




 本文介绍了如何使用Pandas进行数据处理,包括删除重复行和映射操作。在删除重复行部分,讲解了利用`df.duplicated()`检查重复行和`drop_duplicates()`删除重复行的方法。在映射操作中,讨论了`replace()`、`map()`和`rename()`函数的用法,如替换元素、生成新列和替换索引等。
本文介绍了如何使用Pandas进行数据处理,包括删除重复行和映射操作。在删除重复行部分,讲解了利用`df.duplicated()`检查重复行和`drop_duplicates()`删除重复行的方法。在映射操作中,讨论了`replace()`、`map()`和`rename()`函数的用法,如替换元素、生成新列和替换索引等。
pandas数据处理之删重&映射
1、删除重复行
1) 检查
使用 df.duplicated()

df.duplicated()

这里第二行跟第一行重复,所以第二行是True
因为默认参数keep=“first”,从前往后判断,也可以改成“last”,从后往前判断
df.duplicated(keep='last')

可以在指定子集的列中判断是否重复

df.duplicated(subset=['A', 'B', 'C'])

小结:使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
2) 删重
使用drop_duplicates()函数删除重复的行
df.drop_duplicates(subset=['A', 'B', 'C'])

上图中把第二行删掉了
下面是骚操作:
1.先设定一个条件
cond = df.duplicated(subset=['A', 'B', 'C'])
cond

2.根据条件取数据
df[cond]

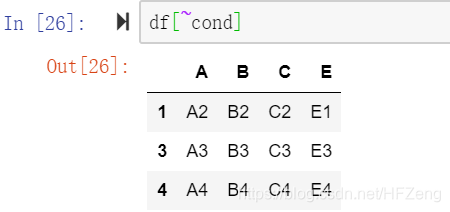
因为条件中第二行是True,所以取出来第二行
要是想取“除去第二行”的其他行数据,可以先进行取反操作
2种取反:
1.逻辑非取反
np.logical_not(cond)

2. 取反符号 ‘~’
df[~cond]
2. 映射
-
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
-
需要使用字典
-
包含三种操作:
replace()函数:替换元素
(最重要)map()函数:新建一列
rename()函数:替换索引
1)replace()
步骤:
-
先做一个映射字典
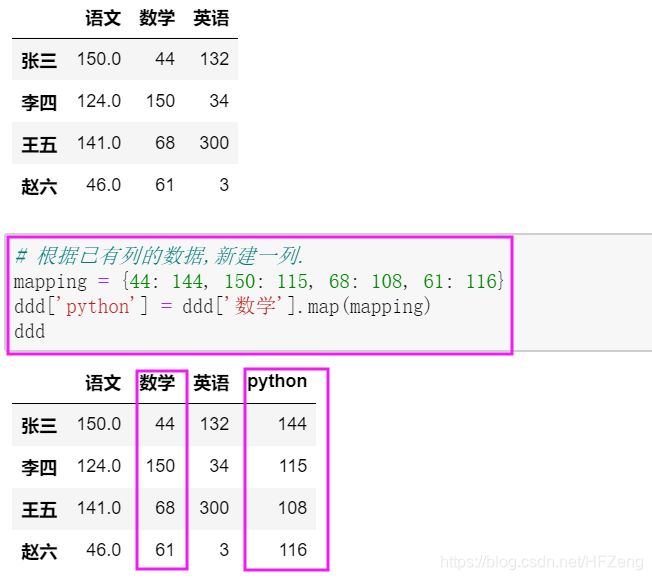
mapping = {13: 103, 3: 113, 34: 104, 44: 144, 46: 146} -
替换
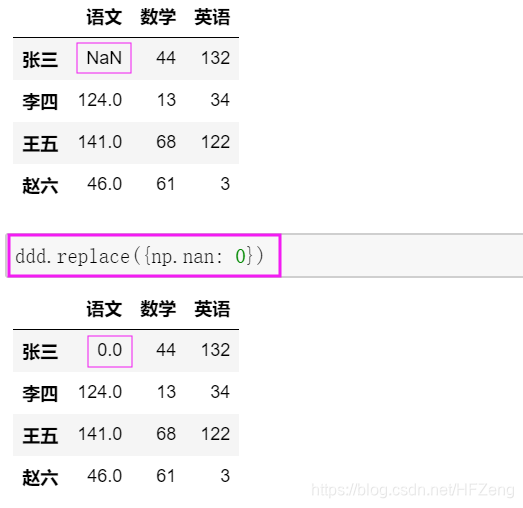
ddd.replace(mapping)

