



MindsDB是开源的AI数据统一访问引擎,作为"智能数据层"连接多种数据源与AI应用。它支持跨多数据源的统一查询,并能集成AI模型赋能数据查询,使预测、摘要、情感分析等AI功能如同查询普通表一样便捷。通过SQL即可实现模型与数据的无缝融合,大大简化了企业级AI应用的数据访问路径。
前几天我们提到企业AI数据环境的复杂性,远非单一的向量库能胜任。大型企业的数据"散落”在大量的RDBMS、文档、SaaS甚至邮件中。未来企业AI应用的数据访问一定会体现两大最重要的特征:融合与智能。

本篇为大家实测MindsDB这款开源的AI数据统一访问引擎,以了解它是如何在数据不离开源头的前提下,给上层应用提供一种融合与智能的数据访问方式。:
- MindsDB初探、安装与启动
- 一:跨多数据源的统一查询
- 二:AI模型赋能数据查询
- 三:知识库与混合检索的应用
- 四:构建智能的Data Agent
- 结束语:MindsDB的应用总结
01
MindsDB初探、安装与启动
MindsDB不是一个随着大模型(LLM)才出现的项目,最开始它为跨源的机器学习而设计,但随着LLM的出现而发生进化。简单的说,目前的MindsDB是:

一个跨多数据源(数据库、文件、应用等)、支持多AI模型(传统ML/LLM模型、嵌入模型)的统一数据连接、查询与智能应用的"中间件”。

【平台架构】
我们将MindsDB的架构表示如下:
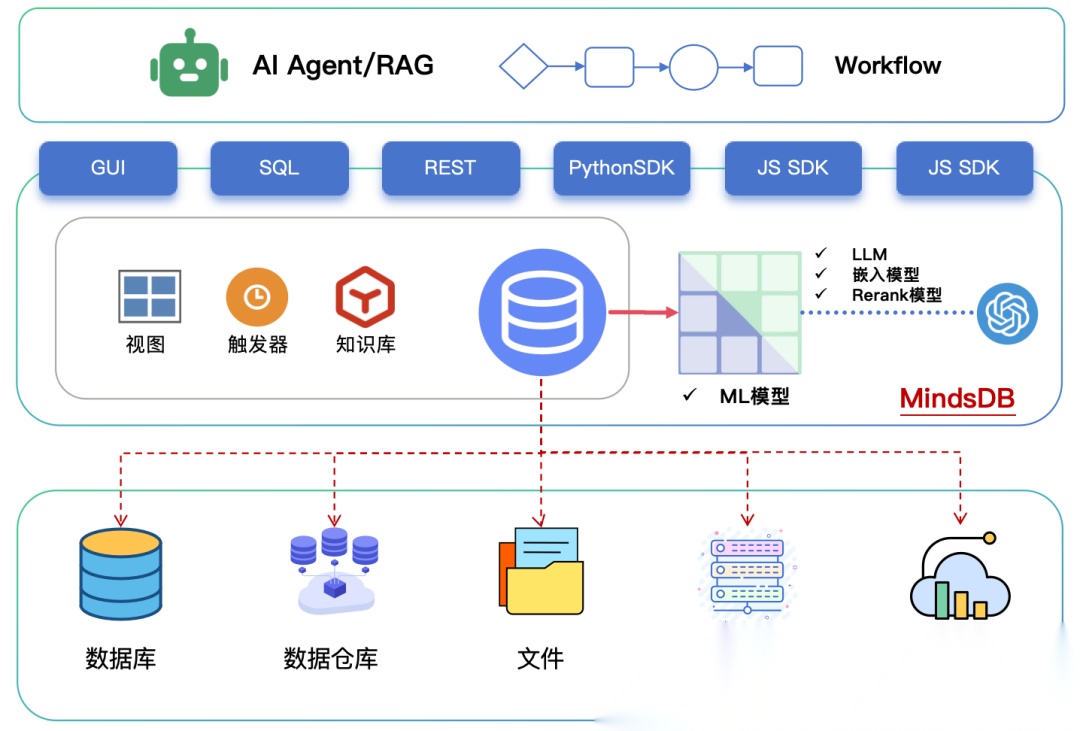
可以把MindsDB比作一个在数据源与AI应用之间的“智能数据层”:
-
对下层(数据源):通过可插拔的大量连接器对接各种异构数据源,可以是各种数据库/仓库、文件、向量库、SaaS应用等。
-
对上层(AI应用):提供统一的SQL、SDK、REST、MCP多种API,以实现统一查询、混合检索、智能分析、Data Agent等。
而MindsDB本身除了协调各个数据源的查询并汇总结果外,更重要的是:集成大量机器学习引擎(包括LLM),通过AI模型给数据查询注入AI能力。
什么意思呢?比如下面这些需要一点”AI“的查询:
-
在查询客户信息时,同步检索出这个客户的“流失概率”
-
在查询文章内容时,实时总结出这篇文章的“摘要信息”
-
在插入某段文本时,同时抽取其“结构化信息”插入到某个表
此外,MindsDB还支持一些在中间层进行数据联合(Unify)、同步、智能响应的有趣特性。
下面通过实例来探究MindsDB的用法与强大,首先进行安装并启动MindsDB Server。
【安装与启动】
最快速启动MindsDB的方式是Docker(具体请参考Github)。本着探索的精神,我们则用源码启动:
#创建虚拟环境(macos)
python -m venv mindsdb-venv
source mindsdb-venv/bin/activate
#安装依赖
pip install -e .
python -m mindsdb --config ./config.json
这里使用了config.json进行启动(建议你也这么做),其中的一些重点:
-
path:root字段为MindsDB自身的存储目录,可自行设置;
-
api:对MindsDB需要启动的API接口做配置。MindsDB会在不同端口启动不同的API接口,比如HTTP接口在47334(REST访问与GUI);MySQL接口在47335(MySQL客户端访问);MCP Server在47337(MCP协议访问)等;
-
default_llm:**默认LLM模型,支持Ollama。注意国内模型用OpenAI兼容接口,需要设置baseurl。举例:
"default_llm": {
"provider": "openai",
"model_name" : "gpt-4o-mini",
"base_url":"<官方url或第三方平台url>",
"api_key": "<你的API Key>"
},
