





 本文探讨了B树和B+树的数据存储机制,包括block地址计算、索引结构、数据组织方式(m-way search tree)、自组织索引与稀疏索引。重点讲解了B树的分裂与生长规则,以及B+树的特殊设计——仅叶节点包含指针。通过实例演示了如何利用这些数据结构提高数据访问效率和自动管理索引。
本文探讨了B树和B+树的数据存储机制,包括block地址计算、索引结构、数据组织方式(m-way search tree)、自组织索引与稀疏索引。重点讲解了B树的分裂与生长规则,以及B+树的特殊设计——仅叶节点包含指针。通过实例演示了如何利用这些数据结构提高数据访问效率和自动管理索引。
B树和B+树
数据存储
block address = track number + sector number
block size (512B)
硬盘索引数据 ->索引表-> 数据表 -> 硬盘数据位置
每行数据128bites, 则每个block 存储 4条数据
使用索引,每行数据用16字节索引指向,每个block 存储 32. 个数据的地址信息。
数据继续增加,为索引表继续创建索引表,稀疏索引
每个高级索引16字节,指向32个低级索引所在的block。
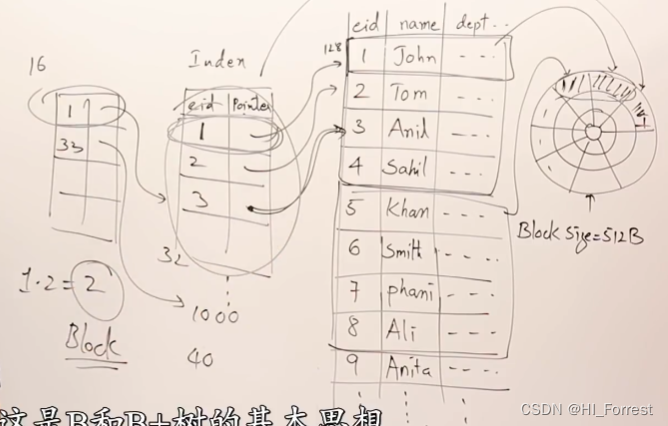
多级索引将降低需要访问的block的数量。
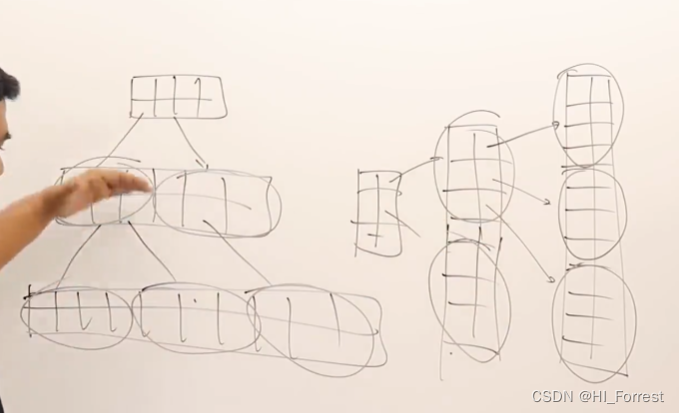
self-manage high level indexes 自组织的高级索引。
自动创建和删除高级索引。
m-way search tree
binary search tree:BST:
二叉树,每个节点有两个子节点,节点只有一个数值,比父节点小的是左下子节点,比父节点大的是右下子节点,每次比较的结果是二选一向下一级寻找。
3叉树:每个节点有两个数值,有三个子节点,根据数据与父节点中两个数据的比较划分的三个区间,确定向下一级的三个子节点。
m叉树:每个节点有m-1个数值,可以划分出 m个区间,对应下一级有m个子节点,每次向下一级可以有m个选择,m个数据范围。
m是节点的数目,m-1 是键的数目,也叫节点的度。

键(节点存储的索引值)同时也指向索引表的某位置,带有指针。
B 树
m-way search tree + 规则
- 每个节点需要有 m/2个子节点(m/2-1 个键(进位))之后
- 根节点需要有至少2个子节点(1个键)
- 所有叶子节点在同一级别
- 自下而上创建树 from bottom up
例子:m=4, keys = 10, 20, 40 , 50
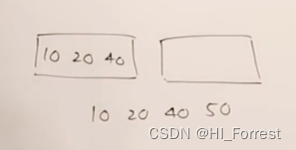
split 拆分节点,向上生长。
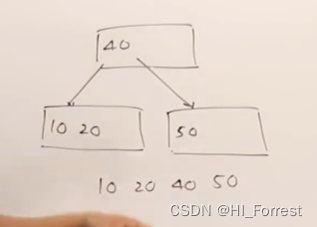
继续加入,继续split,中间点向上移动(自定哪个向上)
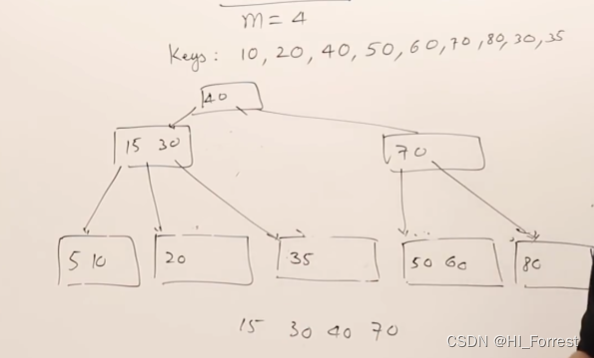
B+ 树
不是每个节点都有指针,只有叶子节点leaf nodes 有指针,叶子节点连接形成链表。
非叶子节点的键会在叶子节点上生成副本,副本后有指针,保证树中所有索引值都有指针指向其地址。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