replace还经常用来替换NaN元素
2) map()函数
map()函数有四种用法:
-
根据已有列,生成一个新列(映射改数据)
-
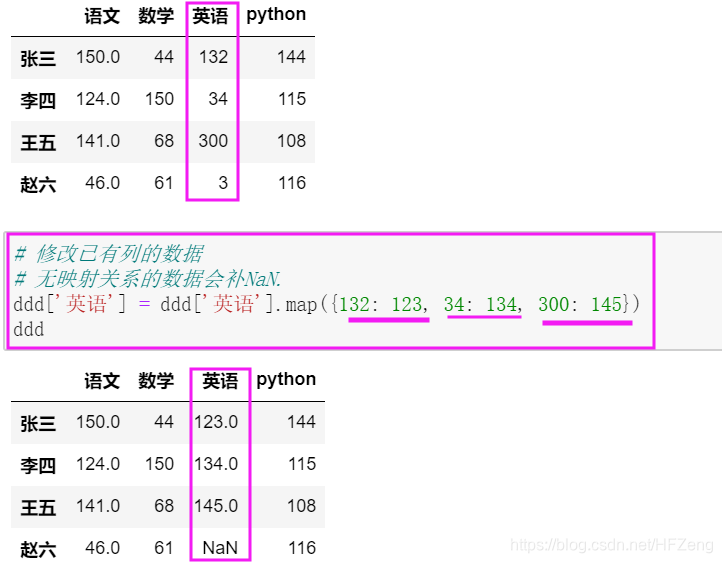
修改已有列的数据(若映射关系不全的数据会补NaN.)
-
map()中使用lambda函数
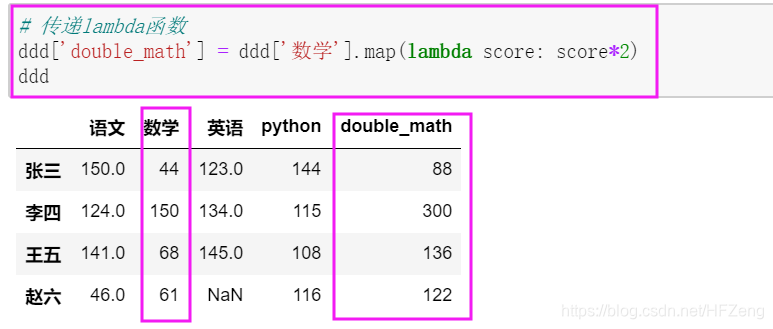
上面将“数学”这一列的数据通过lambda函数返回两倍的数值,新增一列“double_math” -
map()中可使用传“普通函数”
def convert(score): if score >= 120: return '优秀' elif score >= 90: return '及格' else: return '不及格' ddd['数学_score'] = ddd['数学'].map(convert) ddd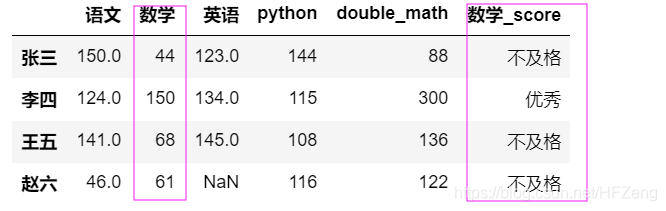
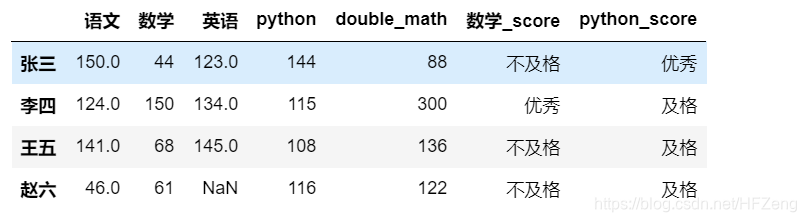
transform()和map()类似ddd['python_score'] = ddd['python'].transform(convert) ddd
- 区别:map()是一个个传值,transform()是一次过传值
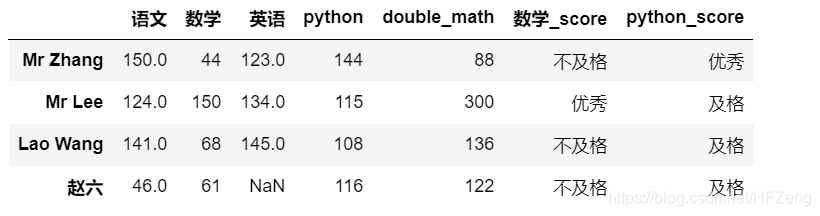
3) rename()函数
- 替换索引3种方法
-
index
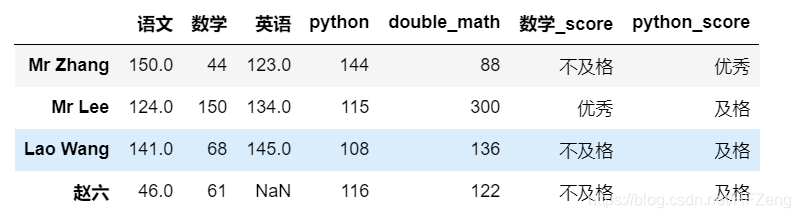
ddd.rename(index={'张三': 'Mr Zhang', '李四': 'Mr Lee', '王五': 'Lao Wang', })
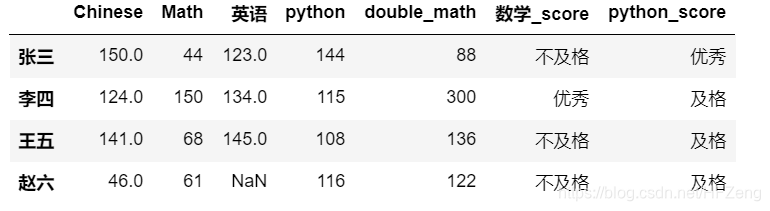
2. columns
ddd.rename(columns={'语文': 'Chinese', '数学': 'Math'})
3. 轴 axis
ddd.rename({'张三': 'Mr Zhang', '李四': 'Mr Lee', '王五': 'Lao Wang', }, axis=0)


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