 踩坑:为了让MindsDB能够成功通过OpenAI SDK访问其他模型,注意在代码中搜索CHATMODELSPREFIXES设置,把对应模型的前缀加进去。
踩坑:为了让MindsDB能够成功通过OpenAI SDK访问其他模型,注意在代码中搜索CHATMODELSPREFIXES设置,把对应模型的前缀加进去。
-
default_*embedding_*model:默认的嵌入模型,与default_llm类似
-
default_*reranking_*model:默认的rerank模型,与default_llm类似
启动成功后,访问http://127.0.0.1:47334/,看到GUI后代表成功:
02
跨多数据源的统一查询
MindsDB最核心的两类集成能力是数据源与AI模型(通过对应的handler/引擎来连接)。本节先看前一类:数据源集成。
MindsDB中连接并访问外部数据源的方式为:
通过SQL声明式的连接外部数据源,将其注册成MindsDB的“虚拟数据库”。
我们看几种最主要的数据源。
【关系型数据库(RDBMS)】
最常见的数据源是企业中的各种RDBMS。我们在本地启动一个Postgres测试数据库来模拟,并生成一些数据。
现在进入MindsDB的GUI,执行如下”MindsDB风格“的SQL:
CREATE DATABASE my_postgres
WITH ENGINE = 'postgres',
PARAMETERS = {
"host": "127.0.0.1",
"port": 5432,
"database": "mindsdb",
"user": "postgres",
"schema": "public",
"password": "yourpassword"
};
非常直观。Parameters是连接源库的参数,with engine则指定连接引擎是postgres。这就把一个Postgres库”映射“成了名字叫做my_postgres的虚拟库。
对RDBMS来说,这里遵循的映射规则是:
- 虚拟数据库中的表名、字段与源数据库一一对应
注意,虚拟库并不真实存在。所以你无需考虑数据同步等问题。现在你可以通过SHOW TABLES FROM查看库中的表清单,并对其查询。比如:
select * from my_postgres(select * from products limit5)
--或者
select * from my_postgres.products limit5
对于使用者来说,好像是在查询本地表,但其实数据仍然在Postgres里,由MindsDB将SQL转译并下推给Postgres执行,整个过程对用户透明。
你也可以通过这个映射的”虚拟库”直接创建表和数据:
create table my_postgres.demo (
id integer primary key,
content varchar(50)
)
insert into my_postgres.demo values(1,'demo')
一切都和你直接操作源库类似(注:MindsDB风格的SQL语法基本遵循MySQL与PostgreSQL),但这里创建的表和数据实际上都会被“推”到源数据库。
【文件】
另一种常见的数据源是文件,MindsDB直接支持的文件类型为TXT/PDF/Excel/CSV/JSON等。对于文件的映射规则是:
-
虚拟数据库的名字固定为“files”
-
表名则是你上传文件的时候设置的名称
对不同的文件类型,MindsDB会用不同的方式将其映射成“表”:
-
对于CSV/Excel:直接将电子表格映射成Table,字段与表头对应
-
对于TXT/PDF:会进行内容分割后映射成content与metadata两列
-
JSON文件:如果可以,将被转化为Table;否则与TXT处理方式一致
现在通过MindsDB的GUI上传几个测试文件:
然后你就可以向查询表一样查询这个“文件”。比如:
SELECT * FROM files.test_questions;
如果源文件是TXT或PDF的非结构化文件,查询结果可能像这样:

