大小为1,序列长度为2048)。
- 实际应用时,可能需要根据具体场景进行调整。
- 估算值已考虑1.2的安全系数,以确保系统稳定运行。
- FP32精度常用于研究领域,而FP16则是GPU推理的优选。
- 在生产环境中,推荐使用INT8或更低精度的量化方案以节省资源。
二、不同精度与量化方案对比
- FP32:提供最高精度,但内存占用最大,适用于对精度要求极高的研究领域。
- FP16:在保持较高精度的同时,内存占用减半,是GPU推理的理想选择。
- INT8:中等精度,内存占用仅为FP32的25%,适用于生产环境中的推理任务。
- INT4:精度较低,但内存占用仅为FP32的12.5%,非常适合资源受限的设备,如移动设备。
三、硬件配置建议
消费级硬件:
- 8GB显存GPU:适用于运行小型至中型模型(INT8/INT4),适合小型AI应用开发。
- 16GB显存GPU:可运行最大至7B的模型(INT8),适用于中型AI应用开发。
- 24GB显存GPU:支持运行最大至13B的模型(INT8),满足大多数AI应用开发需求。
专业级硬件:
- 32GB显存GPU:适合运行大型模型(INT8),适用于研究和开发任务。
- 48GB及以上显存GPU:能够运行70B及更大规模的模型,满足大规模AI研究需求。
四、使用建议
- 量化方案选择:优先考虑INT8量化以平衡内存和性能,资源极度受限时选择INT4,资源充足时则可采用FP16。
- 实践建议:确保为操作系统和其他程序预留足够的内存,考虑批次大小对内存的影响,监控模型加载和推理时的内存峰值,并在生产环境中进行充分的性能测试。
五、常见问题解决
- 内存不足:尝试使用更高级别的量化方案、减小批次大小、利用梯度检查点(训练时)或考虑使用更小的模型。
- 性能优化:选择合适的批次大小、启用CUDA优化、采用合适的量化方案并优化输入序列长度。

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