正如上文所说,文件会被拆成多行放在content字段中。
【向量数据库】
AI时代自然不能缺少向量库,MindsDB支持常见的向量库。向量库到虚拟数据库中的映射规则根据不同的向量库有所不同。
以ChromDB为例:
-
映射的表名为对应的Chroma中的collection名称
-
字段则统一为id、embeddings、metadata、content、distance
让我们找一个RAG应用中的Chroma向量库映射过来:
--创建chroma虚拟数据库映射
CREATE DATABASE my_chromadb
WITH ENGINE = 'chromadb'
PARAMETERS = {
"persist_directory": "./chromadata",
"distance": "cosine"
}
然后就可以直接查询这个向量库的某个collection,就像查一个普通表:
select embeddings,content,metadata
from my_chromadb.vectorindex
你将会直接看到向量、对应的内容和元数据的输出。
向量库的插入与有条件检索需要用到嵌入模型,将在下一节讲解。
【跨源联合查询】
连接多个数据源后,MindsDB的强大之处在于可以直接用SQL对不同来源的数据进行JOIN和联合查询。
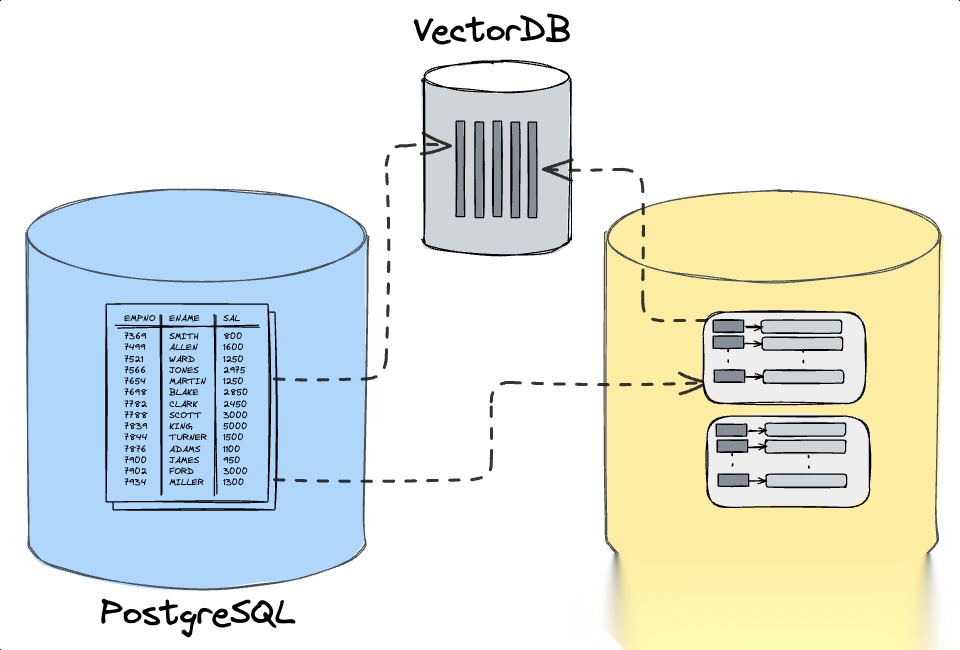
比如你的orders表在Postgres,客户行为日志存储在MongoDB中,你可以在MindsDB中写一个跨库JOIN,将两者关联分析而无需要任何ETL流程!MindsDB会将查询拆分给Postgres和Mongo分别执行,然后在内部完成结果拼接,最终把融合后的结果集返回。


需要注意的是,MindsDB尽量将过滤、聚合等操作下推到各自的数据源,但最终的跨库结合部分会在MindsDB层完成,因此对于超大数据集的跨源操作需要谨慎设计过滤条件。

03
AI模型赋能数据查询
接着来看MindsDB的第二大核心集成能力:AI模型。
如果说MindsDB的数据源集成解决的是”找齐数据并统一访问”的问题,那么模型集成的目的是让数据更聪明。
MindsDB通过一种“AI Table”的模式将AI模型融入数据库查询,使AI预测和分析如同查询一个表一样方便 。
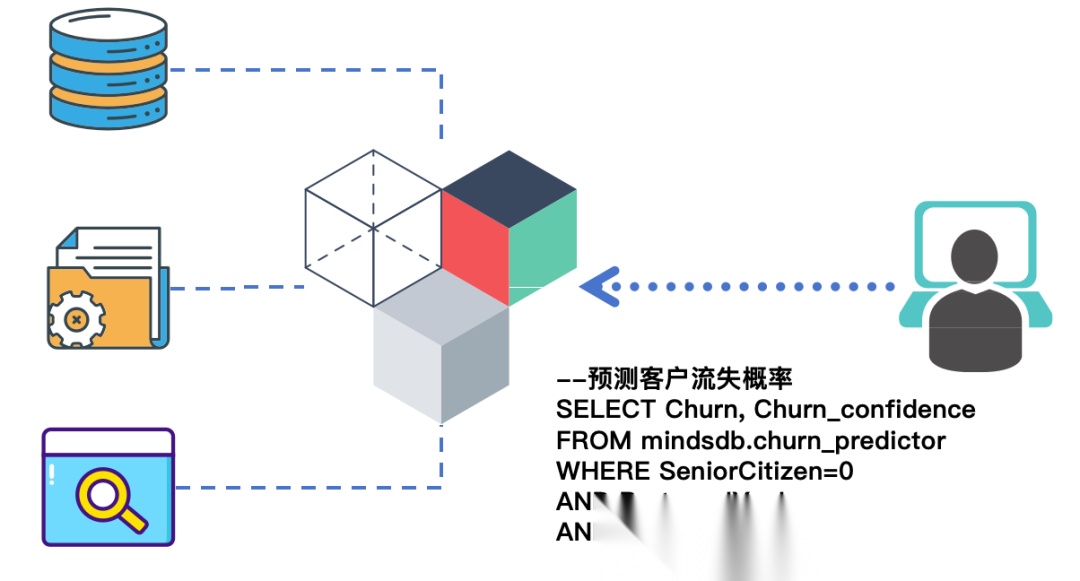
现在来看如何利用MindsDB的模型能力,创建、训练与调用模型,让查询注入AI能力。注意,大模型(LLM)也只是AI模型的一种,它的区别在于不需要基于MindsDB的数据源做训练。
【传统机器学习模型】
先看传统的机器学习(ML)模型,通常包括各种回归、分类、时间序列等模型。以一个简单的预测客户流失概率的分类模型举例。
比如,有一张客户流失历史数据表customers_churn在Postgres里,包含客户诸多属性和是否已经流失的标签。我们希望训练一个模型预测新的客户是否可能流失,首先来训练这个预测模型:
CREATEMODEL mindsdb.customers_churn_predictor
FROM my_postgres(
SELECT * FROM customers_churn
)
PREDICT churn;
上述SQL会让MindsDB读取my*postgres.customers_*churn数据,并自动训练一个预测churn(流失)字段的模型。训练完成后,一个名为customers_*churn_*predictor的模型就出现在MindsDB的名为mindsdb的内部库中。
现在,你可以像查询表一样查询它,传入新的客户属性,获取预测结果:
SELECT churn, churn_confidence, churn_explain
FROM mindsdb.customers_churn_predictor
WHERE SeniorCitizen=0
AND Partner='Yes'AND Dependents='No'
AND tenure=1AND PhoneService='No'
... -- 省略若干客户条件;
返回结果中包含模型预测的churn(是否流失),以及churn_*confidence置信度和churn_*explain解释信息等。MindsDB自动提供了预测的可信度和特征重要性等解释性输出,方便我们理解模型判断依据。
可以看到,这里既不需要模型开发与调用代码,也不需要把数据导出到外部工具,一切用SQL完成。
这种“AI Table”的方式还有个好处是:你甚至可以把模型“表”和数据表做JOIN,实现批量调用,比如批量预测一批客户的流失概率。你将在下面的大模型部分看到这一点。
【大语言模型(LLM)】
MindsDB将LLM视作特殊的AI引擎(无需训练),可以通过配置API密钥等参数,也将其包装为MindsDB中的模型“表”。
我们创建一个用来回答问题的模型:
CREATEMODEL my_llm_openai_answer
PREDICT answer
USING
engine = 'openai',
model_name = 'gpt-4o-mini',
api_base = 'https://api.openai.com/v1',
openai_api_key = '<你的OpenAI密钥>',
prompt_template = '回答问题:{{question}}',max_tokens=8000
;
你可以替换成任意兼容OpenAI API接口的模型,如果配置正常,现在就得到了一个模型“表”,查询它:
SELECT answer
FROM my_llm_openai_answer
WHERE question = '你好,能简单介绍一下MindsDB吗?'
MindsDB会把question字段的内容插入到提示模板中调用模型,并将返回的回答作为answer字段输出(字段在创建时定义)。这种方式让我们用SQL就调用了LLM,而无需单独编写API代码。
巧妙的是,你可以把LLM模型”表“与数据表JOIN,实现更智能的查询。
我们现在创建一个生成摘要的模型:
CREATEMODEL my_llm_openai_summary
PREDICT summary
USING
engine = 'openai',
model_name = 'gpt-4o-mini',
openai_api_key = '<API密钥>',
prompt_template = '请将以下内容概括为简短摘要:{{text}}'
;
现在将前面创建的Postgres数据库中的产品描述数据批量”喂“给它,让AI生成每个产品的描述摘要:
SELECT p.product_id, s.summary
FROM my_postgres(
SELECT product_id, description AStext
FROM products
WHERE product_id BETWEEN1AND3
) AS p
JOIN my_llm_openai_summary AS s;
这里通过JOIN操作将Postgres库中表的描述字段description发送给摘要模型(注意要as text,因为模型定义的条件字段是text),模型输出的summary再与原产品ID一起返回,从而实现了批量生成,真正实现了“让SQL更智能”。
再创建一个用来情感检测的LLM模型:
CREATEMODEL my_llm_qwen_sentiment
PREDICT sentiment
USING
engine = 'openai',
model_name = 'qwen-plus',
api_base = 'https://dashscope.aliyuncs.com/compatible-mode/v1',
openai_api_key = '<API-Key>',
prompt_template = '请将下面客服评论内容判断为 好评、中性 或 差评:{{review}}'
;
把上面Postgres库中的订单评价信息批量“送入”这个模型:
SELECT o.order_id, o.product_id, o.review, s.sentiment
FROM my_postgres(
SELECT order_id, product_id, review
FROM order_items
LIMIT5
) AS o
JOIN my_llm_qwen_sentiment AS s;
你就可以轻松的得到所有评价的情感分类结果:

【嵌入模型】
嵌入模型在生成式AI中用于将输入转化为向量表示,从而实现语义检索。同其他模型一样,你也可以得到一个嵌入模型”表“,并对其进行查询。
首先创建一个嵌入模型”表“:
CREATEMODEL my_emb_openai
PREDICT embedding
USING
engine = 'openai',
model_name='text-embedding-3-small',
mode = 'embedding',
question_column = 'content'
...
这里仍然使用openai引擎,但是mode为embedding;输入为content,输出为embedding。
现在我们基于上一节创建的文件与向量数据库,用SQL快速生成向量索引:
create table my_chromadb.sales_questions
(
select m.embedding as embeddings,f.content,f.metadata
from files.sales_questions f join my_emb_openai m
)
这里把“files”这个数据库中的sales_*questions文件“表”与my_*emb_*openai这个模型”表“进行JOIN,Mindsdb会自动发现两者匹配的”字段“content,并生成向量,然后直接在“my_*chromadb"这个库中创建向量”表“(注意字段名称是强制的),这样就完成了一个向量索引的过程!
基于这个新生成的向量”表“,借助向量模型就可以做语义检索:
select content
from my_chromadb.sales_questions
where embeddings =
(select embedding from my_emb_openai where content = '...')
注意这里的”=“并非绝对相等,仅仅代表语义相似。
你会看到类似如下的结果,而且会输出distance(代表相似度):

综合以上例子,我们通过几个简单的SQL就把文件进行了拆分、向量化、插入向量库,并可以语义检索。这实际上就是RAG在Index阶段的基本原理。但不同的是,这里全部是用SQL完成的。
可以看到,不管底层使用的是自训练ML模型还是外部的LLM,MindsDB都将其统一为SQL可查询的表接口,实现了模型与数据的无缝融合。通过这种方式,许多复杂的AI数据任务会变得更轻松,大大缩短了从数据到AI应用的路径。

本篇就到这里。
下篇我们继续介绍与演示MindsDB的两个高级特性:
-
用于更智能的组织多源信息的知识库(Knowledge Base)
-
用于实现自然语言访问统一数据的智能体(Data Agent)
如果你也想系统学习AI大模型技术,想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习*_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









